Le système Carol : une suggestion pour les documentalistes d'entreprises et d'instituts
Le Carol est un système d'exploitation de la documentation qui renonce délibérément à l'unicité des outils d'accès aux informations. La liaison est établie entre ces divers types de fichiers par un répertoire automatique de répertoires où les documents sont déjà organisés. Ce mode de raisonnement semble être une direction de recherche originale qui permettra de mieux résoudre les problèmes de documentation intérieure
I. - Réflexions.
On décrit volontiers un service de documentation d'entreprise ou d'institut comme spécialisé dans la discipline qui relève de la mission ou de l'activité de son établissement, et comme non spécialisé, mais documenté, dans un grand nombre de disciplines voisines. C'est pourquoi, un tel service de documentation, généralement assorti d'une bibliothèque, s'efforce d'avoir un fichier bien tenu dans sa spécialité, en vue de répondre vite aux questions les plus souvent posées par les spécialistes de son établissement.
A la vérité nous devons constater que n'importe quelle activité industrielle ou n'importe quelle activité de recherche fait appel à un nombre de disciplines de plus en plus grand. Chaque service de documentation ou chaque bibliothèque se doit donc de couvrir un grand nombre de disciplines spécialisées, dont l'ensemble caractérise de façon originale le profil de l'ensemble des utilisateurs à servir.
L'accroissement du flot d'informations et de documents à traiter par chaque service de documentation spécialisé est donc dû à un double phénomène : l'accroissement, bien connu, de la masse de littérature, et l'augmentation constante du nombre de disciplines que chaque groupe humain doit pratiquer pour remplir sa mission.
Dans l'état actuel des choses, chaque service de documentation ou bibliothèque constitue son fichier en extrayant de chaque document reçu un résumé et une indexation pour le classement en vue de la recherche. On s'efforce alors d'avoir un système unique d'indexation. Si tous les documents reçus sont indexés par ailleurs par un service central, il n'y a pas de difficultés. Mais une telle indexation centralisée n'est pas toujours réalisée et n'englobe pas, en tout cas, tous les documents que l'entreprise ou l'institut reçoit.
C'est pourquoi le service de documentation se constitue son propre fichier basé sur une certaine unicité. Pour la commodité de l'exposé nous appellerons ce fichier « fichier de la bibliothèque ».
Des enquêtes 2 ont montré que l'unicité du fichier de la bibliothèque n'est plus qu'une fiction.
La recherche de documents ou d'informations nécessite en effet la consultation d'un grand nombre de sources, parmi lesquelles le fichier de la bibliothèque n'est plus que l'une d'entre elles, la plus sûre, il est vrai, mais pas la plus rapide. Le développement des bulletins d'extraits spécialisés contribue beaucoup à cet état de fait et y contribuera de plus en plus. Il est d'ailleurs dans le sens de l'évolution que la publication de bulletins de documentation spécialisés de plus en plus nombreux, libère les bibliothécaires du soin d'établir des fiches pour chacun des documents susceptible d'être retrouvé dans leurs collections. Il y aura de plus en plus dissociation entre répertoires par sujets et rangements de collections.
A cette constatation, il faut encore ajouter que l'énergie dépensée pour indexer les documents dans un système unique, oblige à prendre connaissance du contenu de chaque document du point de vue du documentaliste local, en vue d'en déterminer l'indexation dans un mode de classification déterminé. La seule exception, heureuse, est celle des documents portant à l'impression des descripteurs ou bien l'indice CDU.
Or, beaucoup de documents portent en eux-mêmes des signes, mots ou index, manifestant qu'ils ont été conformés, créés, analysés ou rangés suivant un mode d'analyse ou de classification propre et différent de celui du fichier de la bibliothèque.
Dans certains cas, comme celui des brevets d'invention, ces documents portent l'indice d'un classement comportant 30 000 ou 40 ooo rubriques. Ces classements n'entrent pas, de toute évidence, dans le système de rangement de la bibliothèque. Si on les réindexe dans le système de sa bibliothèque, qui ne comporte généralement qu'un plus petit nombre de rubriques, il apparaît alors clairement un autre inconvénient au principe de l'unicité de la classification : malgré une énergie relativement importante, l'indexation unitaire est moins significative que celle portée par les documents reçus. L'indexation unitaire détruit d'autres critères de sélection des documents.
Une analyse détaillée faite sur tous les documents enregistrés au laboratoire du Centre d'études et recherches des charbonnages de France (CERCHAR) nous a montré clairement le bien-fondé de ces constatations dans les domaines non miniers.
II. - Suggestions : le système CAROL
On en arrive donc à renoncer à l'unicité d'indexation des documents, à la dénoncer comme inutile de notre point de vue, et à accepter la création d'autant de fichiers ou de répertoires que de catégories ou séries de documents. Autrement dit, on arrive à l'idée qu'il faut indexer les documents non plus dans notre système de classification des disciplines, mais dans chaque système de classification de disciplines correspondant au mode de pensée des gens qui les ont émis ou analysés 3.
En ce qui concerne les brevets d'invention, l'application en est immédiate : il suffit de classer les brevets d'après le plan de classification des instituts qui les publient.
On arrive ainsi à l'acceptation de la pluralité des fichiers en renonçant à la fiction de l'unicité. On est amené en même temps à considérer avec un œil nouveau quantité d'autres fichiers ou répertoires existant déjà ou faciles à créer, qui sont des sources d'information de valeur non négligeable et mal exploitées. Le principe de l'unicité les rejetait en effet dans l'ignorance, en tant que sources globales d'information, et ne retenait d'eux que les documents eux-mêmes pour les répertorier un par un différemment. Pour notre institut nous avons ainsi suggéré de considérer les ensembles suivants : liste des publications de l'établissement, liste des dossiers documentaires, liste des dossiers d'étude de validité de brevets d'invention, liste des études inscrites au programme du Centre, collection des comptes rendus de recherche intérieurs, rapports de sociétés et d'instituts, catalogues de fournisseurs, filmothèque, etc...
La pluralité des fichiers et des répertoires se substituant à l'unicité pose alors un problème nouveau de communication avec l'ensemble des documents répertoriés dans l'ensemble de ces fichiers ou répertoires, que nous appellerons répertoires primaires.
La suggestion, que nous faisons, est de répertorier chacune des rubriques de ces fichiers ou répertoires primaires. Chaque rubrique des répertoires primaires serait ainsi considérée dans un répertoire central comme une information, dont les descripteurs seraient constitués des mots utilisés dans la désignation de la rubrique et dont l'adresse serait constituée du nom du répertoire et de la page ou de l'index correspondant dans le répertoire de la désignation considérée.
On conçoit facilement qu'il soit possible de créer mécaniquement et de consulter automatiquement le répertoire central, que nous avons désigné sous le nom de CAROL (Consultation automatique des répertoires ouverts aux lecteurs). Nous en décrivons une application expérimentale plus loin.
Bien entendu, on ne reprendra dans le CAROL que les rubriques des répertoires primaires correspondant à des documents réellement présents dans la bibliothèque, ou bien, dans certains cas exceptionnels, des rubriques vers lesquelles nous désirons avoir une ouverture complémentaire.
On voit que le CAROL pourra être établi mécaniquement et qu'on pourra le traiter suivant tous les processus connus pour ces types de répertoires. On pourra en particulier l'éditer sous forme de listes à permutation, avec ou sans coordination du vocabulaire. La liste sera établie soit sous forme de liste générale, soit de préférence sous forme de listes partielles par discipline ou par spécialité.
Facile à imprimer par spécialité, le CAROL sera normalement consulté sous forme imprimée, bien qu'il soit concevable de le consulter par interrogation de l'ordinateur.
L'intégration brute d'un système à descripteurs non hiérarchisés n'a pas encore été étudiée par nous. En effet, le CAROL exige une sorte de préclassement par rubriques constituant un ensemble suffisamment significatif, ces rubriques étant des subdivisions d'un plan de classification systématique, ou bien d'un système à mots-vedettes avec subdivisions. Il est clair que les systèmes à mots-clés permutés, qu'ils soient en vocabulaire ouvert ou en vocabulaire fermé défini par un thésaurus, ne répondent pas à ces conditions. Mon inquiétude n'est pas très grande, car les systèmes à thésaurus s'orientent de plus en plus vers le groupement par famille tendant à les apparenter aux systèmes à mots-vedettes hiérarchisés.
Il n'est pas exclu qu'on mette dans un fichier primaire spécial les articles de revue portant des indices de classification CDU (Classification Décimale Universelle), ceci en vertu du principe nouveau qu'il convient d'utiliser, de façon aussi automatique que possible, les descripteurs ou indices existants, pour éviter l'analyse sérielle et individuelle des documents.
Chaque fois qu'on le pourra, on préfèrera les fichiers imprimés automatiquement aux fichiers sur cartes.
III. - Présentation d'une réalisation expérimentale
Le domaine sur lequel a porté l'expérience est celui des machines d'abattage pour mines de houille. On a traité une dizaine de répertoires primaires parmi lesquels se trouvent des répertoires internes (Publications CERCHAR, listes d'études) et des répertoires externes (Fichier de documentation minière édité par le CERCHAR pour les ingénieurs des Houillères françaises, Brevets allemands et américains).
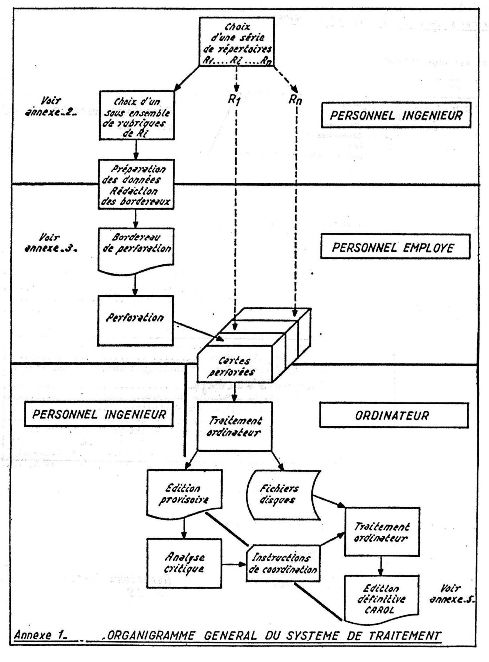
L'annexe 1 représente l'organigramme général du système de traitement. Nous allons en préciser quelques phases en insistant plus particulièrement sur ce qui nous semble en constituer l'originalité.
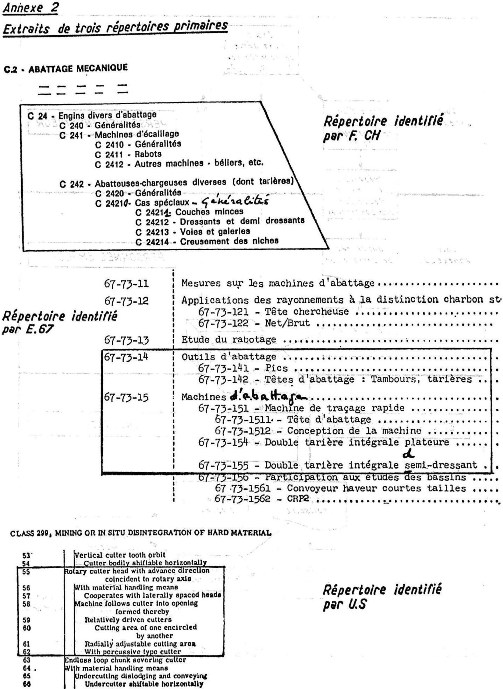
L'annexe 2 montre des extraits de trois de ces répertoires primaires. L'annexe 3 donne un exemple de bordereau de perforation de données et le listing des cartes perforées associées aux rubriques encadrées dans l'annexe 2.
Il n'est pas indispensable d'avoir arrêté le choix des répertoires dès le début d'un traitement, car les répertoires sont traités séparément dans la phase d'élaboration des données, et ne sont fusionnés qu'au moment du traitement pour édition du CAROL.
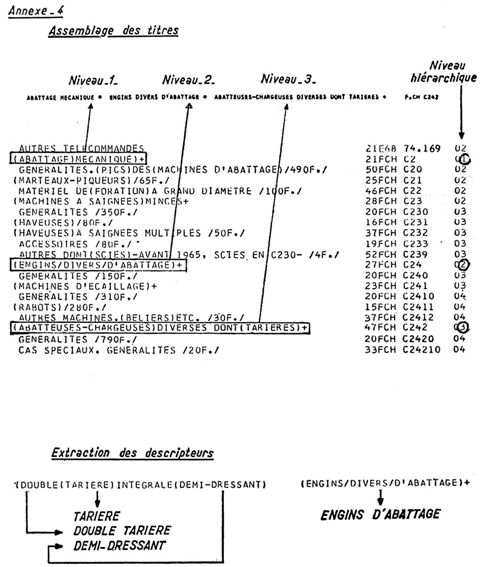
Chaque rubrique sélectionnée est transcrite en une carte perforée qui contient 3 éléments essentiels :
* le titre, remanié plus ou moins profondément, si nécessaire (explicitation de mots ambigus ou d'emploi abusif - traduction éventuelle). On s'efforce de le rendre significatif. Dans une exploitation courante, il devra employer un vocabulaire coordonné.
* la référence, comportant - d'une part, un identificateur du répertoire, choisi pour sa qualité mnémonique (par ex. : F. CH pour Fichier Cerchar.)
- d'autre part, la notation habituelle à l'intérieur du répertoire considéré, dite notation interne.
Exemples (voir figure)
* le niveau hiérarchique.
L'assemblage des titres se fait grâce au « niveau hiérarchique » (colonne 80 des cartes perforées), comme il est présenté en annexe 4.
Pour le choix des entrées, on applique le principe de l'indexation par segments.
En face d'une entrée de l'index apparaissent :
I) Les titres complets des rubriques associées à cette entrée.
2) Les rubriques de niveau hiérarchique immédiatement supérieur, s'il en existe. Dans ce cas un signe « + » à la fin d'une rubrique indique si celle-ci est encore subdivisée.
Ce traitement par segment est indispensable pour éviter une édition trop volumineuse qui reprendrait à chaque mot clé toutes les rubriques le contenant n'importe où.
On a utilisé un ordinateur IBM type 360/44, disponible dans notre établissement. Les programmes sont écrits presque totalement en FORTRAN. Afin d'obtenir un produit agréable et facile à consulter, nous avons employé trois programmes expérimentaux. Ils ont permis de tester les principes du système et de réaliser quelques produits.
Un premier programme dit EXTRA effectue l'extraction des descripteurs et l'assemblage des titres complets. Les deux autres programmes sont classiques. L'un constitue un fichier inversé trié alphabétiquement, l'autre édite l'index.
L'indexation se fait simplement en plaçant des délimiteurs dans les espaces de séparation des mots, comme il est présenté en annexe 4 (parenthèses et barres obliques).
Du fait du procédé d'extraction des descripteurs qui sont des mots ou groupes de mots du « langage naturel », les entrées de l'index sont incohérentes (opposition singulier-pluriel, synonymes, homonymes, etc.)
A partir d'une analyse critique de l'édition provisoire, on établit des instructions de coordination, dont une part peut déjà être en mémoire du fait d'éditions antérieures :
- suppressions d'entrées ou de titres d'une entrée;
- transfert des titres d'une entrée sous une autre, transfert sous une entrée créée spécialement à cet effet;
- transfert avec maintien de l'ancienne entrée;
- préparation de renvois entre entrées de sens voisin, etc.
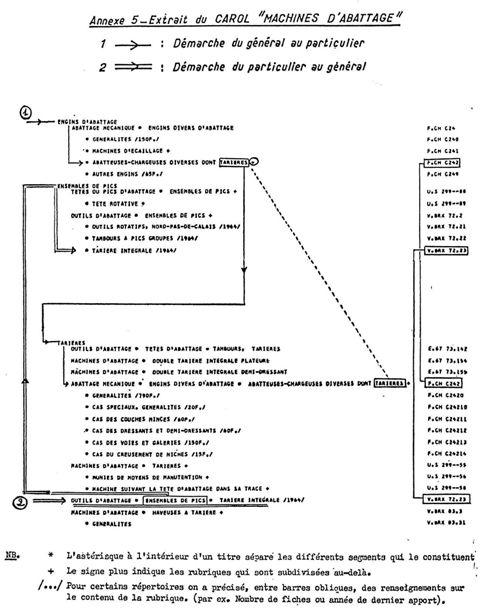
Un quatrième programme dit COORD prend donc en compte ces instructions et modifie le fichier inversé sans modifier les libellés des rubriques dans leur richesse syntaxique. On peut alors procéder à l'édition définitive dont on trouvera en annexe 5 des extraits correspondant aux répertoires primaires cités précédemment. Il est intéressant de comparer l'annexe 2 et l'annexe 5 sur laquelle nous avons tracé les façons d'accéder du particulier au général et du général au particulier grâce au traitement par segment avec utilisation du signe « + ».
IV. - Avantages attendus du CAROL
On peut, à la suite de notre expérience, énoncer quelques avantages du système considéré :
- très grande finesse d'indexation des documents eux-mêmes par l'utilisation directe des rubriques, généralement permanentes, des répertoires ou fichiers faits par ceux qui émettent les collections;
- possibilité d'introduire dans le système de nombreux nouveaux ensembles d'informations ou de documentation, créés ou préexistants sous n'importe quelle forme matérielle;
- possibilité de reprise du passé;
- résolution du vieux problème du vieillissement des informations, en décidant, pour chaque consultation ou impression, quelle tranche de temps prendre dans chacun des répertoires primaires;
- possibilité d'actualiser de très près les informations par l'introduction de répertoires à vie courte;
- possibilité d'introduire pratiquement n'importe quoi, y compris les ouvrages (en considérant leur sommaire comme un répertoire primaire), ou, dans un institut de recherche, les fichiers individuels des chercheurs qui accepteraient et ce, sans les obliger à un plan de classement qui ne leur convient pas;
- possibilité, facile pour ce genre de procédé, de tri entre les documents confidentiels ou non confidentiels;
- possibilité de mettre à la disposition de chacun une édition sélective de CAROL personnalisé, ne vieillissant que très lentement;
- utilisation directe en fichiers primaires des classifications en langues étrangères (usuelles), avec possibilité de traduction en mots coordonnés de la langue nationale dans le CAROL;
- élimination du problème insoluble de la compatibilité des indexations, en la rendant inutile au niveau des fichiers primaires, un langage coordonné pouvant être utilisé dans le CAROL pour y « traduire » les rubriques enregistrées, la « traduction » pouvant être échangée entre services de documentation pour développer la coopération;
- possibilité de modifications relativement graduelles des usages. C'est ainsi que par anticipation sur le fonctionnement futur du système, le laboratoire du CERCHAR l'applique aux brevets d'invention depuis le Ier janvier 1968;
- possibilité d'opérer des modifications de libellés, par une coordination progressive du vocabulaire « traduit » des rubriques de différents répertoires primaires ;
- gestion de petits fichiers pouvant n'occuper chacun qu'une fraction de mémoire;
- remplacement du travail sériel analytique de documents individuels à faible probabilité d'utilisation, par un travail de raisonnement constructif sur des ensembles à probabilité d'utilisation évaluable, permettant de fixer des priorités.
V. - Conclusion
Le CAROL est un système d'exploitation de la documentation, dont la caractéristique essentielle est de reposer sur un nouveau mode de raisonnement. Ce système s'accommode, au départ, des outils existants, et en propose un nouvel assemblage au moyen de méthodes, de langages et de programmes également existants. Il donne le moyen d'accéder à une grande quantité d'informations jusqu'ici éparses.
La base du nouveau raisonnement est qu'il faut renoncer à l'unicité des outils d'accès aux informations, pour accepter le principe nouveau de leur pluralité, ce qui permet de conserver la finesse de chacun des langages de classification utilisés par chaque fichier ou répertoire. Le moyen de liaison est le répertoire automatique des répertoires (CAROL), dans lequel on considère des documents non plus un par un mais dans leurs ensembles organisés. Le travail des documentalistes et la coopération entre centres et entre pays doivent s'en trouver améliorés.
En proposant notre projet, nous savons bien que nous ne résolvons pas d'un seul coup tous les problèmes, mais nous croyons donner une direction de recherche originale et un mode de raisonnement nouveau qui permettront de trouver une nouvelle approche aux problèmes de documentation intérieure.