Introduction au projet Monocle. Expérience d'automatisation à la Bibliothèque universitaire de Grenoble
La Section sciences de la Bibliothèque universitaire de Grenoble a entrepris une expérience d'automatisation du catalogage et de la production de catalogues imprimés. En partant du projet MARC, des études ont été menées pour rendre les notices bibliographiques rédigées selon les normes françaises lisibles en ordinateur. Une scission des éléments bibliographiques des notices a été établie pour constituer en machines deux fichiers de base : un fichier-bibliothèque (suite continue des notices de livres et, à l'intérieur de ces notices, répartition de tous les éléments en zone) et un fichier servant d'index au premier et comprenant guide, codes d'informations et répertoire.
L'utilisation d'un ordinateur pour améliorer le travail d'une bibliothèque est une opération à laquelle de nombreux bibliothécaires pensent mais qu'ils ne savent pas la plupart du temps comment aborder 1.
Or, avant d'automatiser sa bibliothèque, il faut préciser deux points :
1. L'automatisation n'est pas une panacée qui peut résoudre tous les problèmes et dont la rentabilité est évidente. Il faut attendre plusieurs années avant que les conséquences ne s'en fassent sentir et surtout veiller à ce que l'analyse soit correctement faite pour que les résultats voulus soient obtenus et que le maximum d'opérations soient intégrées.
Il est certain que l'automatisation exigera au début plus de travail du personnel de la bibliothèque et coûtera plus cher que la procédure habituelle mais les résultats obtenus justifient ce surcroît de travail.
2. Pour automatiser une bibliothèque, il faut savoir ce que l'on veut faire et le définir dans une analyse préalable.
Celle-ci consiste à construire la chaîne des opérations qui doivent aboutir à certains résultats, à définir ces résultats, à définir les éléments dont on part, à analyser chaque unité de traitement, les éléments qui la composent et leurs relations pour construire les organigrammes qui régleront chaque opération.
Ensuite, et ensuite seulement, le bibliothécaire peut laisser la main aux programmeurs qui rédigeront les programmes de traitement, programmes qui donnent les ordres à l'ordinateur.
1. Résultats
Pour une bibliothèque, le but final est l'intégration totale de ses opérations dans un système mécanisé où l'information de base, c'est-à-dire la notice catalographique d'un livre, n'entre qu'une fois et sert à plusieurs niveaux, de la commande au prêt.
L'essentiel est donc de mettre au point une notice catalographique de livre lisible en ordinateur.
2. Les éléments
Les éléments d'une notice sont définis dans chaque pays par des normes de catalogage et principalement constitués par :
- La vedette;
- Le titre;
- L'adresse;
- La collation;
- Les notes, etc...
Ceci est une définition fonctionnelle des éléments mais on peut aussi les définir selon leur nature.
- Auteur personne physique
« personne morale.
- Titre original
« translittéré
« traduit.
3. Les relations
Entre ces éléments, l'analyse doit définir plusieurs relations; il y a deux types de relations : relations internes et relations externes.
Les relations internes sont toutes les relations pouvant exister entre les éléments d'une même notice (vedette auteur, éditeur, titre original et titre traduit, titre de classement et titre réel).
Les relations externes sont les relations entre les notices. Ce sont les plus complexes :
- soit relation hiérarchique entre une notice et une sous-notice : du tout à la partie (traité et son volume, périodique et un numéro spécial), de la partie au tout (volume d'une collection, article dépouillé);
- soit relation d'égalité entre deux oeuvres publiées dans un même ouvrage. (Tragédies dans les oeuvres complètes de Corneille.) Ces relations ne sont pas actuellement nettement explicitées dans une notice catalographique.
4. Les buts
Ayant défini ces éléments et leurs relations, voyons quels sont les résultats recherchés.
Partant d'une fiche de livre, la première action visée est d'automatiser le catalogage et de produire des catalogues imprimés des livres entrés à la bibliothèque. Ces catalogues sont les suivants :
- liste hebdomadaire des nouvelles acquisitions classées selon la C.D.U. avec index auteurs et matières;
- liste mensuelle par numéro d'inventaire et par cote.
- catalogue annuel complet soit sous forme d'un catalogue dictionnaire soit de catalogues séparés des auteurs, des titres, des vedettes matière, de la C.D.U. ;
- listes particulières des collections, périodiques, thèses, suites, congrès;
- statistiques par langue, origine, fournisseur, matière, fonds...
5. Le matériel
La Faculté des sciences de Grenoble possède un ordinateur I.B.M. 360/67 que nous pouvons partiellement utiliser. Ce gros calculateur a le triple avantage d'accélérer les tris et de permettre l'accès direct aux disques magnétiques et l'utilisation d'un terminal.
Le système construit a largement utilisé les caractéristiques de la machine pour optimiser les traitements et faciliter l'accès aux documents.
Quatre solutions étaient possibles pour l'entrée des données : la carte perforée, la bande perforée, la bande magnétique, le terminal.
Nous avons choisi la quatrième solution parce qu'elle assure une rapidité et une fiabilité bien plus grandes que les autres systèmes, qu'elle permet l'interrogation directe de l'ordinateur et qu'elle utilise la bande perforée comme mémoire tampon pour économiser le temps d'occupation de l'ordinateur.
Pour la sortie nous utilisons l'imprimante de l'ordinateur munie d'une chaîne spéciale possédant les minuscules et les accents.
6. L'organisation du travail
Nos sous-bibliothécaires au lieu de rédiger les fiches de catalogues, remplissent des bordereaux où figurent toutes les informations concernant un livre.
Ces bordereaux sont perforés sur un terminal 105° d'I.B.M. qui fournit en même temps un texte en clair. Ce texte est corrigé par le bibliothécaire et la bande perforée qui lui correspond est transmise une fois par jour à l'ordinateur qui enregistre, trie et restitue un « listing » des données reçues. Un programme d'analyse passe au crible les notices, vérifie leur structure logique, la longueur des étiquettes, la valeur des codes de sous-zones et restitue un « listing des notices erronées avec des messages d'erreur sur l'imprimante.
Les corrections, phase importante et délicate de l'opération, sont alors effectuées directement en machine à partir du terminal sous contrôle du programme moniteur CP/CMS.
Une fois que les notices sont correctes, elles sont transférées dans une mémoire définitive sous programme moniteur OS pour que soient effectués les tris nécessaires et leur impression.
Pour obtenir une qualité typographique suffisante nous utilisons une chaîne d'impression majuscules et minuscules sur laquelle nous avons fait ajouter les accents et signes diacritiques.
Les catalogues sont produits sur listings d'ordinateur en deux colonnes qui sont photographiés et réduits sur clichés offset au format 21 X 27.
La théorie des opérations étant mise au point, il ne restait plus qu'à définir la structure d'une notice catalographique pour qu'elle soit lisible par l'ordinateur.
Cette analyse qui paraît simple est en fait très compliquée car il faut arriver à structurer et à étiqueter une notice de telle sorte que tous les tris prévisibles soient faisables et surtout que les classements qui ne sont pas strictement alphabétiques soient automatisés.
Par exemple :
La vedette de forme « Bible » se sous-divise non pas alphabétiquement mais systématiquement selon l'ordre des livres de la Bible (Pentateuque, Genèse, Prophètes...) puis par langue (Hébreu, Latin, Français...) et enfin par date.
Plus simplement :
La Fontaine
Van der Mersch
ont un classement continu alors que Frison-Roche a un classement discontinu.
Il faut aussi distinguer : Paris (ville) et Paris (Jean).
Ce ne sont que quelques exemples qui montrent la complexité des problèmes car il faut indiquer à la machine toutes les exceptions et cas particuliers qui sont nombreux dans les règles catalographiques.
Il faut ajouter aussi que l'imprécision des normes françaises en matière de catalogage et la différence entre les normes nationales de certains pays constituent une difficulté non encore résolue.
Plusieurs d'entre ces pays, notamment l'Allemagne, le Canada avaient commencé à mettre au point des systèmes de catalogage par ordinateur, la Bibliothèque de Lyon, la Bibliothèque nationale et nous-mêmes avions aussi préparé des systèmes, mais tous se sont révélés trop sommaires car trop linéaires.
C'est alors qu'ayant découvert le projet MARC préparé par la Bibliothèque du Congrès et repris par la Bibliographie nationale anglaise nous avons décidé de l'adopter pour plusieurs raisons.
- De tous les projets mis au point c'est le plus fouillé, le plus structuré, le plus précis, le plus complet.
- Adopté par deux grands pays anglo-saxons il est proposé comme norme internationale à l'ISO et déjà adopté par l'Allemagne et l'Italie. On voit tout l'intérêt de bibliographies nationales construites sur le même modèle et pouvant échanger les bandes magnétiques répertoriant la production de chaque pays.
- Ce projet, quoique très complet, est aussi très souple et très adaptable. Moyennant quelques précautions, chaque utilisateur peut pratiquement le traiter comme il veut en ajoutant, supprimant, modifiant. C'est ce que nous avons fait.
En effet, le projet MARC est fondé sur les règles de catalogage anglo-américaines et il fallait le revoir en entier pour l'adapter aux règles françaises en attendant des règles internationales en cours de préparation.
C'est à quoi nous travaillons depuis un an et demi sans être parvenus à une version définitive. D'ailleurs, en ce domaine, il n'y a pas de version définitive, puisque les Américains eux-mêmes en sont à la neme version et publient régulièrement des modifications.
Mais nous disposons déjà d'un instrument avec lequel nous pouvons travailler.
Structure générale de monocle
La caractéristique essentielle, au point de vue traitement machine est la scission de la notice de livre en deux parties pour constituer en machine deux fichiers de base.
Le traitement machine exige en effet des éléments en zone fixe et courts, ce dont s'accommodent fort mal les fiches de bibliothèques dont les éléments auteurs et titres sont éminemment variables et aléatoires. Le résultat est un compromis entre ces deux exigences.
Ces deux fichiers peuvent être sur une même bande magnétique, mais sont mieux utilisés s'ils sont enregistrés sur deux disques différents. Les disques facilitent l'utilisation du système, mais ne le conditionnent pas absolument.
Ces deux fichiers sont :
- Un fichier bibliothèque contenant en une suite continue les notices de livres et à l'intérieur de ces notices tous les éléments répartis en zones. Ces zones sont enregistrées les unes à la suite des autres. Aucun moyen d'accès à ce fichier n'est possible sauf la lecture séquentielle de toutes les notices, c'est-à-dire caractère par caractère, ce qui est très long.
C'est pourquoi un deuxième fichier a été créé qui constitue à proprement parler l'index du premier à savoir que chaque zone du fichier bibliothèque est représentée dans l'index par sa longueur, son adresse et le numéro de son étiquette, exactement comme dans un index de livre.
L'étiquette est un code à trois chiffres qui caractérise la nature de la zone.
Exemple : 100 = Zone vedette auteur; 245 = Zone titre; 445 = Zone collection ; 080 = Zone C.D.U.
A ce fichier index ou répertoire est ajoutée une zone « éléments statistiques )) qui est aussi en positions fixes et permet donc d'accéder très rapidement à certaines informations nécessaires aux tris et aux statistiques.
Nous avons donc deux fichiers :
- Un variable auquel on ne peut accéder que par le répertoire.
- Un fixe contenant ce répertoire plus certains codes d'information.
Fichier index
Voici plus en détail la structure du fichier index. Il comprend trois parties : Le guide; les codes d'information; le répertoire.
1. Le guide.
Le guide comprend 19 caractères fixes. Nous y avons mis le guide du projet MARC plus la zone 001 qui fournit dans le projet MARC le numéro de contrôle.
Ce numéro n'est plus le numéro de la fiche de la Bibliothèque du Congrès mais le numéro d'enregistrement de la notice sur le disque. Nous avons supprimé certains éléments qui sont inutiles dans un système interne et devront être rajoutés sur des bandes d'échange (ex : compte des indicateurs, des codes de sous-zones)
Voici l'image de ce guide.
La structure du guide prévue dans le projet MARC est la suivante :
Guide = 24 caractères.
Longueur notice 1 - 5
Statut notice 6
Légende Type de notice 7
Niveau bibliographique 8
Blancs 9 - 10
Compte des indicateurs i i
Compte des codes de sous-zones 12
Adresse des données 13 - 17
Blancs 18 - 24
Structure de MONOCLE :
La position désigne l'état de la notice (nouvelle, ancienne, modifiée, supprimée) ; à chaque code correspond un programme particulier.
La position 2 fournit la nature du document (imprimé, manuscrit, carte, musique, film...); à chaque type correspondra une notice particulière; seule la notice des imprimés est actuellement construite.
La position 3 donne la forme bibliographique c'est-à-dire qu'elle précise la forme de l'imprimé (monographie, article, chapitre, recueil factice, périodique, publication en série...).
Une notice correspondra aussi à chaque forme.
Les positions 4 à 6 contiennent l'adresse de cette notice soit :
- le numéro du disque
- le numéro de la piste (en binaire, 2 octets contiennent 4 chiffres).
Ex. 1. 0274.
Jointe à la longueur, cette adresse nous permet d'accéder directement à une notice (quand on connaît cette adresse) et de l'extraire rapidement. Il suffit pour cela de lire l'adresse qui renvoie au fichier principal.
Les positions 7 - 8 donnent l'adresse de l'index c'est-à-dire le numéro de piste de l'index correspondant à une notice. Jointe à la longueur, elle permet une lecture rapide de l'index.
Les positions 9 - 12 donnent le numéro de l'enregistrement valable pour le fichier index comme pour le fichier bibliothèque. Les chiffres de ce numéro complètent l'adresse de la notice. En binaire quatre octets permettent d'inscrire 8 caractères mais 5 sont pour le moment utilisés, ce qui donne une adresse de 10 chiffres, ex : 1027432543.
Les positions 13 - 14 donnent le nombre des entrées du répertoire c'est-à-dire le nombre de zones de la notice.
Les positions 15 - 16 contiennent la longueur de la notice principale c'est-à-dire le nombre de caractères qu'elle occupe.
Les positions 17 - 18 fournissent la longueur de l'enregistrement index pour telle notice.
La position 19 est blanche.
2. Les codes d'information.
Au-delà du Ige caractère, toujours en positions fixes dans le fichier index, sont placés les codes d'information. Dans le projet MARC ces codes figurent dans une zone variable o08.
Ces codes sont destinés à effectuer rapidement des tris et certaines statistiques sans avoir à rechercher l'information dans le fichier variable.
Ces codes sont un compromis entre un système machine pur et une notice bibliographique.
Tout ce qui peut être codé simplement et nécessite un accès rapide doit être mis dans ce fichier dont la structure en positions fixes permet une grande vitesse de traitement.
C'est ainsi, par exemple, que sont codés le pays de publication, la langue, le sujet, le fournisseur et la nature du livre (collection, suite, congrès, périodique, thèse).
Figurent aussi dans ce fichier quelques renseignements de gestion, en attendant qu'un système de gestion des commandes soit mis au point.
Exemple : Le prix, le nombre d'exemplaires, le fournisseur.
Les positions 1-3 permettent d'inscire la date d'entrée en machine;
La position 4 indique un code de date de publication qui permet de préciser la nature des deux dates de publication qui suivent (date simple, multiple, incomplète...)
Les positions 13 - 15 reçoivent le code du pays de publication. C'est le code automobile qui est utilisé (ex. : Suisse = CH.)
Les positions 16 - 17 permettent d'inscrire deux codes d'illustration (portrait, carte, flore, faune, gravure, couleur.)
La position r8 indique le niveau intellectuel de l'ouvrage (livre pour enfant, de recherche, de vulgarisation...).
La position 19 indique le mode de reproduction de l'ouvrage non imprimé (microcopie, multigraphie, agrandissement).
Les positions 20 - 22 permettent d'inscrire trois codes pour un ouvrage de référence (bibliographie, catalogue, abstracts, index, dictionnaire...). Ce qui permet de signaler tous les ouvrages qui font partie d'un fonds de référence.
La position 23 indique les publications officielles avec quatre codes possibles.
Certaines des positions suivantes sont monovalentes.
La position 24 signale les congrès (0 ou 1).
La position 25 signale les mélanges (0 ou 1).
La position 26 indique si l'ouvrage a ou non un index(0 ou 1);
La position 27 indique si la vedette est répétée dans la notice(0 ou 1).
La position 28 indique si l'ouvrage est littéraire (Roman Poésie) (plusieurs codes)
La position 29 indique si c'est une biographie (plusieurs codes)
La position 30 indique si c'est le 1 er fascicule d'un périodique (0 -1)
La position 31 indique si c'est une publication scientifique (plusieurs codes)
La position 3 - indique si c'est une collection (0 ou 1).
La position 33 indique si c'est une suite (0 ou 1).
La langue est indiquée dans les positions 34 - 36 par un code à trois lettres.
Le sujet est indiqué dans les positions 37 - 38 par un code à une lettre.
Les codes suivants indiquent :
Position 39 : l'existence de caractères non imprimables (russe)
Position ¢o : la source du catalogage
Position 41 : la périodicité
Positions 42-43 : le nombre de volumes
Position 44 : l'origine (D.A.E.)
Positions 45-46 : le fournisseur
Positions 47-48 : le nombre d'exemplaires
Positions 49-54 : le prix.
Enfin les positions 55 - 69 permettent d'indiquer l'empreinte ou code de recherche.
Ce code de recherche étudié par plusieurs bibliothèques répond au besoin d'identifier de façon univoque un livre avec un minimum de caractères et de pouvoir faire des recherches rapides en machine sans utiliser la description totale de l'ouvrage.
A partir de 1969, les ouvrages anglo-saxons sont identifiés par le numéro normalisé de livre, donné par l'éditeur à tous les ouvrages qu'il publie. Ce numéro est unique et contient 10 chiffres.
Mais tous les ouvrages ne sont pas anglo-saxons et beaucoup ont été publiés avant 1969.
C'est pourquoi nous avons étudié un code de 15 caractères qui peuvent être trouvés sur le livre et sur tous les documents bibliographiques qui le concernent (bibliographie, références, prospectus, citation). Il ne contient aucune information prise à l'intérieur du livre.
Il est constitué par :
- les quatre premiers caractères de la vedette (auteur ou titre);
- le premier caractère de la sous-vedette (prénom ou deuxième mot du titre);
- les quatre premiers caractères du titre ou de l'éditeur;
- le premier caractère du deuxième mot ou prénom;
- le premier caractère de la ville;
- le premier caractère de l'éditeur;
- les trois derniers chiffres de la date.
3. Le répertoire.
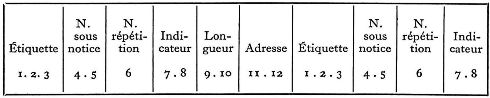
La deuxième partie du fichier index est constituée par le répertoire qui correspond à la table des matières du fichier principal.
Ce qui signifie que chaque zone du fichier principal est représentée dans ce répertoire par 12 caractères qui sont répartis comme suit :
3 = Étiquette de la zone
2 = Numéro d'ordre de la sous-notice
1 = Numéro de répétition de la zone
2 = Indicateurs
2 = Longueur de la zone (en binaire soit 4 chiffres)
2 = Adresse de cette zone par rapport au début de la notice c'est-à-dire : numéro du premier caractère de la zone (en binaire soit 4 chiffres).
Ex. : 100 00 0 10 0043 0028
Ce qui veut dire :
Étiquette =100
N° sous-notice = 00
N° de répétition = 0
Indicateurs de fonction = 10.
Longueur = 4.3 caractères.
Adresse 28 zone commençant au 28e caractère de la notice.
Le répertoire contient pour chaque notice la liste de toutes les zones par ordre numérique avec leur longueur et leur adresse, ce qui permet un accès et une lecture rapides de chaque zone sans avoir à la parcourir caractère par caractère. C'est toute la différence entre un accès direct qui va directement à un endroit précis du disque et lit d'un seul coup X caractères et l'accès séquentiel qui doit parcourir tous les caractères avant de rencontrer le bon.
Fichier principal
La légende et le répertoire sont donc sur un fichier.
Sur le deuxième fichier figurent les « données » c'est-à-dire les notices catalographiques de livres séquentiellement les unes après les autres. Ces notices sont divisées en zones, elles-mêmes sous-divisées en sous-zones.
La structure de ce fichier possède quatre caractères qui lui donnent sa souplesse et sa richesse.
1. Le premier caractère est constitué par la répartition de tous les éléments importants de la fiche en zones définies par un code à trois chiffres.
100 = Vedette principale auteur
080 = C.D.U.
245 = Titre.
Ces trois chiffres permettent donc de définir 999 zones différentes.
Ces étiquettes ne sont pas données de façon quelconque mais leur ordre numérique correspond à l'ordre de présentation habituel de la fiche de catalogue.
0 = Numéro d'identification de l'ouvrage
1= Vedette principale
2 = Titre
3= Collation
4= Note de collection
5 = Note
6 = Vedettes matière
7 = Vedettes secondaires
9= Renvois.
2. Le deuxième caractère concerne la structure de ces étiquettes. Elles ont, nous l'avons dit, trois chiffres. Ces trois chiffres ont une fonction particulière et peuvent être utilisés en vue de tris ou de classements particuliers :
- le premier chiffre indique la fonction de la zone;
- les deuxième et troisième chiffres désignent les types des éléments ayant ces fonctions.
Ainsi une vedette principale peut être :
100 Auteur
110 Collectivité
II Congrès.
Car :
- le 00 désigne un nom de personne
- le 10 désigne une collectivité
- le II désigne un congrès.
Un nom de personne oo sera donc étiqueté :
ioo s'il est vedette principale
700 s'il est vedette secondaire
600 s'il est vedette matière
90o s'il est renvoi.
De même pour un nom de collectivité.
Cette structuration des étiquettes aboutit à faire correspondre leur ordre numérique à l'ordre de classement suivant :
Auteur personne physique ioo
Auteur personne morale 110
Congrès 110
Titre de classement 240
Titre d'anonyme 245
et permet donc de classer correctement les homonymes selon leur nature et leur fonction.
Le troisième élément est constitué par les indicateurs de fonction. Ils sont formés par deux chiffres qui suivent l'étiquette de zone et précèdent les données. Dans un autre système, ils pourraient être 3 ou 4 ou o. Selon les besoins, leur nombre est indiqué au début du fichier « guide ».
Ces deux chiffres ont des significations différentes selon les zones et permettent d'appuyer des programmes particuliers.
Par exemple dans la zone 041 langue, le premier indicateur peut être :
0 ou 1.
o désigne un ouvrage multilingue
i désigne une traduction.
C'est dans la zone auteur que ces indicateurs ont leur signification principale.
Exemple : Premier indicateur :
0 = prénom
1 = Nom simple
2 = Nom composé.
Deuxième indicateur :
i la vedette principale est aussi vedette matière
0 la vedette principale n'est pas vedette matière.
Le premier indicateur permet de classer de façon différente les noms simples qui ont un classement continu (Van der Mersch) et les noms composés qui ont un classement discontinu c'est-à-dire où le blanc intervient (Paris Duverney).
Le programme, trouvant l'indicateur mis à i supprime pour le tri tous les blancs, en revanche s'il trouve un 2 il les laissera.
En zone zoo, le deuxième indicateur mis à i signale qu'il faut faire un renvoi d'un titre à un autre titre.
Ces indicateurs prennent aussi d'autres significations (typographiques par ex.).
Avec tous ces éléments, les classements qui ne sont pas strictement alphabétiques peuvent être programmés facilement.
A ces indicateurs de fonction nous avons rajouté comme les Anglais, mais en allant encore plus loin qu'eux dans cette voie 3 autres chiffres.
2 : constituent les numéros de sous-notices. Cette notion de sous-notice est assez complexe; voici un exemple 2 :
JEANSON (Francis)... Sartre... suivi d'un choix de textes... Une vedette secondaire sera établie à :
SARTRE (J.-P.) Textes choisis... Voir : Jeanson.
Les Textes choisis font partie de l'ouvrage de Jeanson et la notice (Sartre + Textes choisis) constitue une sous-notice de la notice principale Jeanson. De même, dans un traité contenant plusieurs volumes, chacun des volumes s'il a : auteur, titre, date d'émission, coauteurs... constitue une sous-notice de la notice principale : Traité.
Actuellement une seule relation est prévue entre notice et sous-notice; c'est ce que les Anglo-saxons appellent « analyticals », et ce que nous appellerons relation hiérarchique du tout à la partie, ou dépouillement.
Chaque sous-notice comporte donc un numéro de 2 chiffres qui permet d'identifier toutes les zones qu'elle contient :
Ex. :
Le 3e chiffre sert à numéroter les zones répétées d'où son nom d'indicateur de répétition :
En effet dans une notice (principale ou secondaire) il peut y avoir plusieurs vedettes secondaires :
1 coauteur;
1 traducteur;
1 préfacier.
qui sont toutes numérotées 700; or il se peut que le coauteur soit un pseudonyme. Il faut donc adresser un renvoi étiqueté 9oo à la première étiquette 700. D'où la nécessité de la numéroter pour l'identifier.
C'est pourquoi l'étiquetage d'une zone est le suivant :
100
Etiquette
00
Ind.
00
s/n
0
Répétition
Mais les 3 derniers chiffres ne sont inscrits que s'ils sont ditlérents de o. S'ils sont égaux à o, la machine les rajoutent elle-même.
4. Le quatrième élément qui caractérise la structure du fichier est constitué par les codes de sous-zones qui sont représentés par le signe$(dollar) suivi d'une lettre minuscule.
Ces codes qui vont donc de a à z ont des significations différentes selon les zones et permettent de délimiter à l'intérieur d'une zone les éléments qui ne méritent pas une zone particulière mais doivent cependant être retrouvés. Certains systèmes (Bodleian Library) ont attribué une zone à chaque élément (prénom, sous-titre, éditeur). Or de nombreux éléments sont secondaires car jamais recherchés pour eux-mêmes. Il faut donc alléger le répertoire en ne donnant des étiquettes qu'aux éléments principaux servant aux tris.
Ainsi dans la zone « adresse » sont délimitées les sous-zones :
$a Ville
$b Éditeur
$c Date.
Dans la zone « titre sont délimitées les sous-zones :
$a Titre abrégé
$b Sous-titre
$c Auteur, éditeur
$d Mention des volumes
$e Reste du titre.
Le problème reste posé de savoir si ces codes de sous-zones doivent ou non avoir une valeur classificatoire. Ceci veut dire que les données inscrites derrière$a doivent être classées avant celles inscrites après$b et ainsi de suite.
Les opinions sont partagées; les Américains ont renoncé à la valeur classificatoire des codes, ce qui les oblige à construire plusieurs tables internes à la machine donnant à chaque code sa valeur de classement.
Les Anglais, après avoir prévu un système de codes classificatoires, semblent l'avoir abandonné.
Pour notre part, nous l'avons conservé, essayant de donner aux codes non seulement une valeur d'identification, mais aussi, dans la mesure du possible, une valeur de classement; cela simplifie les programmes.
C'est pourquoi nous avons modifié de nombreux codes de sous-zones prévus par la B.N.B. et la « Library of Congress », qui ne sont d'ailleurs pas toujours d'accord entre elles.
Ainsi, par exemple, dans la zone 100 = vedette principale auteur, nous avons les codes :
$a Nom
$b Qualificatif de classement Saint
$c - - Pape
$d - - Empereur
$e - - Roi de France
$f - - Autres rois
$g Relation
$h Date
$i Numérotation
$k Qualificatif secondaire
$l - principal
$m Prénom
Le prénom vient en dernier,''car, selon une matrice de classement établie par la B.N.B., en cas d'homonymie le classement est en gros le suivant et ceci conformément aux règles françaises (Le classement anglo-saxon est différent) :
PIERRE (Saint) PIERRE (Jacques)
PIERRE 1er Empereur de Russie PIERRE (Jacques) Ed.
PIERRE PIERRE (Jacques) Abbé
PIERRE Ed. PIERRE (Jacques) Avocat
PIERRE (Le Petit) etc...
PIERRE (Abbé)
Car le grand problème que pose le classement des notices en machine concerne surtout les homonymes. C'est pourquoi une structure aussi détaillée a dû être prévue. Tant que les noms sont différents le classement alphabétique s'effectue en machine de façon toute simple.
Mais lorsque les noms sont identiques, il faut bien préciser leur nature et leur fonction et les étiqueter en conséquence.
Toutefois un problème particulier se pose pour certaines rubriques qui nécessitent un classement logique :
Ex. : Bible Thèse
Titre de classement Congrès.
Vedette de forme
C'est pourquoi ces rubriques ont reçu un codage spécial. Par exemple les titres, sont classés dans l'ordre :
1° Titres collectifs de classement : étiquette 24o
2° Œuvres complètes indicateur 10
3° Œuvres choisies indicateur 20
4° Textes choisis indicateur 30
5° Autres titres indicateur 40
6° Titres de classement individuels : étiquette 241
7° Avec prénom indicateur oo
8° Avec nom simple indicateur 10
9° Avec nom composé indicateur 20
10° Sans nom de personne indicateur 40
11° Titre réel : étiquette 245
A l'intérieur des titres de classement individuels sont prévus les codes de sous-zones suivants qui permettent de préciser le tri de ces titres :
$a Titre
$b N° de classement logique (un numéro est donné à chaque livre de la Bible ou du Coran)
$c Reste du titre$k Nom de personne
$d Mention d'adaptation$1 Qualificatif
$e N° classement par langue$m Prénom
$f Langue$p Ville
$g N° classement par date$q Établissement.
$h Date
Ex. : [$a Bible$b i$c Pentateuque$d Synopse$e 4$1 français $h 1963.]
La plus grande difficulté de la structure n'est donc pas dans l'identification des éléments d'une même notice, mais dans les relations des notices entre elles et leur classement et ce fut le grand mérite des Anglais d'avoir soulevé le problème et de l'avoir en grande partie résolu.
Ce classement s'effectue à trois niveaux.
- Classement des étiquettes entre elles selon la nature des rubriques :
Nom de personne 100
Nom de collectivité 110
Nom de congrès 111
Titre 240
- Classement des étiquettes entre elles selon la fonction des rubriques :
Vedette auteur ioo
Vedette secondaire 700
Renvoi 900
- Classement des étiquettes identiques grâce à leurs codes de sous-zones.
Plus on descend à l'intérieur des zones, plus l'identification devient précise.
Voici les caractéristiques du fichier principal. Il n'est pas possible, dans le cadre de cet exposé de donner la liste complète des zones et leur signification détaillée.
Quelques commentaires succincts suffisent à en faire comprendre le mécanisme.
En conclusion il est essentiel de préciser que l'automatisation des bibliothèques passe avant tout par une analyse très précise du catalogage et des normes qui le règlementent.
Il serait d'ailleurs souhaitable, bien que difficile, de poursuivre cette analyse par une recherche sur la structure logique d'une notice bibliographique et la construction de ses éléments, leurs rapports et leurs valeurs, puis la mise au point d'algorithmes permettant d'effectuer simplement et à moindre frais tous les tris, la recherche en machine et l'impression.
Cette étude apporterait une lumière nouvelle sur les fiches de catalogue et permettrait d'en mieux comprendre le mécanisme.
Les normes existantes sont souvent très particulières et la plupart du temps insuffisantes. Or, si l'on veut utiliser une machine, ce sont des ordres clairs qu'il faut lui donner et la part d'improvisation ou d'appréciation personnelle doit disparaître. Nous sommes tous à souhaiter que des normes internationales soient rapidement établies, qui faciliteront grandement l'échange de données bibliographiques.
Toutefois si ces normes doivent être précises, il ne faut pas chercher trop le détail, les cas rares (les bibliothécaires ont trop souvent tendance à ne voir que les exceptions qui foisonnent dans l'édition) car ces cas qui peuvent n'apparaître que trois fois sur cent risquent d'alourdir le traitement en machine.
II y a un équilibre à trouver entre ce souci du détail et celui de la rentabilité.
La solution peut dépendre aussi de la rédaction des programmes qui, s'ils sont suffisamment modulaires et bien construits, peuvent prendre en charge tous les cas possibles sans alourdir le traitement de 97 % des livres.
Je crains fort que le schéma aussi succinctement présenté ne soit ni très clair ni très facile à étudier tel quel. Une notice d'emploi est sans aucun doute nécessaire pour éclaircir la signification de tel ou tel code. J'espère qu'il sera possible de mettre au point sous peu une telle notice. La brochure publiée par l' « American library association » et intitulée Marc Manuals se révèle très utile.