Précoordination et hiérarchie dans l'indexation
Pour répondre à des recherches de plus en plus précises alors que les travaux scientifiques ont un contenu de plus en plus complexe et que les fonds des bibliothèques sont de plus en plus importants, une indexation précise des documents est nécessaire. Deux systèmes sont en concurrence. - l'indexation pré-coordonnée caractéristique des systèmes d'indexation hiérarchisés traditionnels qui ont le grave défaut de trop disperser des sujets voisins; - l'indexation post-coordonnée qui consiste à ne coordonner les termes d'indexation d'un document qu'à l'occasion d'une recherche particulière portant sur ces termes, les vedettes caractéristiques d'un document pouvant donc être multipliées autant qu'il est nécessaire pour cerner un sujet.On ne peut cependant conclure à l'avantage du second de ces systèmes sur le premier si l'on n'a pas étudié attentivement les avantages et les inconvénients de l'un et de l'autre.
L'indexation en bibliothéconomie est l'art de mettre en évidence les ressources d'une bibliothèque de telle sorte que l'on puisse dire à l'avance rapidement et sans se tromper à quel endroit exact de l'ensemble du fonds se trouve la réponse à une question donnée. On pratique l'indexation à deux niveaux : au niveau du classement en rayons des documents eux-mêmes et au niveau des catalogues où chaque document est représenté par des symboles, en l'occurrence par des vedettes diverses. En règle générale c'est à ce second niveau qu'on fait surtout allusion quand on parle d'indexation.
Mise à part l'opération classique du catalogage par auteur et par titre, l'objet principal de l'indexation est la détermination, à partir du contenu des documents, des classes auxquelles ils appartiennent (ex : documents sur la fusion de l'électron). Pour retrouver rapidement et efficacement des documents répondant à une question, il suffit, nous nous plaisons à le croire, d'examiner simplement un nombre de classes très limité. Lors de la recherche on laisse de côté la plus grande partie du fonds.
La recherche (c'est-à-dire au sens propre le fait de retrouver les documents) est effectuée grâce à la confrontation des données de la recherche avec les descriptions bibliographiques des documents (les vedettes d'indexation). Dans une bibliothèque, si une demande est formulée avec exactitude dans le langage d'indexation utilisé et si les vedettes sont rédigées avec exactitude, un document dont la vedette s'assortit d'une manière significative avec les données de la recherche répond selon toute vraisemblance à la demande. Que ceci ne soit pas toujours vrai c'est un fait gênant dont nous ne traiterons pas ici car cette incidence n'affecte pas la règle générale. Le critère décisif qui permet de juger une indexation est la facilité et l'exactitude avec laquelle cette confrontation peut être opérée.
Les données de la recherche aussi bien que les vedettes consistent essentiellement en un ensemble de termes très limité, par exemple : sucre, betterave, feuilles, engrais. Les relations entre les concepts représentés par les termes peuvent être ou non indiquées, ainsi les feuilles de betterave à sucre peuvent être désignées comme quelque chose qui reçoit l'engrais (« sujet ») ou comme quelque chose qui sert d'engrais (« agent »). Il arrive rarement que les données de la recherche correspondent point par point aux vedettes d'indexation. En général la donnée ou une partie de la donnée correspond à une partie des vedettes de plusieurs documents différents; ainsi à une question sur « le champ d'ondes autour d'un corps se déplaçant dans un gaz raréfié, partiellement ionisé en présence d'un champ magnétique », on trouvera que répondent (entre autres) à des degrés divers les rapports suivants : les ondes dans les gaz à faible pression comparées aux pressions magnétiques ; le sillage d'un satellite à travers l'ionosphère; la résistance d'induction sur un satellite chargé négativement se déplaçant dans une ionosphère à champ magnétique libre (les termes correspondant à la recherche sont soulignés). Les conséquences de cette situation sont claires : nous devons être à même de modeler les classes établies lors de l'indexation de telle façon que les recherches puissent être souples. Nous devons être capables d'élargir ou de contracter les classes, dans leur ensemble ou en partie, de façon à parvenir à des degrés variables de correspondance ; c'est ainsi que nous devons être à même de rechercher non seulement la classe « corps » mais toutes sortes de corps (comme les satellites) susceptibles de se rapporter au contexte. De même, nous devons être capables d'amener la classe « gaz ionisé » à englober la classe « ionosphère ». L'histoire de l'indexation peut être considérée comme l'amélioration progressive des méthodes pour obtenir des réponses de plus en plus souples aux données des demandes, autrement dit aux combinaisons particulières de leurs termes.
Dans cette évolution trois étapes principales peuvent être distinguées. D'abord la mise en ordre, selon une classification, des documents eux-mêmes, c'est-à-dire la « classification en rayons ». Par la force des choses cette procédure est caractérisée par la dispersion radicale des documents en plusieurs classes, c'est le phénomène de la dispersion des sujets voisins. L'éclatement ou l'intégrité des classes dépendent des hiérarchies établies dans les sujets concernés. L' « index relatif alphabétique » mis au point à l'origine par Melvil Dewey est l'instrument principal utilisé pour compenser ce grave inconvénient. Si les documents de la classe « pétrole » par exemple sont dispersés sous des classes comme minéralogie, technologie des combustibles, technologie chimique, mines, etc... ce fait sera au moins mis en évidence par un tel index.
Les difficultés qu'on rencontre pour constituer matériellement des classes (c'est-à-dire pour placer et rassembler dans une classe particulière les documents eux-mêmes) sont sérieusement accrues par le problème de « l'ordre rompu » sous quelque forme qu'on le conçoive; ainsi les documents peuvent être dispersés d'après des critères comme leur format, leur ancienneté, leur forme physique, leur « disponibilité » (certains sont en prêt, d'autres à la reliure, d'autres à la reproduction, à l'atelier de réparation, etc.).
Ces graves lacunes du classement en rayons en tant qu'index des ressources de la bibliothèque dans une classe particulière ont conduit à établir un catalogue. La première fonction de ce type d'index était de donner un état complet des collections de la bibliothèque pour chaque classe par opposition à celui tout à fait incomplet, que donnait le classement en rayons, sujet à des « ordres rompus » continuels et variés. De plus, grâce au « catalogage analytique », il était possible d'établir des vedettes séparées pour les parties distinctes d'un document, si besoin en était.
La seconde fonction du catalogue était de faciliter l'accès aux différentes classes, en d'autres termes, de réduire le plus possible les graves inconvénients présentés par la dispersion des sujets voisins. Donc la deuxième étape marquée dans les progrès de la recherche souple est constituée par l'apparition des catalogues-matières conventionnels qui ont vu le jour au siècle dernier et qui sont à l'heure actuelle mieux définis sous le terme d' « index pré-coordonnés ». Leur caractéristique principale est le caractère conventionnel qu'ils héritent du classement en rayons; ce qui revient à dire que la description d'un document est considérée, pour les besoins de l'indexation, comme un Gestalt, un ensemble de termes intégrés dans lequel les relations entre les termes sont soit explicites soit implicites sans ambiguïté et dont l'ensemble doit être considéré comme entrant dans une sorte de hiérarchie ou de séquence ordonnée, chaque description intégrée étant en relation de subordination ou de collocation avec les autres descriptions.
Ainsi par exemple un document sur la valeur nutritive des feuilles de betterave à sucre utilisées comme engrais peut être placé sous la vedette : Agriculture. Engrais naturels. Betterave à sucre. Feuille. Valeur nutritive (dans un catalogue systématique) ou sous la vedette : Feuilles de betteraves à sucre, en tant qu'engrais (dans un catalogue alphabétique de matières). Dans le premier cas les relations hiérarchiques révélées par les classes voisines seraient à la fois des relations genre-espèce (variétés d'engrais, variétés d'engrais naturels) et des relations de « catégorie » ou de « facette », c'est-à-dire des relations entre chaque terme et ses propriétés, ses parties, ses phénomènes etc. Dans le second cas, les relations seraient des relations de facette similaires (propriétés, phénomènes etc...) ainsi que d'autres concepts « qualifiants » tels des points de vue généraux comme l'Économie, la Botanique, l'Agriculture.
La conséquence la plus évidente de cette convention est, bien entendu, qu'elle maintient la dispersion des sujets voisins. On a pallié ce défaut de deux façons : d'abord par l'élaboration d'une structure de renvois servant à relier les vedettes d'indexation des classes dispersées. Dans le catalogue systématique ce but est atteint (comme dans le cas du rangement en rayons) grâce à l'index relatif, qui signale par exemple que d'autres parties de la classe « betterave à sucre » sont classées sous « récolte des racines ». Dans le catalogue alphabétique de matières, c'est le système des renvois qui montre par exemple que certaines parties de la classe Engrais se trouvent sous des vedettes de récoltes particulières comme la betterave à sucre.
Deuxièmement, il est possible de pratiquer les entrées multiples; dans un catalogue C. D. U. par exemple, il est courant de donner plusieurs vedettes à la même notice, chacune d'elles donnant les éléments principaux de la notice dans un ordre différent. Ainsi une vedette serait établie à Feuilles de betterave à sucre-engrais, et une autre à Engrais-feuilles de betterave à sucre. Ce qui revient à dire que plusieurs classifications différentes sont employées concurremment. De cette façon, le nombre de sujets voisins dispersés est considérablement réduit. Bien qu'ils demeurent encore, ils correspondront généralement à des classes pour lesquelles il est peu nécessaire que tous les éléments soient regroupés. Ainsi pour un rapport sur l'«effet des courants directs sur les ondes de choc en arc obtenues sur les corps obtus dans un courant hypersonique » les éléments suivants seraient probablement cités en premier lieu dans différentes vedettes : Obtus (corps), Hypersonique (courant), Ondes de choc (en arc), Courants (directs). On ne tient pas compte de la possibilité de demandes portant sur tout ce qui concerne les corps, les courants, les arcs, ou les courants directs.
La troisième étape marquée dans l'amélioration de la souplesse de la recherche consiste dans le développement de l'indexation post-coordonnée. Le premier objectif de cette indexation est de faciliter au maximum la correspondance entre les données de la recherche et les vedettes d'indexation. Ces dernières sont traitées simplement comme des ensembles de termes isolés sans aucun rapport de subordination les uns avec les autres. C'est seulement lorsqu'on effectue une recherche que les termes sont réunis (coordonnés) afin de découvrir quels documents ont été indexés sous l'ensemble ou sous la plupart des termes recherchés. Pour une recherche des documents portant sur les « Feuilles de betterave à sucre comme engrais » il ne sera pas nécessaire que le chercheur se demande d'abord si l'engrais est subordonné aux feuilles de betterave à sucre ou vice-versa. Il est aussi facile de chercher une classe que l'autre, la façon dont les termes recherchés sont combinés les uns avec les autres n'entre pas en ligne de compte. Dans un index précoordonné si l'on cherche la classe bdf (chaque lettre représentant un terme) on pourra trouver que cette classe est dispersée en raison de son apparence selon les diverses combinaisons suivantes (l'ordre dans lequel elles sont citées est l'ordre alphabétique) : abdf, abcdf, abcdef, bcdf, bdef, etc. L'index post-coordonné combine bdf seulement lorsqu'une recherche porte sur ces termes et les documents dont la vedette contient (entre autres) ces trois éléments apparaissent du premier coup. La simplicité relative de l'opération de confrontation de la donnée et de la vedette dans l'indexation post-coordonnée a conduit à admettre que cette forme d'indexation était plus favorable à la mécanisation (avec toutes les implications que cette méthode présente dans l'avenir pour réduire les prix de revient). En tout cas, tous les systèmes mécanisés mis sur pied ces dernières années utilisent des index post-coordonnés. Ils fournissent en général plus facilement comme donnée de sortie une liste de numéros de documents, c'est là une de leurs caractéristiques; par conséquent la forme la plus favorable pour la mise en ordre des documents eux-mêmes sera une suite numérique simple généralement fondée sur le numéro d'entrée. Cette conception s'oppose à celle qui a habituellement cours dans les systèmes précoordonnés, selon laquelle le classement en rayons peut encore jouer un rôle utile en montrant les relations qui existent entre les documents et en tenant lieu ainsi d'index supplémentaire. Et pourtant, il n'y a pas de relation nécessaire entre l'organisation du classement en rayons et celle d'un catalogue dans la mesure où ce dernier donne l'emplacement exact de chaque document.
Il est d'importance vitale pour le fonctionnement d'une bibliothèque que les éléments d'information qui sont représentés dans son fonds puissent être décelés facilement et apparaissent sous une forme qui se prête à une recherche souple. Sinon, l'accès à l'information est gravement entravé. Les bibliothécaires reconnaîtront que les trois étapes ou niveaux d'accès décrits ci-dessus ont contribué à la solution de ce problème. Nous devons en particulier examiner le rôle joué au stade de l'indexation par la coordination limitée et sélectionnée des termes et par leur agencement en ordre hiérarchique, nous devons également voir dans quelle mesure la confiance accordée à la coordination libre au stade de la recherche permet un accès lui aussi plus libre.
Classement en rayons (des documents eux-mêmes).
C'est une tendance commune de ne pas faire de cette opération une méthode d'indexation, en particulier dans les bibliothèques scientifiques et techniques, en partant du principe que le format matériel de la plupart des documents - et en particulier la présence parmi eux de nombreux périodiques - l'interdit.
Cependant, bien qu'on ne puisse considérer cette opération comme l'instrument principal, son importance est peut-être sous-estimée. Dans la mesure où de nombreuses bibliothèques (même spécialisées) fonctionnent, dans une certaine mesure, comme des magasins en « self service », le classement systématique des fonds peut révéler en toute clarté le contenu d'une large proportion des classes principales sur lesquelles porte la recherche courante. Cette méthode permet de satisfaire une part importante des demandes quotidiennes sans compter le gros avantage que représente l'accès immédiat aux documents. Cette situation est typique par exemple d'une multitude de bibliothèques et de collections concernant l'architecture et le bâtiment. Cependant le classement en rayons souffre irrémédiablement des désavantages présentés par la dispersion des sujets voisins. Il ne rassemble le contenu total d'une classe que dans le cas où le nombre des classes est très limité. Lorsqu'on désire réunir les diverses parties d'une classe qui est matériellement dispersée par le classement en rayons, on ne peut le faire que par l'intermédiaire du catalogue.
L'index précoordonné.
L'élément fondamental de cet index est la sélection de certains aspects d'un sujet pour déterminer une classe initiale et l'emploi des autres aspects pour caractériser les sous-classes en subordination. C'est ainsi qu'un sujet comme « les insectes nuisibles pour les graines stockées » peut être affecté à la classe « Documents relatifs aux graines », à la sous-classe « Stockage des graines », à la sous-sous-classe « Détérioration des graines en stockage » et finalement à « Détérioration par les insectes des graines en stockage ». Des subordinations de ce type sont la caractéristique essentielle des systèmes « hiérarchisés » qu'on emploie fréquemment dans les index pré-coordonnés soit pour le classement en rayons soit pour les catalogues. Mais le terme « hiérarchie » est un terme ambigu quand on traite de l'indexation. Dans son sens le plus étroit il se réfère à l'organisation des termes en ordre hiérarchique de genres et d'espèces (des choses et de leurs catégories). Les exemples les plus évidents de cet ordre peuvent se trouver dans les facettes des systèmes de classification modernes.
De façon plus large on peut, par hiérarchie, entendre, au-delà des relations entre termes à l'intérieur d'une facette, les relations entre les termes de la facette et le terme auquel se rapporte la facette ou la catégorie. Ainsi, par hiérarchie, on peut entendre non seulement les relations entre le genre « navigation aérienne » et les divers types (espèces) de navigation aérienne mais aussi les relations entre la « navigation aérienne » et la branche mère qu'est « l'aéronautique » dans laquelle d'autres facettes se trouvent en relations diverses les unes avec les autres - types de navigation aérienne, opération de vol, propriété des fluides, formes des corps aérodynamiques, etc.
Le but de la mise en ordre systématique des termes en de telles hiérarchies est de fournir une méthode constante offrant continuellement la possibilité de traiter « mécaniquement » les classes. A l'intérieur d'une facette (hiérarchie stricte genre-espèce) une classe peut être développée ou réduite par le haut, par le bas ou par les côtés pour englober des classes coordonnées ou collatérales. Ou bien encore des classes peuvent être aménagées en transformant une catégorie d'un terme en une autre (ex. : transformation des propriétés thermiques en phénomènes thermiques) ou en transformant un terme auquel est affecté un certain rôle en un même terme auquel sera affecté un autre rôle (ex. : transformation de la substance X comme substance de mise en marche en X comme catalyseur ou en X comme produit).
La facilité et l'assurance avec lesquelles on pratique de tels aménagements des classes soumises à la recherche dépendent en grande partie de la cohérence et de la précision (c'est-à-dire de la spécificité de la vedette) avec lesquelles l'index a été établi. Les classifications modernes à facettes ont largement contribué à ce résultat; la méthode analytico-synthétique permet d'aboutir à des vedettes matières très précises (grâce à la synthèse de tous les termes élémentaires requis quels qu'ils soient) tout en observant des règles claires et cohérentes dans l'ordre de classement des facteurs. En conséquence, la prévision - autrement dit la connaissance exacte de la place à laquelle une classe particulière sera trouvée - a été grandement facilitée.
Ces qualités de cohérence et de prévision que présente l'index précoordonné sont, dans une large mesure, une contrepartie nécessaire au grave inconvénient de cet index que nous avons mentionné précédemment : il disperse les informations apparentées quand le sujet recherché englobe des termes qui ne sont pas toujours cités ensemble. Ainsi les facilités d'accès à un sujet donné dépendent en grande partie de la place qu'occupent les termes recherchés dans la hiérarchie, selon qu'ils sont des termes cités en premier ou des termes subordonnés à d'autres.
On a déjà mentionné le rôle de l'index relatif alphabétique pour montrer avec exactitude quelles combinaisons de termes sont représentées dans une collection. L'expérience a montré cependant que dans des index importants et spécialisés portant sur les sciences et les techniques il se trouve un moment où cette méthode qui permet de déceler les sujets voisins dispersés devient difficile à utiliser. Prenons comme exemple une recherche sur la classe « Fatigue (dans les) soudures » qui se trouve dispersée. Ces deux termes peuvent apparaître dans un nombre important de combinaisons diverses; en consultant l'index relatif alphabétique au mot « Fatigue » on peut trouver entre 100 et 200 fiches différentes qui représentent diverses classes dans lesquelles figure le sujet « Fatigue ». Toutes ces fiches doivent être triées pour voir lesquelles d'entre elles comportent également le sujet « soudure ». Et ces fiches ne sont encore que des renvois, les vedettes des documents doivent elles-mêmes être examinées séparément dans un second temps.
Une solution à ce problème, nous l'avons vu, est la méthode des « entrées multiples », c'est-à-dire qu'on multiplie les vedettes pour un élément (document) et qu'on les classe selon les ordres différents dans lesquels elles sont citées. Cette solution semble satisfaisante tant que le nombre des éléments qui viennent en tête de la vedette par le jeu des mutations de l'ordre de classement initial ne dépasse pas quatre ou cinq. Mais ceci laisse encore un certain nombre de sujets voisins dispersés; par exemple une notice qui comprend 4 termes dont l'ordre de citation initial est abcd peut conduire aux entrées abcd, bcda, cdab, dabc. Mais les combinaisons particulières ac et bd seraient encore dispersées, c'est-à-dire que si l'on cherche par exemple ac dans l'index systématique d'après le premier ordre de classement (abcd) on trouvera des combinaisons variées de a et de c dispersées par subordination sous abIc, ab2c, etc... (dans ces exemples bI et b2 sont d'autres termes dans la facette dont b est un membre). Le même phénomène se produira quel que soit l'ordre de classement sous lequel on aura cherché. Donc de 8 combinaisons possibles (2(4-1)), 2 sont encore dispersées. Les solutions qui permettront d'éviter complètement la dispersion dans un index précoordonné sont discutées avec clarté et exhaustivité dans un ouvrage récent publié par John R. Sharp (Référence I).
Si l'on pratique les entrées multiples pour éviter toute dispersion, le nombre d'entrées requises s'élève très rapidement dès que le nombre des éléments d'une notice est supérieur à 5. Sharp relève que toutes les combinaisons possibles des éléments d'une notice incluant 4 éléments sont couvertes par 8 entrées (2(4-1)) ou dans une notice de 5 éléments par 16 entrées (2(5-1)). La formule générale pour une notice de n termes est 2(n-1)). Cependant cela implique que tous les éléments d'une notice valent la peine qu'on s'en occupe. Or, dans la plupart des bibliothèques spécialisées, il n'y a qu'un nombre limité de combinaisons sur lesquelles porte la majorité des recherches, le reste faisant l'objet de recherches relativement rares. Sur ce point les indications peuvent être évaluées de façon mathématique (ex : le test portant sur l'index C. D. U. dans le premier projet Aslib/Cranfield) et elles amènent à penser que la multiplication modérée des entrées, telle qu'elle se pratique dans de nombreux centres utilisant la C. D. U. (de 3 à 6 entrées pour chaque document en faisant varier l'ordre des facteurs), s'avère efficace et que l'on peut raisonnablement se satisfaire de ce qui reste de sujets dispersés.
Une autre méthode pour accroître les facilités d'accès dans un index précoordonné est celle qui est exposée dans le test du W. R. U. System (Référence 2) dans le Projet Aslib/Cranfield. Ce test contient une comparaison avec l'index classifié de l' « English Electric Company » qui utilise une nouvelle classification à facettes; cet index a en moyenne 12 entrées par document, y compris la sélection de différents termes et la mutation des facteurs pour certains d'entre eux, c'est ainsi que des entrées peuvent être faites pour abcd, bcda, cde, ege. Cet index s'avère satisfaisant pour la précision de la recherche qu'il effectue avec une facilité évidente : programmation des questions et recherche - qu'il s'agisse des sujets dispersés ou du reste de l'information - sont généralement l'affaire de quelques minutes.
Index post-coordonnés.
Nous avons déjà indiqué que l'objectif principal de ces index est de faciliter au maximum la confrontation des données de la recherche et des vedettes de l'index. Sur ce point ils se révèlent d'une admirable efficacité. En supprimant la subordination d'un terme à un autre ils résolvent le problème de la dispersion dans l'index. N'importe quelle combinaison de termes peut être confrontée aux vedettes sans plus de difficultés pour l'une que pour l'autre. Un élément important de ce type d'index est que le nombre des termes qu'il est possible d'assigner à un document est de beaucoup plus important que dans le cas d'un index précoordonné. Ce qui revient à dire qu'une indexation plus exhaustive qu'on ne l'avait jamais connue devient concevable. On entend par là que tout élément significatif d'un document est indexé par opposition à l'attribution au thème général d'un document d'une seule vedette d'ensemble qui forme un tout. Disons en forçant les mots que cela revient à comparer le titre général d'une monographie technique (qui représente la vedette matière principale conventionnelle) avec le détail analytique des divers thèmes du livre tel qu'il se présente dans son index alphabétique. Le catalogage analytique a été de tous temps une caractéristique de l'indexation conventionnelle, c'est ainsi qu'un volume de mélanges recevra souvent des entrées distinctes pour chacun des chapitres qui le constituent. Un ouvrage dont le contenu porte sur plusieurs zones de la classification employée peut avoir plusieurs entrées, ainsi un traité d'anthropologie peut dans un index C. D. U. avoir une entrée à 9I (voyages et description des pays), à 4 (linguistique), à 2 (religion), à 39 (anthropologie sociale) et ainsi de suite.
Dans une certaine mesure, cette méthode a été limitée par la nature même des ouvrages qui, en raison de leur caractère assez général, relèvent de classes bien définies dont le contenu est relativement facile à prévoir. On sait par exemple que des études d'anthropologie portant sur une société primitive ou restreinte contiendront des éléments sur sa structure sociale, ses habitudes économiques, sa religion, sa langue, etc. De même le contenu détaillé d'un traité portant par exemple sur les chaudières à vapeur peut être exactement prévu et ne réclame pas d'être indexé sous diverses entrées.
Les liens entre la description générale (telle qu'on la trouve dans un titre d'ensemble) et le contenu détaillé ont tendance à être moins évidents dans le cas de périodiques et de rapports techniques ou scientifiques. Dans un domaine spécialisé comme l'aérodynamique, il y a des chances pour que des contributions intéressantes sur des problèmes particuliers apparaissent dans un grand nombre d'articles isolés. Par exemple, un rapport sur la situation des courants autour des ailes delta aux vitesses supersoniques peut traiter abondamment des problèmes des tourbillons. Mais les tourbillons ne peuvent cependant être considérés comme étant essentiellement un aspect des courants supersoniques sur les ailes delta car on les trouvera cités dans de nombreux autres contextes différents. On peut dire que la délimitation des sujets est plus difficile dans ce cas que dans celui des études présentées sous forme d'ouvrages.
Si, pour faire face à cette situation, on s'attache à pratiquer l'indexation « en profondeur », le système post-coordonné présente trois avantages. Premièrement l'affectation simple de termes isolés (pris dans le titre, le résumé ou le texte) pour représenter un document est une méthode plus commode que l'affectation de ce termes à des ensembles précoordonnés sélectionnés. Deuxièmement l'accroissement matériel du fonds n'est pas une éventualité intolérable; dans les systèmes où les entrées se font par termes, en particulier, c'est à peine un problème. Troisièmement, l'accroissement du nombre des vedettes n'est pas une entrave à la commodité de confrontation des données. En revanche, l'accroissement matériel de l'index précoordonné peut atteindre des proportions qui le rendent impraticable. Nous avons déjà évoqué le besoin que l'on a dans un tel index de multiplier chaque entrée de trois à cinq fois si l'on veut réduire le problème des sujets voisins dispersés à des proportions supportables. Or, c'est de 5 à 10 fois qu'il faudrait la multiplier pour obtenir dans l'indexation une exhaustivité égale à celle qu'on obtient dans un système post-coordonné en affectant à un document 30 à 50 termes (certains systèmes en affectent d'ailleurs d'avantage).
Deux points doivent être soulignés : d'une part la vedette moyenne d'un système précoordonné représente un nombre de termes beaucoup plus considérable qu'on ne lui en prête dans la pratique; ainsi le seul indice C. D. U. 576. 354. 465 conduit au sujet représenté (la division de la cellule) en passant par les termes suivants : biologie, vie, génétique, organismes, cytologie, cellules, reproduction, multiplication (biologique), meiosis, synapsis, chromosomes, accouplement, division (reproduction de la cellule), en tout au moins 13 termes. Ceci tend à affaiblir l'argument présenté au paragraphe précédent. Mais d'autre part, la répétition des mêmes termes dans différentes précoordinations - qu'implique la recherche de l'exhaustivité - va dans le sens contraire et accroît la probabilité d'une multiplication des entrées; ainsi, si abcde sont les termes qui décrivent un document et si l'on accroît l'exhaustivité de la description en ajoutant les termes supplémentaires fghij, si fghij représentent un élément d'information bien distinct, l'accroissement des entrées requises sera simplement doublé. Mais, si certains éléments de l'ensemble des termes ajoutés sont également cités conjointement à des éléments de l'ensemble primitif, les chiffres sont plus que doublés - dans le cas par exemple de combinaisons abcfg, cdegh, etc... Prenons comme exemple un rapport sur l'influence des courants directs sur les ondes de choc en arc dans lequel la plupart des expériences décrites sont faites avec des courants d'air, supposons que l'indexeur ajoute le terme hélium (comme autre courant de gaz) parce qu'on en parle aussi dans le rapport; l'accroissement des entrées sera plus grand en proportion puisque chaque vedette mutante (multipliée) qui contient le terme « courant d'air » sera maintenant répétée en lui substituant le terme « courant d'hélium ».
Nous pouvons résumer ainsi la démonstration : l'avantage principal de la post-coordination sur la précoordination est que cette dernière entrave la procédure de la recherche en laissant subsister la dispersion; la post-coordination n'a pas ce défaut. De plus, si un index précoordonné peut dans une certaine mesure pallier ses inconvénients par la méthode des entrées multiples, ceci n'est possible qu'à une échelle limitée, en particulier il ne lui est pas possible de conjuguer les entrées multiples avec une indexation exhaustive.
La commodité de confrontation des données du problème avec les notices du document se situant au cœur même du problème de l'indexation et de la recherche, cette exigence semble assurer la supériorité de l'index post-coordonné sur la forme précoordonnée. Mais en réalité cette conclusion ne peut être acceptée qu'avec de sérieuses réserves selon les conditions dans lesquelles l'une ou l'autre forme d'index sera utilisée. En premier lieu, dans la plupart des cas, le produit de la confrontation entre la donnée de la recherche et les vedettes d'indexation dans un système post-coordonné est une simple liste de numéros de documents. Elle représente un ensemble de documents dont on suppose qu'ils valent la peine d'être examinés. Il s'agit maintenant de les rassembler alors qu'ils sont disséminés sur les rayons et de les examiner avant de pouvoir dire si cette supposition était valable. Si, comme il arrive fréquemment, les documents examinés ne donnent pas tous satisfaction, la recherche doit être rectifiée (reprogrammée) et il faut entreprendre une nouvelle procédure de confrontation des données suivie du regroupement et de l'examen d'unités dispersées plus nombreuses. S'il est nécessaire que la reprogrammation soit souple et judicieuse, elle demandera que soient connus les relations et les termes inclus, ainsi si la recherche porte sur l'utilisation de l'hélium comme gaz expérimental, il est évident qu'il faut connaître les autres gaz semblables. En d'autres termes, il est là encore nécessaire d'avoir une sorte de schéma ou de classification du domaine étudié.
La faculté de mener de front ces diverses relations lors d'une recherche est un élément important de succès. S'il est vrai qu'un index post-coordonné peut tenir compte de ces relations par l'intermédiaire d'un thesaurus ou d'un plan de classification, il est important de voir avec quelle rapidité un chercheur expérimenté peut se tirer d'affaire avec un index précoordonné bien construit. Bien qu'on n'ait pas encore étudié de près ni mesuré avec exactitude le temps et l'argent dépensés dans l'utilisation matérielle des index (de là découle le caractère de généralité que revêt la discussion dans cet article) on reconnaît unanimement que la rétroaction immédiate et continue qui permet à un chercheur d'explorer rapidement et complètement les hiérarchies d'un index précoordonné constitue un avantage important de cette forme d'index.
De tels systèmes sont des systèmes à entrée unique (c'est-à-dire qu'une seule vedette représente un élément documentaire) dans lesquels le document est décrit brièvement par auteur, titre, date et notes ou analyses en plus de la vedette d'indexation (vedette de sujet); c'est là un facteur important. Il facilite beaucoup le choix des documents à examiner en permettant de faire un premier tri. A ce niveau de la recherche c'est le système post-coordonné qui subit le plus les préjudices des sujets dispersés car il oblige à rassembler les documents dispersés pour les trier.
Il est peut-être injuste de juger les index post-coordonnés sur la foi de systèmes qui techniquement ne sont pas encore au point, mais quand des chiffres ont été donnés pour décrire leurs opérations (dans le National Science Foundation guide to non-conventional systems, par exemple) ( Référence 3), il faut bien reconnaître que le temps dépensé pour une recherche excède généralement de beaucoup celui qui paraît souhaitable à la plupart des bibliothécaires. D'autre part on trouvera dans le rapport Aslib/Cranfield sur le système W. R. U. (Référence 2) des preuves de la rigidité plus grande que présente le système post-coordonné pour les opérations de recherche.
Dans ce système, les programmes de recherche ont été tracés avec beaucoup de soin puisqu'ils étaient conçus de façon à prévoir toute éventualité. Par contre, l'index précoordonné de l' « English Electric » (qui utilise une classification à facettes) est consulté avec une souplesse bien plus grande. Le temps moyen mis pour programmer une question dans le système (mécanisé) du W. R. U. est de 4 heures, dans l'index précoordonné E. E. il est de moins de 4 minutes. Encore une fois, il ne serait pas juste de prétendre que cet exemple est représentatif. Le système d'indexation du W. R. U est en effet d'une minutie inhabituelle (et pour la recherche elle-même, la machine électronique est d'une lenteur inhabituelle). En outre le développement de systèmes « interactifs » dans lesquels la rétroaction est plus rapide et plus complète réduira éventuellement la différence entre les temps. Mais la majorité des bibliothèques n'auront de tels systèmes à leur disposition que dans un avenir encore bien lointain.
Il semblerait donc qu'en dépit de l'accès théoriquement supérieur des index post-coordonnés c'est une méthode qui s'avère dans de nombreux cas moins efficace que la précoordination. Elle est en particulier moins efficace tant que le nombre moyen des termes utilisés dans la vedette d'indexation reste assez modeste pour permettre d'établir des entrées multiples adaptées aux besoins d'une bibliothèque donnée. Quand je dis « modeste », j'entends un nombre de termes qui permette une description parfaitement spécifique du sujet et du document pris dans son ensemble.
La précoordination répond aux nombreux services qu'on peut attendre d'un index (du classement systématique en rayons à toute recherche, dans le catalogue, de la plus simple à la plus spécifique) sous une forme immédiatement accessible et immédiatement parlante. De plus, elle demeure valable pour un grand nombre de recherches faites couramment dans un catalogue de bibliothèque. La situation la plus fréquente est celle où un lecteur demande rapidement une sélection des documents les plus pertinents sur un sujet au lieu de tout ce que la bibliothèque a pu rassembler en tout genre sur ce sujet. En d'autres termes cette situation appelle un travail de sélection approfondie (précision) plutôt qu'un recensement exhaustif. A noter que le terme « recensement » correspond à la proportion des documents pertinents effectivement trouvés et le terme « précision » (pertinence) au nombre de documents pertinents trouvés proportionnellement au total des documents trouvés (dont un grand nombre ne relèvent pas du tout de la question posée).
Quand on a besoin d'un recensement exhaustif nous avons vu que l'index précoordonné souffre de son incapacité à assurer à la fois une indexation exhaustive et des entrées multiples, c'est-à-dire que si l'on multiplie les entrées ce sera aux dépens de l'accessibilité. Cependant la question d'une indexation largement exhaustive, condition nécessaire d'un recensement exhaustif, demande à être examinée de plus près.
Il existe deux méthodes qui permettent un recensement exhaustif. D'abord au moyen d'une indexation exhaustive du genre de celle dont on a parlé précédemment. Prenons par exemple une collection portant sur l'aérodynamique dans laquelle un rapport présente une contribution sur un type particulier d'expérimentation de tunnel aérodynamique pour laquelle on se sert d'une caméra à grande vitesse. Cette contribution n'est qu'un élément mineur du rapport, cependant, indexée, elle sera retrouvée si une question est posée, qui porte directement sur ce sujet (celui d'une forme particulière d'expérience). Si elle n'est pas indexée, il y a toutes chances pour qu'elle ne soit pas retrouvée : on peut concevoir en effet que cette expérience puisse porter sur des phénomènes très divers de l'aérodynamique et il n'y aura pas moyen de deviner quel rapport particulier renferme la description de cette expérience et par conséquent pas moyen de deviner quelle classe il faut examiner. En second lieu, un recensement exhaustif est assuré par une recherche à grande échelle des documents. Supposons par exemple que l'indexeur du document dont il a été question précédemment ait tenu compte de la présence de l'information sur l'expérience particulière en question en incluant seulement le terme « expérience » dans sa vedette. Le document pourra être retrouvé si les chercheurs sont disposés à examiner de près tous les documents qui contiennent ce mot dans leur notice. Évidemment une telle méthode aura pour prix une précision beaucoup moins grande, ce qui signifie qu'il faudra trier un nombre plus élevé de documents sans rapport avec le sujet pour trouver celui qui convient.
Il est également évident que la recherche à grande échelle des documents est indépendante du système d'indexation utilisé, c'est au chercheur de décider s'il a ou non le temps et le besoin de pratiquer une recherche à grande échelle. Mais là où une recherche est étendue, l'organisation hiérarchique du catalogue traditionnel a des chances d'être plus utile dans de nombreuses occasions, dans la mesure où son classement lui-même est hiérarchique et où le principe d'une entrée par document permet un tri rapide.
La troisième considération qui doit être faite est d'ordre général : c'est que la plupart des collections ne peuvent en aucun cas représenter la totalité de la production sur un sujet donné. Dans ces circonstances l'indexation supplémentaire qui permettra d'exprimer jusqu'à la dernière goutte de la collection disponible vaut-elle la peine d'être faite ? Si la nécessité de pratiquer une recherche vraiment exhaustive est relativement peu fréquente, il peut être plus économique d'assumer le coût supplémentaire occasionné par une recherche exhaustive occasionnelle plutôt que celui d'une indexation exhaustive continuelle.
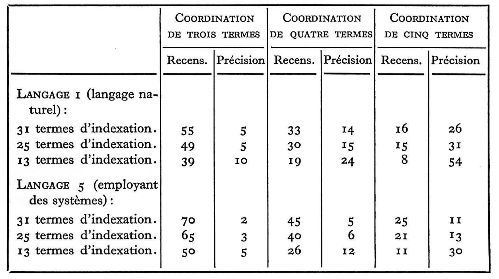
Sur ce problème de l'indexation exhaustive et de la recherche à grande échelle, des chiffres provisoires donnés par le projet Aslib/Cranfield présentent un intérêt certain. Le tableau ci-dessous donne des chiffres de « recensement » et de « précision » (pertinence) à 3 niveaux d'exhaustivité appliqués à deux langages d'indexation différents, combinés à 3 degrés différents de coordination. Le Projet en question tente de mesurer les résultats en recensement et en précision de différentes techniques d'indexation. Les chiffres donnés sous le langage 1 ci-dessous expriment les résultats obtenus par le « langage naturel » pour l'indexation et la recherche, c'est-à-dire que dans ce cas on n'a en aucune façon adapté les termes employés dans les documents eux-mêmes ou dans les questions posées; en d'autres termes on n'a utilisé aucune technique d'indexation si ce n'est la réduction de l'ensemble du texte à une série abrégée de termes, ce qui est le propre de toute indexation. A cette forme la plus brute de l'indexation on a ajouté divers systèmes d'indexation (qui définissent des classes) et on a mesuré leurs résultats en fonction de leur efficacité.
Le langage 5 représente l'addition de plusieurs systèmes d'indexation élémentaires : contrôle des synonymes, fusion des formes différentes du même mot (réfrigérant, réfrigéré, réfrigérateur) et des « quasi-synonymes » (termes ambigus qui sont synonymes dans certains contextes et non dans d'autres, ex. : vol + courant).
Le tableau montre 3 degrés différents d'exhaustivité : le niveau 1 représente l'emploi d'une moyenne de 31 termes par document, le niveau 2 représente l'emploi de 25 termes et le niveau 3 celui de 13 termes (ce qui correspond en gros par exemple à un indice C. D. U. de longueur moyenne). Le degré de généralité d'une recherche est représenté par le degré de coordination c'est-à-dire par le nombre de termes recherchés ensemble; une demande portant sur des documents qui ont quatre termes d'indexation en commun est manifestement quelque chose de plus précis qu'une demande pour des documents qui n'ont que trois termes en commun; autrement dit c'est comme si l'on cherchait dans un index C. D. U. 633.63 : 631.8 (betterave à sucre - engrais) plutôt que 633.63 seulement. Les chiffres (en chiffres ronds) sont fondés sur un échantillonnage de 35 questions (contenant toutes 7 termes afin de contrôler cette variable particulière) auxquelles on savait que répondaient 287 documents sur un total de 1 400. L'efficacité relativement modeste est due en partie au fait que délibérément on a presque totalement négligé à ce niveau de faire une discrimination ou d'exercer son sens critique en établissant les programmes de recherche, les termes de chaque question ont été pris dans la forme même dans laquelle on les avait reçus.
Le point important à observer dans l'optique de notre sujet est que, malgré l'influence incontestable d'une exhaustivité supérieure sur le recensement à n'importe quel degré de généralité de la recherche (degré de coordination), pour le recensement, le même résultat, ou peu s'en faut, peut être obtenu en demandant un terme de moins au niveau de la coordination, c'est-à-dire en élargissant la recherche.
Ainsi, en coordonnant 5 termes en même temps on obtient un recensement à 25 % quand on indexe de façon exhaustive (31 termes) et seulement à II % quand on indexe moins exhaustivement (13 termes). Mais si l'on ne demande que 4 termes à la fois une indexation exhaustive donne un recensement à 45 % et une indexation moins exhaustive un recensement à 26 %, c'est-à-dire un degré supérieur à celui que donne une indexation exhaustive à un niveau de coordination supérieur (en donnant une précision plus grande à la recherche). De la même façon, la coordination de 3 termes avec une indexation non exhaustive donne un recensement à 50 % tandis que la coordination de 4 termes donne un recensement à 45 % avec une indexation exhaustive.
Il semble qu'il faille également attirer l'attention sur un second point. On a vu précédemment que les systèmes post-coordonnés passent souvent pour être davantage adaptés à la mécanisation que les systèmes traditionnels. A coup sûr, la simple corrélation ou la confrontation de termes simples, sans les subtilités de la subordination et de l'ordre de citation, convient tout à fait aux systèmes mécanisés tandis que la capacité des chercheurs humains pour examiner très rapidement les parties sélectionnées d'un classement ou d'un index classifié suppose généralement que de tels moyens mécaniques ne sont pas nécessaires. Mais d'un autre côté, les index conventionnels sont parfaitement susceptibles de bénéficier de la mécanisation. Les ouvrages de Rigby aux États-Unis (Référence 4) 1 et d'autres auteurs dans d'autres pays ont prouvé qu'il était possible d'utiliser un équipement à cartes perforées et des machines pour élaborer et mettre rapidement à jour des plans de classification aussi bien que des index proprement dits, avec ou sans mutation des entrées, sous forme de livre. De cette façon les avantages que présentent une consultation et une rétroaction rapides sont augmentés.
En conclusion, il ne faut pas oublier que nombreux facteurs doivent être présents à l'esprit avant de pouvoir décider quel type de système d'indexation est le plus approprié à une situation donnée. L'importance du fonds, son accroissement probable, les sujets qu'il recouvre, son aspect matériel, le type de lecteurs, le genre des questions qui sont habituellement posées et le genre de questions qui peut être posé seulement de façon occasionnelle, la célérité avec laquelle on attend les réponses, le genre de résultat qu'on attend généralement (recensement large ou haute précision), tous ces facteurs et d'autres encore influenceront la réponse au problème posé. Certains d'entre eux amèneront à penser que le système précoordonné est la meilleure réponse, d'autres que c'est le système post-coordonné. Le choix que nous ferons devra être éclectique, chacun de ces systèmes a des avantages et des inconvénients non négligeables et la réponse en plusieurs cas pourrait être que les deux systèmes sont nécessaires.
Ce qu'il est nécessaire d'avoir maintenant ce sont des données objectives qui détermineront la décision à prendre. La pertinence et le coût des différents systèmes (coût étant compris dans son sens le plus large et représentant le temps et la compétence requis pour élaborer et tenir à jour les index, préparer et effectuer les recherches, retrouver les documents, etc...) doivent être examinés d'aussi près que le problème de l'évaluation des résultats actuellement à l'étude.
Références
(1) SHARP (John R.). - Some fundamentals of information retrieval. - London, Deutsch, 1965. - 224 p.
(2) AITCHISON (Jean) et CLEVERDON (Cyril). - A Report on a test of the index of metallurgical literature of Western Reserve University. - Cranfield (Bedford), College of Aeronautics, 1963. - XII-270 p.
(3) National Science Foundation. Washington. - Non-conventional technical information systems in current use. No 3. - Washington, N. S. F., 1962.
(4) FREEMAN (Robert R.). - Computers and classification systems. (In : Journal of Documentation, Vol. zo, no. 3, September 1964.)