Des mots-clés aux phrases-clés
Les progrès du codage et l'automatisation des fonctions documentaires
Paul Braffort
André Leroy
I. Introduction.
L'accroissement exponentiel du volume de la littérature scientifique et l'interconnexion croissante des disciplines ont pour effet d'augmenter la complexité des problèmes de classement « matières » des documents. Aussi assiste-t-on à de nombreuses tentatives pour améliorer les systèmes classiques.
D'autre part, la nécessité de procéder à l'automatisation des fonctions documentaires, nécessité qui se manifeste aujourd'hui d'une manière impérieuse, contribue à faire évoluer les idées quant à la conception d'un système efficace et à l'estimation quantitative de cette efficacité.
Des études de ce genre sont importantes pour une documentation atomique qui puise ses informations dans presque tous les domaines scientifiques et techniques. Nous voudrions dans cet article, après une brève revue des principales méthodes de classement utilisées, dégager les tendances qui se manifestent dans les perspectives nouvelles de l'automatisation. Nous arriverons ainsi à la notion fondamentale de phrase-clé et aux conséquences qui en découlent pour la sélection
II. Échec des classifications.
Les classifications scientifiques ont une origine très ancienne et ont par conséquent reçu depuis les temps les plus reculés des applications très diverses. Les deux principales applications ont été et demeurent la recherche scientifique et l'enseignement. C'est ainsi que dès les premiers balbutiements de la Science on a distingué la Mécanique, la Médecine, la Musique, etc... Au sein de chaque discipline ayant acquis droit de cité les classifications ont joué un rôle important pour grouper les faits et donner une matière à la réflexion théorique : c'est le cas notamment dans les Sciences naturelles
Dans le domaine de la recherche bibliographique il en va tout autrement. Les classifications scientifiques sont en effet limitées en général à un nombre de rubriques relativement petit; elles ne sont donc commodément utilisables que pour ranger des documents en petit nombre, comme c'est le cas pour les ouvrages pour les bibliothèques de taille moyenne. Si l'on veut classer des dizaines de milliers de documents ou davantage de façon significative, il faut évidemment disposer d'une classification aux nombreuses rubriques et sous-rubriques. Cette différence quantitative est la clé de la différence qualitative qui saute aux yeux lorsqu'on compare les systèmes d'Aristote, de Bacon, de Comte, d'Ampère, etc... avec les grandes classifications documentaires du type de la classification décimale universelle.
Ce défaut des systèmes de classification pour les applications à la recherche documentaire n'est plus depuis quelques années le plus important, car le principe même d'un système de classification pose la possibilité d'établir une hiérarchie des disciplines suivant la forme d'un « arbre » (au sens de la théorie des graphes (1) 1). Or on sait que les disciplines mixtes, les activités scientifiques « obliques » ont définitivement transformé cet arbre en un système aux boucles multiples, aux corrélations innombrables. C'est ce que constataient récemment R. Queneau (2) et J. PIAGET (3).
Ces incompatibilités profondes expliquent le recul rapide du système décimal universel au cours de ces dernières années et plus récemment l'apparition de nouveaux systèmes documentaires présentant une structure sensiblement différente et auxquels il est plus normal de donner le nom de langages que celui de systèmes de classification.
III. Mots-clés, relations, languages documentaires.
Il suffit de jeter un coup d'œil sur une classification du type Ampère ou sur un système comme la CDU pour constater que de tels systèmes se présentent matériellement sous la forme d'un vocabulaire et d'une typographie. Les rubriques sont dénotées par des mots et ces mots sont rangés les uns par rapport aux autres suivant une certaine structure algébrique formant un arbre doué d'une symétrie plus ou moins grande.
Analyser un article suivant une telle classification revient à remplacer les mots du langage ordinaire par des chiffres, la convention d'écriture de ceux-ci servant à exprimer la hiérarchie des rubriques (4).
La réaction naturelle contre les excès des formalismes classificatoires a été l'emploi des mots-clés rangés dans un ordre quelconque, en général l'ordre alphabétique de ces mots, lorsqu'ils sont exprimés dans un langage déterminé. Ce type de rangement est couramment utilisé par les ingénieurs et les chercheurs pour leur fichier personnel; il a le gros avantage de ne réclamer l'apprentissage d'aucun formalisme artificiel. Nous sommes donc ici en présence d'un vocabulaire et d'une convention de rangement.
Mais une nouvelle difficulté est rapidement apparue, elle est la conséquence de phénomènes de polysémie, fréquents notamment en chimie et dans les disciplines voisines. C'est ainsi que le mot-clé « fer » peut être pris dans des acceptions fort différentes qu'il est indispensable de pouvoir distinguer. On a donc été amené rapidement à compléter les mots-clés en les faisant suivre de parenthèses comprenant elles-mêmes d'autres mots-clés, ce qui donne un résultat tel que :
Fer (dans les composés organiques);
Fer (mines de -);
Fer (à repasser).
Nous sommes ici en présence d'un vocabulaire complété par une convention syntaxique. Des systèmes de ce genre sont souvent utilisés aux États-Unis sous le nom de « subject-headings ». De nombreux organismes en font usage, notamment l'USAEC (United States Atomic energy commission) (5).
Mais si l'on examine d'assez près ces « subject-headings », on s'aperçoit que l'ensemble des mots-clés qui les composent comprend deux classes : celle des mots figurant dans les parenthèses étant beaucoup plus restreinte que l'autre, étant plus précisément constituée d'actions, de notations hiérarchiques, etc... C'est en effet ici qu'apparaît le rôle des relations. Les mots-clés ne sont pas suffisants, il faut leur adjoindre un certain nombre d'éléments purement relationnels, obtenant ainsi l'ensemble d'un vocabulaire et d'une syntaxe, c'est-à-dire un véritable langage. De ce point de vue tous les systèmes documentaires sont des langages, le vocabulaire apparaît sans peine. Pour la syntaxe, il est parfois plus malaisé de la mettre en évidence; dans les classifications traditionnelles elle permet d'exprimer uniquement les relations Ihiérarchiques, alors que dans le système des « subject-headings » elle permet d'exprimer des structures adjectivales ou verbales :
Fer (alliage de -);
Fer (dilatation du -).
On conçoit sans peine comment un véritable langage puisse être utilisé pour l'analyse documentaire en ajoutant au vocabulaire traditionnel des rubriques un arsenal de plus en plus considérable de relations syntaxiques. A la limite, on en arrive au résumé classique comportant plusieurs centaines de mots.
Mais on sent bien que cette dernière méthode est coûteuse et en réalité extrêmement redondante : on a besoin d'un véritable langage, mais pas de tout le langage. Le problème est donc de trouver une solution optimale.
IV. Les stratégies documentaires et la recherche d'un langage optimal.
Nous avons évoqué dans les paragraphes précédents des raisons de commodité et d'efficacité pour justifier l'adoption d'un système linguistique à la place des classifications traditionnelles. Devant l'abondance des solutions proposées (souvent avec quelque insistance) par les divers auteurs, il est indispensable de disposer d'une méthode objective pour l'évaluation de ce qu'on pourrait appeler des stratégies de recherche documentaire (6).
En fait, ce problème d'évaluation et de recherche d'une solution optimale ne se pose pas que dans le domaine de la codification de l'information scientifique contenue dans les documents; elle se pose aussi, nous le verrons plus loin, pour le choix du matériel de sélection automatique de ces documents. Automatique ou non, la recherche des documents peut être considérée comme un jeu (au sens de la théorie de Von Neuman) entre le chercheur désireux de retrouver un ensemble de documents et la collectivité des auteurs de publications scientifiques, le gain des parties ainsi jouées correspondant à l'efficacité de la recherche documentaire effectivement poursuivie, c'est-à-dire, en première analyse, au rapport du nombre des documents judicieusement choisis et du nombre des documents sélectionnés.
Parmi les différents paramètres sur lesquels on peut jouer pour rechercher une stratégie optimale, on trouve évidemment en premier lieu le système de codification, le langage documentaire. Et de même que dans les jeux traditionnels où intervient le hasard des considérations statistiques permettent seules d'atteindre la détermination d'une « stratégie mixte » optimale, de même le langage optimal dépend dans sa structure des propriétés statistiques de l'ensemble des documents qu'il est appelé à décrire. Il faut donc s'attendre à ce qu'un tel langage se compose en réalité d'un certain nombre de sous-langages relativement différents, sous-langages correspondant plus particulièrement aux différentes subdivisions générales des sciences et des techniques. Bien entendu, une partie commune ne manquera pas de subsister, notamment en ce qui concerne les relations syntaxiques.
C'est d'ailleurs la différence relativement considérable qui existe entre les exigences linguistiques des différentes disciplines qui lève l'apparente contradiction entre les jugements portés par les documentalistes. C'est ainsi que pour un centre de documentation relatif aux propriétés des alliages par exemple, il apparaît qu'un langage pratiquement dépourvu de syntaxe, un pur vocabulaire, est suffisant. Au contraire, dans un domaine aux connexions multiples comme l'archéologie, des langages à la syntaxe riche et au vocabulaire limité à quelques dizaines de mots semblent très proches de l'optimal.
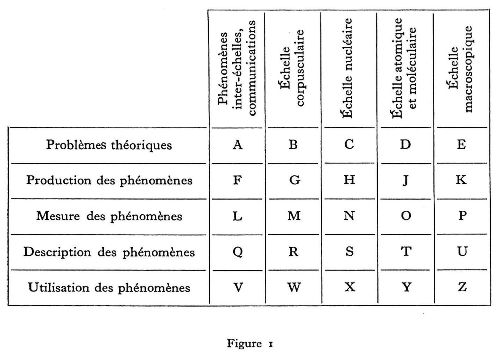
La classification alpha-numérique que nous avions conçue il y a quelques années pour les besoins du service de documentation du CEA nous offre l'exemple d'un système intermédiaire qui n'est certainement pas optimal, mais qui nous sera utile pour illustrer notre propos. Un tel système en effet associe à chaque rubrique une cote alpha-numérique. L'ensemble des cotes est donc le vocabulaire de notre langage, la syntaxe étant pour l'essentiel l'ensemble des relations algébriques auquel satisfont ces cotes. On remarquera ici que la structure est plus riche que dans le cas de la CDU puisque la partie alphabétique de la cote est munie d'une structure bidimensionnelle (fig. 1) (7).
Mais nous voudrions souligner ici l'existence dans cette classification de propriétés syntaxiques du type inflexif (déclinaison, conjugaison). C'est ainsi que les propriétés chimiques des éléments reçoivent une cote du type : TABx où AB est le symbole classique de l'élément et x un suffixe numérique spécifiant qu'il s'agit de la préparation du corps, de ses oxydes, etc...
V. Analyse d'un exemple.
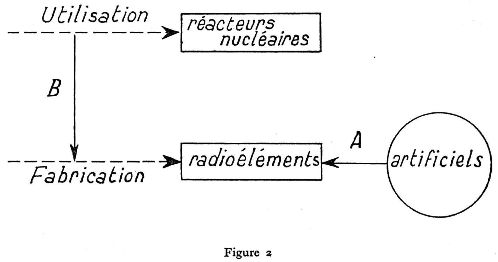
C'est dans le domaine de l'étude des réacteurs nucléaires qu'on aperçoit le mieux la nécessité et le rôle d'un système de codification réellement linguistique, c'est-à-dire comportant un vocabulaire important et une notable richesse syntaxique. Ce n'est pas étonnant si l'on songe à la diversité des sciences et techniques mises en cause dans ce domaine. Il n'est donc plus question désormais d'une codification numérique ou alpha-numérique; il faut seulement choisir avec soin le vocabulaire et les relations utilisées. Le plus commode pour cela est d'utiliser la représentation par diagrammes; c'est ainsi qu'à un article traitant de : « l'utilisation des réacteurs nucléaires pour les productions des radioéléments artificiels » (par P. Germont, Bulletin d'informations scientifiques et techniques du CEA, n° 27, pp. 13-17, mars 1950), on peut associer le diagramme suivant :
les rectangles correspondant aux « objets »;
les cercles aux « propriétés »,
les flèches en trait interrompu aux « actions »;
les flèches en trait plein aux « relations »;
- du type A (« se rapporte à ») ;
- du type B (« a pour but »);
etc... (8).
En fait, une analyse conçue d'après le texte lui-même et rendant donc mieux compte de ce qui y est traité, donne un diagramme tel que celui qui est représenté ci-dessous :
Tout sujet correspondant à une partie quelconque de ce diagramme devra pouvoir être retrouvé.
Ex. : Utilisation des réacteurs nucléaires à eau lourde pour la fabrication des radioéléments artificiels.
Calcul de l'activité spécifique des radioéléments produits dans un réacteur.
Action des neutrons sur les éléments d'un réacteur nucléaire, etc... toutes questions effectivement traitées dans l'article.
VI. Vers l'automatisation.
L'automatisation des fonctions documentaires devient indispensable à partir d'un certain stade du développement des fichiers. Mais elle est surtout la seule méthode qui subsiste lorsqu'on adopte un langage d'analyse qui ne soit pas purement dichotomique (comme l'était la CDU.). C'est ce qui rend les problèmes d'automatisation de la recherche documentaire si voisins des problèmes de la traduction mécanique des langues naturelles (9).
Dès lors, la recherche des « stratégies optimales », recherche à laquelle nous avons fait allusion dans un paragraphe précédent, doit combiner l'examen des langages et celui des machines. En ce sens, il apparaît très vite que les langages réellement utiles sont ceux qui se rapprochent le plus de langages naturels. C'est pourquoi des systèmes linguistiques à la syntaxe effroyablement compliquée comme ceux de Perry et Kent (10) ou de Pages (11) nous semblent plus proches de brillants jeux de l'esprit, comme le sont les romans de science-fiction, que de systèmes réellement utilisables.
Ceci apparaît encore mieux lorsqu'on songe à l'automatisation prochaine de l'analyse elle-même, automatisation qui suivra sans aucun doute de bien peu celle de la recherche des documents. Déjà certains auteurs ont abordé, par des voies statistiques, l'établissement automatique de résumés (12). Il ne nous semble pas que cette voie soit la bonne. En fait le chercheur veut avoir sous les yeux l'expression synthétique du document plutôt qu'un texte rédigé dans un style impeccable. C'est ce qui rend si utiles les ensembles de phrase-clés, sous forme de mots-clés et de diagrammes.
Bien entendu, les possibilités technologiques des machines permettant de réaliser l'automatisation dicteront sans doute quelques particularités du langage documentaire. C'est ainsi que, dans l'expérience que nous avons présentée à Francfort [6], nous avions limité notre langage à des phrases ne comprenant que trois mots. Mais il est clair que les progrès actuels nous donnent de plus en plus l'espoir d'avoir à notre disposition, d'ici quelques années, un outil (mémoires et organes logiques) nous permettant d'utiliser le langage le plus fin et le plus adéquat pour la description et l'exploitation des documents scientifiques dont l'accumulation risquait, naguère, de nous étouffer.
25 juillet 1959.