Bibliothèques, crowdsourcing, métadonnées sociales
L’auteur présente les principes du crowdsourcing et particulièrement la sollicitation des compétences et des connaissances des usagers qui contribuent à l’enrichissement de la description des collections des bibliothèques ou des centres d’archives. Ces projets peuvent concerner le simple enrichissement de données bibliographiques, mais, à l’heure de la mise en ligne massive de documents numériques, la sollicitation des usagers peut s’appliquer à la correction, la transcription ou l’identification collaboratives des contenus OCRisés. L’auteur conclut sur les implications et les devoirs qu’entraîne la mise en œuvre de tels projets dans les bibliothèques, et qui ne seraient que « cosmétiques » s’ils ne prévoyaient pas la réintégration effective des contenus enrichis dans les catalogues.
Pauline Moirez outlines the principles behind crowdsourcing – the practice of calling on the collective skills and knowledge of users, contributing in this case to descriptions of holdings in libraries and archives. Such projects can be as straightforward as inputting bibliographical data, but now that vast quantities of digital material are being moved online, they can also involve collaboratively correcting, transcribing, and identifying content produced by OCR. The author concludes by looking at the implications and duties for libraries involved in such projects, which have a responsibility to participants to ensure that the content they contribute is indeed integrated into the library’s own catalogues.
Der Autor stellt die Grundsätze des crowdsourcing vor und insbesondere das Ersuchen der Kompetenzen und der Kenntnisse der Benutzer, die zur Bereicherung der Beschreibung der Sammlungen der Bibliotheken oder der Archive beitragen. Diese Projekte können die simple Anreicherung bibliographischer Daten betreffen, doch in der Zeit des massiven Online-Schaltens digitaler Dokumente, kann die Beteiligung der Benutzer bei der gemeinschaftlichen Korrektur, Umschreibung oder Identifizierung der mit OCR bearbeiteten Inhalte Anwendung finden. Der Autor schliesst mit den Folgen und den Pflichten, die die Umsetzung dieser Projekte in den Bibliotheken mit sich bringen, die nur „kosmetisch“ wären, wenn sie nicht die tatsächliche Wiedereingabe angereicherter Inhalte in die Kataloge vorsehen würden.
El autor presenta los principios del crowdsourcing y particularmente la solicitación de competencias y de los conocimientos de los usuarios que contribuyen al enriquecimiento de la descripción de las colecciones de las bibliotecas o de los centros de archivos. Estos proyectos pueden concernir el simple enriquecimiento de datos bibliográficos, pero, a la hora de la puesta en línea masiva de documentos digitales, la solicitación de los usuarios puede aplicarse a la corrección, la descripción o la identificación colaborativas de los contenidos OCRisados. El autor concluye sobre las implicaciones y los deberes que implica la aplicación de tales proyectos en las bibliotecas que solamente serían “cosméticos” si no previeran la reintegración efectiva de los contenidos enriquecidos en los catálogos.
L’intégration des bibliothèques dans l’écosystème du web permet d’envisager des possibilités inédites et innovantes d’interactions avec les usagers et d’enrichissement des métadonnées descriptives des collections en s’appuyant sur la participation des internautes.
Le terme le plus couramment utilisé pour désigner ce type de projets, qui peut s’appliquer largement au-delà du monde des bibliothèques et de la culture, est celui de crowdsourcing, c’est-à-dire des contenus ou informations (source) produits par la foule (crowd) des usagers. Ce terme générique met plus l’accent sur le volume des participants, sur la notoriété et l’ampleur des projets, sur la constitution de communautés de contributeurs, que sur la valeur de leurs contributions. On pourra ainsi désigner sous ce terme aussi bien des projets qui font appel à la sensibilité, à la subjectivité de l’utilisateur, comme la notation ou la critique d’ouvrages ou de films, que de véritables programmes scientifiques.
Les institutions culturelles, bibliothèques, archives, musées, s’attachant à la qualité et à la valeur ajoutée des contenus apportés par les utilisateurs, investissent particulièrement un sous-ensemble de ces activités de crowdsourcing, que l’on peut plus spécifiquement qualifier par l’adjectif de « participatives 1 », c’est-à-dire qu’elles sollicitent la mise en œuvre de véritables compétences et connaissances des usagers, de caractère scientifique, qui contribuent à l’enrichissement de la description des collections : indexation collaborative (en particulier, folksonomies 2), identification de documents iconographiques ou audiovisuels, correction collaborative d’OCR, transcription collaborative, co-création de contenus scientifiques 3. On parlera alors aussi de « métadonnées sociales 4 » pour insister davantage sur l’enrichissement et l’amélioration de la description des collections et donc de l’accès des utilisateurs à ces collections. Ce sont ces interactions de haut niveau qui feront l’objet principal de cet article.
Les projets de crowdsourcing en bibliothèque, et plus largement dans les établissements culturels, correspondent cependant à une pratique encore jeune, dont les mises en œuvre restent largement innovantes et expérimentales.
Par ailleurs, l’intégration de fonctionnalités d’enrichissement collaboratif dans les catalogues ou bibliothèques numériques françaises reste peu fréquente, et rencontre rarement le succès escompté 5, alors que des bibliothèques anglo-saxonnes ou d’autres institutions culturelles, en particulier les services d’archives 6, parviennent à mettre en place des projets particulièrement réussis.
C’est pourquoi il est intéressant de s’appuyer sur les retours d’expérience des institutions qui ont mis en œuvre de tels projets, pour essayer d’analyser les atouts et enjeux de ces projets pour les bibliothèques, ainsi que les risques et défis à relever, afin de donner des pistes de réalisation à nos bibliothèques… et l’envie de tenter l’aventure ?
Les enjeux des bibliothèques participatives : nouveaux usages, nouveaux besoins
Des données bibliographiques et des collections : autant d’atouts pour des projets de crowdsourcing en bibliothèque
Les bibliothèques disposent d’atouts significatifs pour mettre en œuvre de tels projets, et en premier lieu une conscience de l’importance des métadonnées – de leur exhaustivité comme de leur qualité – pour l’accès aux collections et – par voie de conséquence – pour l’amélioration des services aux usagers. Les bibliothèques ont également une bonne expérience de la récupération de données produites ailleurs (dérivation de notices bibliographiques, récupération de données en provenance des éditeurs, par exemple) : les métadonnées sociales peuvent aisément s’insérer dans ces processus de récupération et de rediffusion de données de provenances diverses.
La participation des usagers, qui peut s’appliquer à de simples données bibliographiques, présente un intérêt renforcé par la mise en ligne massive de documents numériques. En effet, la mise à disposition des usagers de documents numérisés, images, voire textes OCRisés, permet des opérations de crowdsourcing ambitieuses qui enrichissent notablement la description des documents : indexation, identification de photographies, correction d’OCR ou encore transcription collaborative. De plus, la masse, la richesse et la variété de ces collections numérisées par les bibliothèques (manuscrits, livres, images fixes, images animées, documents sonores ou audiovisuels) multiplient les opportunités d’expérimentations et d’interventions d’utilisateurs aux intérêts, formations et qualifications divers.
Enfin, pour les contenus édités, l’existence de plusieurs exemplaires d’un même document ouvre la voie à des réutilisations d’enrichissements sociaux réalisés sur d’autres exemplaires. C’est le modèle des médias sociaux spécialisés dans les échanges autour des livres, des films ou de la musique, comme Babelio, Sens Critique, LibFly ou encore LibraryThing, qui disposent d’un large vivier de contributeurs, et dont l’intense activité de recommandation peut permettre d’atteindre la masse critique de contributions nécessaire à l’enrichissement du signalement des bibliothèques 7.
Inventer de nouvelles interactions avec les usagers
Les bibliothèques s’inscrivent dans un écosystème du web où l’interaction est la norme : l’internaute s’attend à pouvoir intervenir sur les données et sur les contenus, que ce soit pour les commenter, les partager ou les enrichir. Même lorsqu’il n’utilise pas ces fonctionnalités 8, elles lui sont familières dans sa pratique courante du web, sur les réseaux sociaux ou les sites marchands. Elles constituent son cadre de référence, il se sentira enfermé et exclu s’il ne les a pas à sa disposition 9.
L’enjeu des bibliothèques est donc, au-delà d’une réponse à cette attente des internautes, de faire le meilleur usage possible des contributions des usagers pour enrichir les métadonnées descriptives de leurs collections et pour améliorer l’expérience de recherche et de navigation des utilisateurs. Il serait en effet dommage de n’utiliser les potentialités du web social que de façon « cosmétique », sans en faire véritablement bénéficier le signalement des collections et l’interface de recherche de la bibliothèque.
Pour aller plus loin, le développement des « sciences citoyennes 10 », associant la participation d’amateurs à des travaux de relevé, de dépouillement, d’identification scientifiques, peut s’appliquer aux domaines patrimoniaux 11, et en particulier aux collections de bibliothèques.
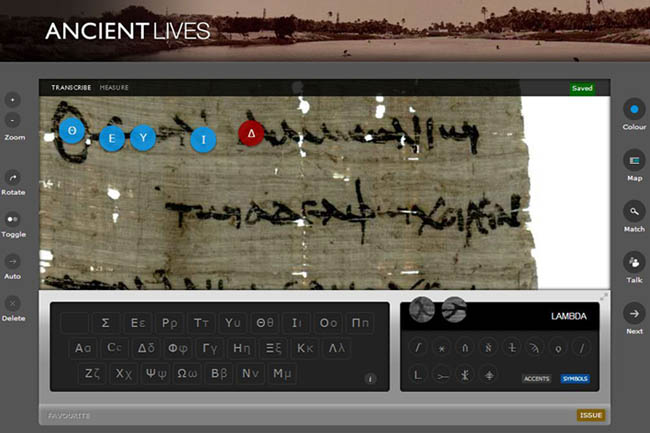
Au sein du réseau Zooniverse, maintenu par la Citizen Science Alliance dont l’objet est d’associer universités et musées dans des projets de sciences citoyennes, le projet Ancient Lives (voir illustration ci-dessous), coordonné par l’université d’Oxford, propose la transcription collaborative de centaines de milliers de fragments de papyrus de l’Égypte gréco-romaine, afin de les identifier, de les publier et de les mettre à disposition des chercheurs 12. Entre 2011 et 2012, plus de 1,5 million de tâches de transcription ont ainsi été réalisées, qui ont permis l’identification d’une centaine de textes, dont des œuvres littéraires de Plutarque et d’Euripide.
Répondre à l’évolution des besoins de recherche des usagers
Les métadonnées sociales permettent de répondre à des besoins différents et d’offrir aux usagers et aux chercheurs des services différents de ceux permis par les métadonnées produites par les catalogueurs professionnels. Métadonnées professionnelles et métadonnées sociales ne sont pas concurrentes, mais complémentaires, pour répondre à l’ensemble des besoins de recherche des internautes dans les collections des bibliothèques.
Ainsi, devant l’évolution des pratiques de recherche induites par les moteurs de type Google, il devient de plus en plus important de pouvoir fournir aux usagers une recherche en plein texte dans les collections textuelles. Des projets de correction d’OCR 13 ou de transcription collaborative ex nihilo ont vu le jour pour répondre à ce besoin, dont le plus abouti à ce jour est sans doute celui mis en place pour les périodiques dans la bibliothèque numérique Trove de la Bibliothèque nationale d’Australie 14. Il propose aux internautes de participer à l’amélioration de la transcription de plus de 8 millions de pages ; 2 millions de lignes de texte sont ainsi corrigées chaque mois par environ 30 000 volontaires. L’intégration de ce service au cœur même de la bibliothèque numérique permet de rendre immédiatement disponibles aux internautes les enrichissements apportés.

De même, des projets de crowdsourcing permettent d’offrir aux usagers une granularité de description des collections plus fine, et tout particulièrement pour ce qui concerne les collections iconographiques auxquelles il est impossible d’accéder par un moteur de recherche si elles ne disposent pas d’un minimum de données descriptives. La bibliothèque municipale de Lyon propose ainsi l’identification collaborative de photographies 15, tandis que la New York Public Library permet aux usagers de géoréférencer les cartes anciennes 16.
Bibliothèques au défi du crowdsourcing
Un projet de crowdsourcing nécessite généralement un important investissement en temps et/ou en argent. Afin d’assurer un réel retour sur investissement, il est nécessaire d’avoir conscience des risques de ces projets… et de relever leurs défis.
Recruter et motiver les contributeurs
Les projets de crowdsourcing n’ont de sens qu’à partir du moment où l’on atteint une masse critique de contributions qui permet de remplir les objectifs de correction que l’institution s’est fixés et d’améliorer véritablement l’accès aux collections.
Afin de recruter les usagers, de les faire venir sur l’interface de crowdsourcing, de les convaincre de participer, voire de devenir des contributeurs réguliers, il est donc nécessaire d’identifier les principaux leviers de contribution, et de les utiliser aussi bien dans les campagnes de communication et de médiation accompagnant le projet, qu’au sein de l’interface de contribution elle-même : intérêt scientifique, participation à une cause « citoyenne », envie de jouer, sentiment de communauté, etc. 17
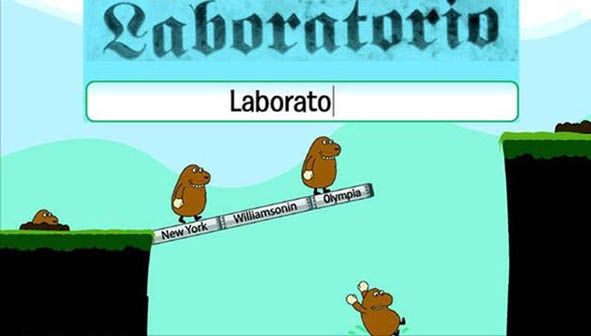
Ainsi, Digitalkoot, programme de correction collaborative d’OCR de la Bibliothèque nationale de Finlande, s’appuie sur la « gamification » pour engager les contributeurs à effectuer les tâches de correction 18 : deux jeux permettent de valider les résultats de l’OCR et de réaliser de la saisie de mots. Grâce à cette approche ludique, Digitalkoot a été un grand succès : près de 110 000 participants ont généré plus de 8 millions de tâches de correction de mots (voir illustration ci-dessous).
Le choix des corpus ouverts à la correction est également un levier de motivation fréquemment utilisé par les institutions culturelles. La New York Public Library cible par exemple les gourmands et gourmets grâce à son projet What’s on the menu ? qui ouvre à la transcription collaborative 45 000 menus de restaurants datant des années 1840 à nos jours 19.
Assurer la qualité des données produites
La coexistence dans les catalogues et bibliothèques numériques de données produites par des professionnels et de données produites par les internautes nécessite de porter une grande vigilance à la qualité des données créées par ces derniers.
Il convient donc de mettre en œuvre des processus pour assurer la qualité et la fiabilité des contributions : formation et assistance des contributeurs, évaluation de leurs compétences et distribution de rôles différenciés, corrections multiples des mêmes données, vérification systématique ou échantillonnée par des professionnels 20.
La qualité des contributions du projet Transcribe Bentham, transcription des 60 000 pages du philosophe anglais Jeremy Bentham, initié par l’University College of London, s’appuie ainsi sur une communauté soudée autour du projet, et sur une validation par des experts 21 : lorsqu’un manuscrit a été étudié par un nombre suffisant d’utilisateurs, il est soumis à la validation d’une équipe de chercheurs.
Dans le projet Old Weather 22, les internautes sont invités à transcrire les relevés météorologiques manuscrits réalisés par les navires de la Marine royale anglaise au début du xxe siècle, afin de disposer de bases de données météorologiques complètes et fiables, pour comprendre et modéliser le climat et ses évolutions. Les relevés sont systématiquement soumis à deux contributeurs, et à un troisième en cas de différence entre les deux premiers.
Réintégrer les contributions dans les catalogues
Il faut également rester vigilants à éviter l’écueil d’un crowdsourcing « cosmétique », réalisé pour se conformer aux codes du web et pour donner l’image d’une institution innovante et à l’écoute de ses utilisateurs, mais qui n’améliorerait pas véritablement les fonctionnalités offertes aux usagers, et tromperait finalement l’internaute qui croit contribuer à cette amélioration.
Il est ainsi souhaitable de prévoir la réintégration des contenus enrichis dans les catalogues, dans les bibliothèques numériques, pour qu’ils améliorent véritablement l’expérience de recherche de l’usager, que ces enrichissements collaboratifs aient été produits sur le site de la bibliothèque (comme dans la bibliothèque numérique Trove) ou déportés sur des médias externes (plateforme dédiée comme pour Digitalkoot, ou plateforme distincte, préexistante et spécialisée dans ce type d’activité, comme Wikisource 23).
Les nouveaux enjeux du crowdsourcing
Pour conclure, il convient de souligner que le crowdsourcing en bibliothèque, et plus largement dans les institutions culturelles, reste un domaine d’innovation, où des projets bien installés côtoient des projets de recherche aussi bien technologiques (interfaces hommes-machines, fouille automatique de données) que d’usages (des collectivités territoriales françaises envisagent par exemple de renforcer leur politique d’open data grâce à des projets de crowdsourcing).
L’articulation entre crowdsourcing et web de données semble ainsi particulièrement prometteuse, avec des projets comme HdA-Lab 24, collaboration entre l’Institut de recherche et d’innovation (IRI) et le ministère de la Culture et de la Communication, qui expérimente le « tagging sémantique » des ressources du portail Histoire des Arts en utilisant les entrées de Wikipédia comme référentiel d’indexation. •
Septembre 2013