Le traitement informatique des documents en caractères non latins
Amélie Dupas
C’est à la suite d’un dess (Diplôme d’études supérieures spécialisées) « Traduction et documentation scientifiques » soutenu à l’université de Pau et des Pays de l’Adour, que m’a été confiée une étude, effectuée au Service commun de la documentation de l’université Jean Moulin-Lyon 3, sur le traitement informatique des documents en caractères non latins. La première partie concerne la solution mise en place par le scd Lyon 3, la deuxième celles mises en place ou envisagées par d’autres bibliothèques en France, la dernière concerne les solutions futures, notamment le système de codage Unicode 1.
Le scd Lyon 3
L’université Lyon 3 possède un fonds d’environ 9 000 ouvrages recensés en caractères non latins, constitué essentiellement à partir de dons et d’échanges. Les acquisitions concernent en particulier le russe, l’arabe, le chinois et le japonais. Ces quatre langues posent à elles seules tous les problèmes rencontrés pour les langues à caractères non latins : des caractères alphabétiques, des idéogrammes, le sens d’écriture.
Les responsables du scd ont imaginé une solution originale, adaptée aux outils informatiques dont ils disposent (siber), afin que ces ouvrages figurent enfin dans le catalogue : il s’agit de cataloguer les ouvrages en transcrivant les caractères originaux en caractères latins et lier par un lien hypertexte l’image numérisée de la page de titre et du sommaire à la notice de l’ouvrage.
Le système de documentation Geac/Advance étant paramétré pour utiliser le jeu de caractères latins étendu iso 5426, la solution de la romanisation s’est imposée. La notice romanisée est complétée par l’image numérisée de la page de titre et du sommaire grâce à la fonctionnalité multimédia du système d’information. Le lecteur peut ainsi vérifier si la notice qu’il a reçue en réponse à son interrogation correspond bien à son attente.
Un document interne a été rédigé à l’usage des catalogueurs, qui spécifie les normes ou les systèmes de romanisation à utiliser et indique les séquences de saisie des lettres spéciales et des diacritiques dans le système Geac/Advance.
Quelques solutions en France
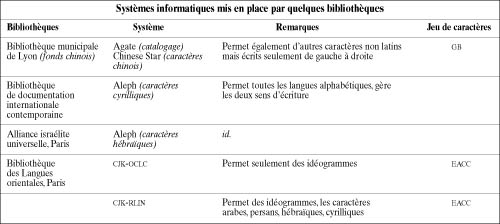
Beaucoup de bibliothèques confrontées à ce problème ont attendu le système de la BnF. Celui-ci n’étant malheureusement toujours pas en place, les bibliothèques commencent à mettre en œuvre des systèmes informatiques répondant à leurs besoins (voir tableau 1).
Le projet de la BnF est pourtant ambitieux. A la Bibliothèque nationale, les documents en caractères non latins étaient catalogués sur fiches papier en caractères originaux par un spécialiste de la langue. Seuls les documents ne relevant pas du Service des littératures orientales (slo) – les ouvrages reçus au titre du dépôt légal, les périodiques étrangers, les partitions musicales – étaient saisis romanisés dans la base bn-Opale. Créée en 1983, cette base contient tous les ouvrages en caractères latins, y compris les langues riches en diacritiques telles que le vietnamien. Les terminaux ont été configurés pour afficher ces signes.
L’ouverture de salles en libre accès à la BnF a nécessité l’introduction de tous les documents, même en caractères non latins, dans le catalogue pour en faciliter l’accès. En l’absence de possibilité de saisir les caractères originaux, la décision de cataloguer les ouvrages du slo en translittération ou romanisation sur le système informatique Geac/Ivry (ou Geac-Libre Accès) a été prise en janvier 1996. Les zones romanisées des notices ont été doublées pour obtenir plus tard en parallèle les zones en caractères originaux et leur romanisation.
Pour toutes les langues alphabétiques, des normes ou des systèmes de translittération réversibles ont été choisis pour retranslittérer automatiquement les notices en caractères originaux lorsque le nouveau système informatique sera mis en place. Pour les langues non alphabétiques (romanisation non réversible), le catalogage manuel en caractères originaux est poursuivi.
D’après le calendrier du projet, les deux bases actuelles, bn-Opale et Geac/la seront reversées en 1999 dans une base unique, le système d’information (si). Le catalogage des documents en caractères non latins sera poursuivi en romanisation, et, dans un deuxième temps, ces documents seront intégrés au système. Le catalogage dans la base si sera fait en caractères originaux et doublé par la romanisation, selon un calendrier de priorités : 1. alphabets arabe, cyrillique, hébraïque, grec ; 2. chinois, japonais, coréen ; 3. autres langues. Une des zones romanisées (doublées) des notices générées actuellement sera retranslittérée automatiquement pour les notices translittérées et retranscrite manuellement pour les notices transcrites de manière non réversible.
Le futur système d’information fonctionnera avec le système Unicode, évoqué plus loin, et les notices contiendront les données en caractères originaux et romanisées. Il utilisera le format intermarc intégré pour faciliter le codage des langues, zone par zone.
Vers une solution universelle ?
Le monde des bibliothèques se penche déjà depuis un certain temps sur le problème des documents en caractères non latins. L’ifla organise des conférences sur ce thème en marge de ses congrès. Six axes problématiques ou de réflexion ont été identifiés :
1. la prise de conscience et l’influence d’experts de pays à écriture non latine,
2. la normalisation des systèmes de transcription et l’application de ces normes,
3. la normalisation des jeux de caractères,
4. le tri et la récupération des notices,
5. l’ajustement des normes isbd et unimarc,
6. la motivation des concepteurs et diffuseurs d’applications informatiques.
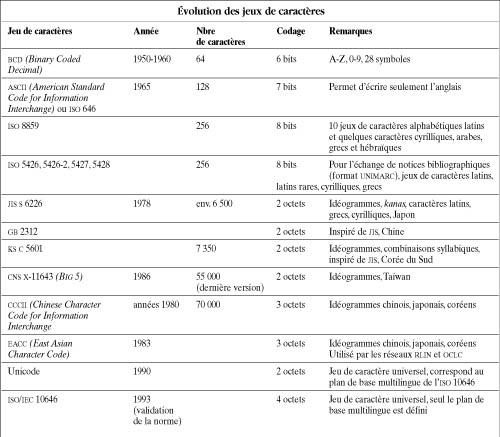
Tous ces sujets sont en pleine évolution, mais le plus brûlant est sans conteste la normalisation des jeux de caractères. Ceux-ci se sont développés en même temps que la puissance des ordinateurs. Le tableau 2 retrace leur évolution, de bcd (Binary Coded Decimal, décimal codé binaire), le premier jeu de caractères codé sur six bits, jusqu’aux jeux d’idéogrammes.
Deux projets de jeux de caractères universels ont commencé simultanément.
La norme iso/iec 10646-1 : 1993, intitulée Jeu de caractères universel codé sur plusieurs octets (Universal Character Set, ucs) a été approuvée en 1992 et publiée en 1993. Le codage des caractères est prévu sur quatre octets. Ce code s’insère donc dans un cadre à quatre dimensions. On peut se le représenter en imaginant une rue de 256 maisons, chaque maison comportant 256 niveaux, chaque niveau comportant 256 couloirs et chaque couloir 256 pièces, chaque pièce contenant un caractère.
Le premier niveau de la première maison constitue le « plan de base multilingue » (Basic Multilingual Plane, bmp). Ce niveau est pour l’instant le seul rempli. Ces caractères sont donc codés sur seulement deux octets puisque pour tous les caractères de ce niveau, deux des quatre octets restent identiques, avec la valeur hexadécimale 00 00 2.
Parallèlement s’est développé Unicode, autre jeu de caractères universel, né de la réflexion d’un consortium d’industriels autour de Apple et Rank Xerox. Ce jeu est codé sur deux octets.
Ces deux projets ont fusionné en 1991. Des aménagements ont été faits et Unicode est identique au plan de base multilingue (bmp) de l’iso 10646. On dit souvent qu’Unicode et l’iso 10646 sont identiques, l’affirmation est fausse si l’on s’en tient à la définition stricte des deux systèmes. Si l’on considère en revanche que le jeu de l’iso 10646 est réduit au plan de base multilingue, puisque les autres niveaux ne sont pas définis, elle est pour l’instant acceptable.
Pour faciliter les conversions, les 127 premiers caractères d’Unicode sont ceux de l’iso 646 et les 127 suivants sont ceux de l’iso/iec 8859-1 (latin-1). La version 2.0 d’Unicode contient déjà un grand nombre de langues alphabétiques, y compris l’arabe et l’hébreu, environ 21 000 idéogrammes issus de l’« unification Han », des symboles mathématiques et divers caractères spéciaux 3.
Parmi les bibliothécaires confrontés aux problèmes des langues à écriture non latine, la tendance est nettement à l’introduction des caractères originaux dans le catalogue, pour en faire des outils multilingues et multiécritures (multilingual and multiscript). Non seulement par respect des langues écrites en caractères non latins, mais aussi pour satisfaire les lecteurs qui souvent ne sont pas familiarisés avec les procédés de romanisation. Les bibliothèques attendent donc beaucoup d’Unicode qui devrait résoudre les problèmes de codage des caractères.
Ce code doit cependant être homologué, et, surtout, les concepteurs de systèmes d’exploitation et d’applications informatiques devront le prendre en considération. Il faudra ensuite discuter les autres des six points mentionnés, certains étant déjà en progrès.