Des parcours de sens dans le Centre Pompidou virtuel
En 2012 le Centre Pompidou renouvelait son site web sous la forme d’une plateforme de diffusion de contenus numériques en ligne (www.centrepompidou.fr). Cette plateforme donne accès, à travers un point d’entrée unique, à l’ensemble de la production numérique de l’institution : œuvres d’art numérisées, documents sur l’art et l’histoire de l’art, enregistrements sonores, vidéos, archives, notices bibliographiques, etc. Une approche qui se veut originale et innovante : après un an d’ouverture au public de ce nouveau site, l’auteur dresse ici un premier bilan de cette expérience et présente les fondements de son architecture reposant sur les principes du web sémantique.
The Centre Pompidou updated its website in 2012, creating a platform to distribute digital content (www.centrepompidou.fr). The platform represents the key point of entry for access to the centre’s full online offer, from digitised works of art and material on art and art history to sound recordings, videos, archives, and bibliographical information. The main ambition of the new platform was to be original and innovative. A year on from its launch, Emmanuelle Bermès looks back at the initial results and outlines the platform’s architecture, which is based on the principles of the semantic web.
Im Jahre 2012 gestaltete das Centre Pompidou seine Webseite neu in Form einer Plattform zur Verbreitung digitaler Online-Inhalte (www.centrepompidou.fr). Diese Plattform bietet über einen einzigen Sucheinstieg Zugang zur Gesamtheit der digitalen Produktion der Einrichtung: digitalisierte Kunstwerke, Dokumente zu Kunst und Kunstgeschichte, Tonaufnahmen, Videos, Archive, bibliographische Datensätze, etc. Ein origineller und innovativ erscheinender Ansatz: nach einem Jahr Öffnung für das Publikum dieser neuen Webseite, zieht der Autor hier eine erste Bilanz dieser Erfahrung und stellt die Grundlagen ihrer Architektur, die auf den Prinzipien des semantischen Webs beruhen, vor.
En 2012 el Centre Pompidou renovaba su site Web bajo la forma de una plataforma de difusión de contenidos digitales en línea (www.centrepompidou.fr). Esta plataforma da acceso, a través de un punto de entrada único, al conjunto de la producción digital de la institución: obras de arte digitalizadas, documentos sobre el arte y la historia del arte, grabaciones sonoras, videos, archivos, reseñas bibliográficas, etc. Un enfoque que se propone ser original e innovador: después de un año de apertura al público de este nuevo site, el autor levanta aquí un primer balance de esta experiencia y presenta los fundamentos de su arquitectura que reposa en los principios del web semántico.
Depuis 2007, le Centre Pompidou met en place une nouvelle stratégie numérique avec pour objectif le développement d’une plateforme de diffusion de contenus numériques en ligne : le Centre Pompidou virtuel 1. Cette plateforme donne accès, à travers un point d’entrée unique, à l’ensemble de la production numérique de l’institution et à certaines ressources de ses établissements associés (BPI, Ircam et Centre Pompidou Metz) : œuvres d’art numérisées, documents sur l’art et l’histoire de l’art, enregistrements sonores, vidéos, archives, notices bibliographiques, etc. Une approche qui se veut originale et innovante : après un an d’ouverture au public de ce nouveau site, nous tirons ici un premier bilan de cette expérience.
Une approche innovante
À l’origine du projet se posait une question fondatrice : que signifie aujourd’hui « être sur le web » pour une institution comme le Centre Pompidou ? Rapidement, le projet s’est défini en opposition avec un site institutionnel classique, qui serait principalement destiné aux visiteurs du bâtiment parisien. Le nouveau site devait toucher son propre public, devenir un site à part entière offrant à ses visiteurs une expérience originale, comme le Centre Pompidou Metz ou le Centre Pompidou mobile. Simultanément, il devait renouer avec ce qui fonde les valeurs du Centre Pompidou : l’ouverture à tous les publics, la pluridisciplinarité, le fait d’être toujours en mouvement.
La présence en ligne du Centre Pompidou s’est donc orientée vers une approche centrée sur les contenus : le site web de l’établissement est aujourd’hui un centre de ressources en ligne de référence pour toute personne intéressée par l’art moderne et contemporain, ou même par la pensée contemporaine en général. Destiné à donner à voir aux internautes l’ensemble des productions réalisées par le Centre à destination de ses publics, le site constitue un reflet au jour le jour de la programmation, mais également un nouveau patrimoine puisque c’est toute l’histoire du Centre qui se retrouve en ligne, numérisée depuis 1977.
Une autre définition de « virtuel »
Le projet refuse de céder à la définition traditionnelle du terme « virtuel » qui tendrait à limiter l’expérience numérique à une reproduction à l’identique de l’expérience in situ. Ce type d’approche, qui repose sur des prises de vues à 360o comme dans le Google Art Project, ne cadre pas avec la conviction, qui est celle du Centre Pompidou, qu’une expérience virtuelle ne peut en aucun cas remplacer le contact direct aux œuvres, l’approche émotionnelle et sensible de notre patrimoine culturel. De plus, l’enjeu est moins de montrer ce qui est déjà visible que de révéler ce qui est habituellement caché. Parmi les 99 000 œuvres du musée, seules 2 000 environ sont effectivement exposées à un moment donné, soit dans le bâtiment parisien, soit hors les murs à travers des itinérances d’exposition, des prêts ou encore des dépôts. Même si les rotations fréquentes de l’accrochage permettent d’atténuer cette contrainte spatiale, force est de constater que la plus grande partie de la collection reste invisible au public, stockée dans les réserves. La numérisation permet de rendre ce patrimoine accessible à tous.
Une approche non éditoriale
L’approche éditoriale traditionnelle des sites web de musée tend à mettre l’accent majoritairement sur les œuvres ou les artistes qui sont considérés comme d’intérêt majeur, ce qui a pour effet de privilégier une culture dominante par rapport à des formes plus alternatives de création. Suivant le paradigme de la longue traîne, les artistes les plus connus tendent à avoir une présence plus forte sur les sites de musée que les autres. Or, le Centre Pompidou est attaché à sa tradition d’ouverture à des formes d’art nouvelles, et ne souhaite pas privilégier une certaine partie de la collection, mais préfère faciliter les découvertes inattendues et la sérendipité. C’est à cette seule condition que peut être respectée la pluridisciplinarité de la programmation culturelle du Centre, qui ne repose pas seulement sur le musée et les expositions mais inclut également des conférences, des spectacles vivants, des séances de cinéma et d’autres événements impliquant des artistes contemporains de tous horizons.
Cette absence d’éditorialisation a pour corollaire la mise en place de processus de travail adaptés. Si pratiquement aucune information n’est créée à seule fin d’alimenter le site web, la plupart des processus de production et des activités des professionnels du Centre Pompidou ont dû être adaptés pour prendre en compte la finalité de diffusion sur internet des contenus qu’ils produisent. Ainsi la numérisation des œuvres, à l’origine principalement tournée vers la conservation, est devenue une numérisation de diffusion, prenant en compte les nécessités d’indexation qui permettront au grand public de trouver plus facilement les œuvres. De la même manière, les demandes d’autorisation de diffusion sur internet dans le cas des contenus protégés par des droits de propriété intellectuelle (c’est-à-dire la plupart des contenus, puisque le Centre Pompidou a pour objet l’art des vingtième et vingt et unième siècles) sont désormais formulées au moment de la création des contenus autant que faire se peut. À travers ces changements dans les pratiques, ce sont des dizaines de professionnels du Centre Pompidou qui sont impactés par le projet.
La dimension innovante de ce projet pour l’établissement réside donc aussi dans cette dimension organisationnelle très forte : il ne s’agit pas seulement de créer un site web, mais de faire prendre le virage du numérique à l’ensemble de l’institution.
L’innovation technologique
Ces différents prérequis ont conduit le Centre Pompidou à définir une expérience « virtuelle » complètement différente de l’offre in situ. À cette fin, le Centre Pompidou a créé un centre de ressources numériques qui agrège une grande diversité de contenus, de documents et d’archives en relation avec les artistes et les œuvres.
Le choix d’une approche documentaire peut paraître déstabilisant pour un site de musée, mais il se justifie pleinement si on considère la nature pluridisciplinaire de l’activité du Centre Pompidou. On capitalise ainsi sur la capacité des internautes à construire leur propre parcours en suivant les liens et en agrégeant les contenus suivant leurs propres centres d’intérêt.
C’est là la dernière innovation mise en œuvre par le Centre Pompidou dans le cadre de ce projet : le choix d’une architecture open source utilisant les technologies du web sémantique.
Pourquoi les technologies du web sémantique ?
Des bases de données hétérogènes
Le Centre Pompidou virtuel a été créé en agrégeant plusieurs bases de données existantes, qui sont en réalité les outils de travail quotidiens des différents services :
- la base de gestion des collections du musée ;
- l’agenda, qui décrit tous les événements de la programmation (expositions, conférences, spectacles, visites, ateliers, etc.) passés, présents et à venir ;
- les catalogues des bibliothèques (bibliothèque Kandinsky, BPI et médiathèque de l’Ircam) ;
- des inventaires d’archives (archives de l’établissement et fonds d’archives d’artistes conservés par la bibliothèque Kandinsky) ;
- les produits de la boutique en ligne référencés dans un outil de gestion e-commerce ;
- d’autres bases de données contenant des ressources audiovisuelles, des articles, des biographies, des dossiers pédagogiques, etc.
Il était extrêmement complexe de parvenir à rassembler toutes ces informations dans une interface commune pour les mettre à disposition du public de manière unifiée. Les données étaient très hétérogènes : certaines respectaient des normes de bibliothèque (Marc, MODS et Dublin Core) et d’autres des normes archivistiques (EAD). Certaines correspondaient à des formats définis localement. Une partie des données n’était pas de nature documentaire (personnes, événements).
Cette séparation des données en plusieurs bases ne pouvait être remise en cause par le projet, dans la mesure où il avait été posé pour principe de perturber le moins possible les pratiques des professionnels. Le nouveau centre de ressources numériques devait donc utiliser ces bases de données comme sources en l’état, et agréger et mettre en relation leurs contenus. La diversité des modèles de données a débouché sur le choix des technologies du web sémantique presque comme une évidence. En effet, le web de données offre une manière extrêmement efficace de construire l’interopérabilité entre des bases de données aux structures hétérogènes.
L’interopérabilité suivant le web de données
Le principe du web de données est de permettre de relier entre elles des ressources dont la structure de description (le « format ») est hétérogène, en utilisant des identifiants web, les URI. La grammaire commune RDF, qui repose sur l’organisation de l’information en « triplets » (phrases simples de type « sujet – prédicat – objet »), permet de créer du lien entre ces ressources 2. Toutes les ressources sont alors reliées entre elles, non pas de manière hiérarchique, mais sous la forme d’un graphe qui exprime clairement la nature de leurs relations.
Le but de cette technologie est de fournir à l’utilisateur final un espace global d’information, sans barrières, dans lequel il peut naviguer intuitivement. De la même manière que, sur le web, on peut relier des pages et des sites web avec des liens hypertextes sans se préoccuper des serveurs et des systèmes de gestion de contenu qui hébergent ces pages et ces sites, le web de données crée une forme d’interopérabilité nouvelle : différentes institutions peuvent relier leurs bases de données sans avoir besoin d’utiliser les mêmes logiciels ou de centraliser l’information à un même endroit.
Les principes du web de données ont été conçus pour une application sur le web ouvert et entre différentes institutions, mais ils peuvent également avoir un intérêt dans le cadre d’un usage interne à une institution : ce type d’usage est appelé LED pour « Linked Enterprise Data 3 » (données d’entreprise liées). Le LED a pour objectif d’appliquer les principes du web de données à l’intérieur de l’entreprise pour favoriser l’interopérabilité entre les différentes briques du système d’information.
Ces principes correspondent exactement aux modalités d’interopérabilité que le Centre Pompidou souhaitait construire. L’objectif était d’éviter de forcer toutes les bases de données à se couler dans une structure commune, mais de garder quand même la possibilité de relier leurs contenus.
Le modèle de données
Le Centre Pompidou virtuel s’appuie sur un cœur RDF qui relie toutes les données des différentes bases. Elles sont dès lors exprimées dans un modèle commun en utilisant le RDF et les URI. Afin d’atteindre cet objectif, une ontologie RDF a été créée 4, basée sur quelques concepts clefs : les Œuvres, les Documents, les Personnes, les Lieux, les Collections, les Événements et les Ressources (voir figure ci-dessous).
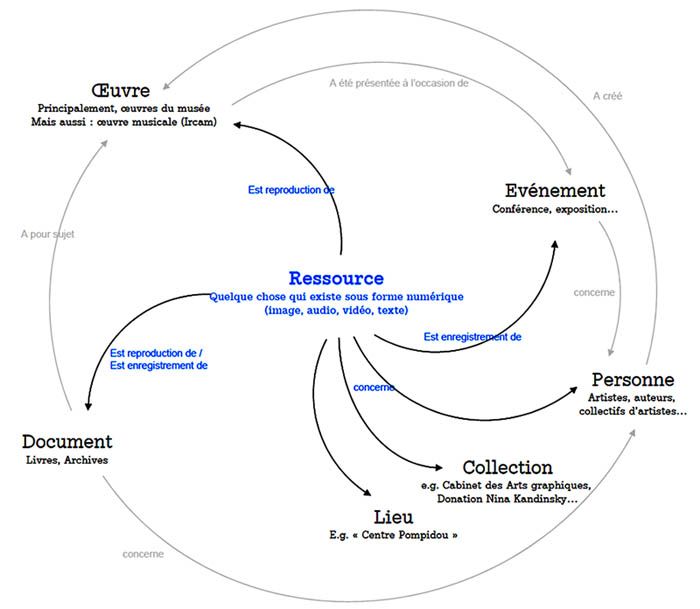
Les principaux concepts sont destinés à intégrer les données issues des différentes sources : les données du musée se rattachent principalement aux concepts « Œuvre », « Personne » et « Collection ». L’agenda fournit des informations sur les « Événements » et les « Lieux » où ils se déroulent. Les données des bibliothèques et des archives sont rassemblées autour du concept de « Document ». Enfin, l’audiovisuel constitue des « Ressources » qui sont liées aux différents éléments de contenus des enregistrements (« Personnes intervenant dans les conférences », « Œuvres présentées », etc.). Le contenu artistique (œuvres du musée, œuvres musicales) est relié avec de l’information sur les événements (expositions, performances, conférences) et avec d’autres ressources pertinentes (affiches, photographies, livres, documents d’archives…) ce qui permet aux utilisateurs de parcourir le site web et de découvrir toutes ces ressources de façon complètement libre et ouverte.
L’intérêt de ce modèle est de préserver la richesse des informations en provenance de chaque base, tout en les reliant autour des entités qu’elles ont en commun (surtout des personnes ou des événements).
Du parcours de sens à la construction d’une communauté
L’objectif de la création de ce modèle de données et de tous les liens entre les bases est de permettre une nouvelle expérience pour les utilisateurs : naviguer dans les données par le sens.
Un mode de navigation entièrement nouveau
La capacité à naviguer dans le graphe suivant ses propres centres d’intérêt constitue ce que l’on appelle le « parcours de sens » : les internautes extraient leur propre signification à partir du graphe de données, ils construisent leur propre parcours adapté à leur intérêt et au temps qu’ils veulent passer sur le site.
Dans la plupart des sites web, la navigation est principalement hiérarchique, du plus général au plus spécifique. Dans le Centre Pompidou virtuel, elle prend au contraire la forme d’un graphe hypertextuel où toutes les ressources sont au même niveau. Le site est également différent d’une base de données relationnelle dans laquelle il serait nécessaire d’exprimer une requête détaillée pour obtenir des résultats. Les bases de données se comportent souvent comme des culs-de-sac, qui n’offrent pas d’autre choix une fois qu’on a atteint une ressource que de poser une autre question. Au contraire, le site du Centre Pompidou offre constamment de nouveaux liens pour élargir la recherche à de nouveaux objets qui n’étaient pas pris en compte à l’origine.
La création des liens offre ainsi une manière vraiment innovante de parcourir les données. L’interface a été conçue de façon à pouvoir présenter de nombreux liens sur une seule page. Les contenus sont naturellement décloisonnés et traités de manière homogène, afin de permettre leur organisation en fonction des besoins de chaque utilisateur, et non en fonction d’une logique dictée par des usages ou des structures définis a priori. Des astuces ont été nécessaires, comme les onglets qui se déplient verticalement et dévoilent toujours plus de ressources liées. Cela permet d’offrir différents points de vue sur les données :
- Si l’usager s’intéresse à une œuvre, il peut découvrir l’artiste qui l’a créée, en voir une ou plusieurs reproductions numérisées, consulter une vidéo de l’artiste en train de commenter son œuvre ou un extrait d’un catalogue imprimé. Il peut aussi voir dans quelles expositions l’œuvre a été montrée, le lieu où elle est exposée actuellement et les œuvres qui font partie de la même collection.
- Si le point d’entrée de l’usager est l’événement, par exemple s’il veut savoir quelles sont les expositions en cours au Centre Pompidou, il accède à l’information sur l’événement mais aussi à des vidéos, au catalogue de l’exposition dans les collections de la bibliothèque et dans la boutique en ligne, et il peut découvrir des événements liés comme des ateliers pour les enfants, des conférences, etc. (voir l’illustration ci-dessous, où seul l’onglet « Les événements en rapport » est déplié).
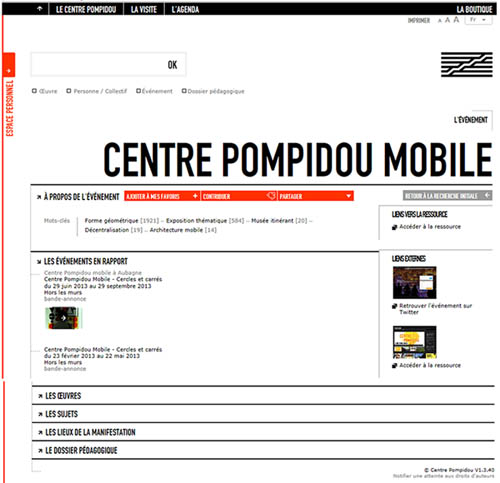
Avant que le site web ne soit officiellement ouvert au public, une étude d’usage a été conduite afin d’évaluer cette nouvelle manière d’appréhender les contenus. L’étude a pris la forme de plusieurs focus groups, organisés par profils d’utilisateurs (étudiants et chercheurs, professionnels de la culture, technophiles, et « tous publics »).
Les usagers experts (étudiants, chercheurs, professionnels) ont témoigné du fait qu’il leur avait fallu du temps pour prendre en main ce nouvel outil. En revanche, ceux qui se contentaient de naviguer au gré de leur curiosité appréciaient le fait de découvrir des ressources inattendues. Les utilisateurs percevaient donc qu’il s’agissait d’une manière complètement nouvelle de naviguer dans les données. Cependant, ils se sentaient parfois perdus dans la richesse des contenus ; ils demandaient à bénéficier d’outils qui leur permettraient de s’orienter dans l’espace du site.
Cette étude sommaire aurait besoin d’être confirmée par une enquête plus approfondie, quantitative aussi bien que qualitative ; mais elle montre que le site du Centre Pompidou présente une interface originale en s’appuyant sur les spécificités des principes du web de données et de la navigation par graphe.
Vers une co-construction du sens
En même temps qu’il construisait son propre projet de site web, le Centre Pompidou a développé une stratégie de présence très forte sur les réseaux sociaux. L’objectif était de mettre en place les premières amorces d’une communauté et, à terme, de l’inviter à co-construire le site pour rendre les parcours de sens toujours plus performants et utiles. Une stratégie qui rencontre un certain succès si l’on considère les 330 000 fans sur Facebook et les 83 000 abonnés sur Twitter, mais aussi et surtout le volume des conversations entamées sur ces plateformes : l’échange entre le public et le Centre Pompidou se crée sur des demandes d’informations pratiques mais aussi à travers la contribution des internautes, qui font connaître leur savoir ou leurs émotions concernant la programmation.
Cette démarche est accompagnée d’une forte implication de l’institution dans les cultures web, notamment à travers le partenariat conclu avec Wikimédia France en septembre 2013. Une série d’ateliers avec les publics permettra de créer des notices dans Wikipédia. D’autres ateliers thématiques auront lieu avec les agents du Centre 5. Enfin, le partenariat sera l’occasion de réaliser une approche théorique des projets collaboratifs à travers trois conférences présentant les réalisations concrètes des ateliers et des échanges avec des experts du domaine.
La convergence de ces différentes interactions avec les communautés numériques se concrétise sur le site à travers un espace personnel pour l’instant relativement embryonnaire, mais destiné à évoluer selon les usages des publics.
Afin de répondre aux premières critiques et suggestions des utilisateurs, il est en effet prévu d’enrichir l’espace personnel d’une fonction d’historique qui enregistrera l’ensemble du parcours de l’internaute ; à partir de cet historique, l’usager pourra enregistrer, commenter puis partager son parcours avec d’autres. Les internautes deviendront partie prenante de la construction du sens, en contribuant à l’ajout de mots-clés et à l’élaboration des parcours.
Conclusion
En définissant une approche centrée sur les contenus pour son site web et en l’implémentant avec les technologies du web sémantique, le Centre Pompidou a souhaité faire acte d’innovation pour permettre à sa communauté de s’approprier le patrimoine dont il est le gardien. Un autre aspect intéressant du choix de RDF et du web de données réside dans le fait que l’interface proposée actuellement n’est que l’une des représentations possibles du graphe de données créé par l’agrégation des différentes sources et de leurs liens. D’ores et déjà, d’autres modes d’accès plus adaptés à la consultation sur des terminaux mobiles sont à l’étude. Il est prévisible que, comme tout site web, le site du Centre Pompidou sera appelé à faire peau neuve après deux ou trois années, en rythme avec l’évolution de l’état de l’art de l’ergonomie web. Une telle évolution sera facilitée par la disponibilité des données dans des formats standards et par l’utilisation des outils open source. •
Septembre 2013