Le sudoc dans Google Scholar
L’Abes (Agence bibliographique de l’enseignement supérieur), consciente de la prépondérance de Google dans les recherches des étudiants et des chercheurs, a signé un contrat avec celui-ci afin que les données du Sudoc (Système universitaire de documentation) soient indexées dans Google Scholar, après s’être assurée de la préservation de ses intérêts et de ceux de ses partenaires. Premier bilan neuf mois après le démarrage pour cet accord, certes emblématique, mais qui ne constitue qu’un élément de la stratégie globale de l’Abes pour assurer une meilleure visibilité aux ressources des bibliothèques universitaires françaises sur le web.
Aware of the prevalent use of Google in student and scholarly Internet research, the ABES (Agence Bibliographique de l’Enseignement Supérieur) has signed an agreement with Google to index SUDOC (Système Universitaire de Documentation) data in Google Scholar, while ensuring that its interests and those of its partners are preserved. This is its first assessment, nine months after the start of the symbolic agreement, which represents just one aspect of the global strategy of the ABES to create better visibility of French university library resources on the Internet.
Die Abes (Agence bibliographique de l’enseignement supérieur, bibliografische Stelle für Hochschulbibliotheken), sich der Voherrschaft Googles bei den Recherchen der Studenten und den Forschern bewusst, hat, nach der Absicherung der Wahrung ihrer Interessen und jener ihrer Partner, einen Vertrag mit Google abgeschlossen, damit die Daten des Sudoc (Système universitaire de documentation, Verbundkatalog der wissenschaftlichen Bibliotheken) in Google Scholar indexiert werden. Eine erste Bilanz neun Monate nach Anlauf dieses, sicher emblematischen, Abkommens, das jedoch nur ein einzelnes Element der Gesamtstrategie der Abes darstellt, um die bessere Sichtbarkeit der Ressourcen der französischen Universitätsbibliotheken im Netz zu gewährleisten.
El Abes (Agencia bibliográfica de la enseñanza superior), consciente de la preponderancia de Google en las búsquedas de los estudiantes y de los investigadores, ha firmado un contrato con éste con el fin de que los datos del Sudoc (sistema universitario de documentación) sean reseñados en Google Scholar, después de asegurarse de la preservación de sus intereses y de los de sus socios. El primer balance se hizo nueve meses después del arranque para este acuerdo, claro que emblemático, pero que sólo constituye un elemento de la estrategia global del Abes para asegurar una mejor visibilidad a los recursos de las bibliotecas universitarias francesas en la web.
Les premiers contacts de l’Agence bibliographique de l’enseignement supérieur (Abes) avec Google pour l’indexation du Système universitaire de documentation (Sudoc) par Google Scholar remontent au début de l’année 2006. Ils sont nés du constat que font toutes les bibliothèques : rares sont les étudiants et chercheurs commençant leurs recherches par le catalogue de leur bibliothèque. D’après une étude d’OCLC *, ils sont 89 % à lui préférer un moteur de recherche commercial, au premier rang desquels Google. À l’ère d’« Amazoogle », selon l’expression imagée de Lorcan Dempsey, directeur de la recherche à OCLC, il faut aller chercher le public là où il est, c’est-à-dire sur les moteurs de recherche et ne pas se contenter de l’attendre sur nos sites, même si la consultation de la version web du Sudoc continue de progresser régulièrement (24 millions de recherches annuelles).
Comme Google avait un projet déjà bien avancé d’indexation des catalogues collectifs nationaux (Library Link), l’Abes s’est très rapidement penchée sur la possibilité de s’associer à cette opération. Elle n’était pas pionnière en la matière puisque, outre OCLC (Open WorldCat), les catalogues collectifs de douze pays avaient alors déjà rejoint le programme « Library Link » : Suède, Suisse (Réro), Hongrie, Israël, Islande, Portugal, Australie, Chine, République tchèque, Danemark, Taïwan et Slovénie.
Avant de s’engager avec Google, l’Abes s’est informée auprès de ses partenaires suisses du réseau Réro (Réseau des bibliothèques de Suisse occidentale). Qu’il se soit agi de faisabilité technique, de protection des données, de nature des relations avec Google, d’incidence de la charge supplémentaire sur les serveurs, nos voisins nous ont persuadés de la pertinence du projet.
Une licence préservant les intérêts de l’Abes et de ses partenaires
Soucieuse de préserver les intérêts de l’Abes, des bibliothèques du réseau Sudoc et de ses fournisseurs de données, l’Agence a soumis l’accord de licence proposé par Google à l’expertise juridique d’un cabinet spécialisé : celui-ci a confirmé que le contrat d’accès de Google aux données bibliographiques provenant du Sudoc n’était cessible à aucun tiers et ne transférait pas un droit de reproduction sauf à des fins internes et de sauvegarde. Seules seraient transférées les données bibliographiques du catalogue public (les fichiers d’autorité ne sont pas concernés). La conclusion était claire : « Ce contrat [a] les caractéristiques que l’on rencontre habituellement dans les contrats de licence de données et ne comporte pas de stipulation anormale. »
Les autres craintes émises ont été rapidement dissipées :
- la licence proposée n’était pas exclusive. Le Sudoc pourrait ainsi être indexé par d’autres moteurs de recherche proposant un service similaire. Des contacts ont depuis été pris, notamment avec MSN, sans résultat jusqu’à présent ;
- aucuns frais ne seraient facturés par Google. Les développements nécessaires chez chacun des partenaires resteraient à leur charge ;
- l’Abes pouvait facilement se désengager en cas de difficultés, le contrat pouvant être dénoncé à tout moment avec un préavis de 60 jours.
Soumis au conseil d’administration de l’Abes, le projet d’accord avec Google a donné lieu à un débat nourri. La polémique autour des projets de numérisation massive de fonds de bibliothèques par Google était alors à son comble et a pu être source d’amalgame entre des projets de nature radicalement différente. Après avoir recueilli l’accord formel de ses fournisseurs de données, au premier rang desquels la Bibliothèque nationale de France, l’Abes a signé l’accord de licence le 31 octobre 2006.
Le mode de consultation est simple : à partir de la saisie d’un terme de recherche, Google Scholar affiche dans les résultats de la recherche les liens vers les notices du Sudoc et les localisations dans les bibliothèques. La visibilité des ressources documentaires des bibliothèques du réseau Sudoc en est grandement améliorée. Un bémol toutefois : si le Sudoc est systématiquement affiché par défaut pour les interrogations effectuées sur le territoire français, ce n’est pas le cas pour les utilisateurs interrogeant Google Scholar à l’étranger qui doivent cocher le Sudoc dans la liste des catalogues proposés.
Mise en œuvre technique
Les équipes de l’Abes se sont mises au travail avec leurs homologues de Mountain View immédiatement après la signature de la licence et ont abouti à une mise en production publique en avril 2007. Le projet a mobilisé une grande variété de compétences au sein de l’Abes, depuis l’étude technique jusqu’aux développements, puis aux tests d’exportations de données vers Google Scholar.
L’échange de données avec Google s’effectue au format XML qui, en permettant de structurer l’information, favorise l’échange de données via internet. Les documents peuvent être associés à un vocabulaire spécifique, défini dans une DTD ou dans un schéma : on dit que le document XML est valide s’il respecte ce vocabulaire. L’utilisation d’un vocabulaire commun facilite donc l’échange de documents.
Le format Marc, qui est le format bibliographique utilisé dans le Sudoc, peut être converti en XML : le format est donc XML, mais le vocabulaire Marc est conservé. On retrouve les mêmes informations décrivant les notices, mais présentées différemment.

L’accès aux notices du Sudoc par le moteur de recherche de Google Scholar requiert une chaîne de traitement des notices à indexer.
Dans un premier temps, un script extrait les notices en format Marc de la base Sudoc. Une extraction complète de la base a lieu une fois par semestre. Cette tâche, d’une durée d’une vingtaine d’heures, est planifiée la nuit pour ne pas surcharger les serveurs. Parallèlement, tous les mois, a lieu une extraction des nouvelles notices uniquement.
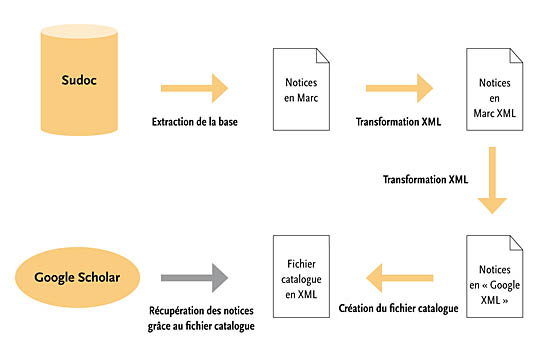
Les fichiers Marc résultants sont transformés en fichiers Marc au format XML puis, à la volée, en un format XML spécifique à Google Scholar. Ces transformations sont réalisées grâce à la technologie XSL qui permet de manipuler des arborescences XML.
Un script se déclenche alors pour parcourir les fichiers XML et fabriquer un fichier catalogue utilisé par Google pour repérer les notices.
Enfin, une date est convenue à laquelle les équipes techniques de Google Scholar utilisent le fichier catalogue pour récupérer les fichiers XML sur leurs serveurs et mettre ainsi les notices à disposition de leur moteur de recherche.
Premier bilan après le démarrage
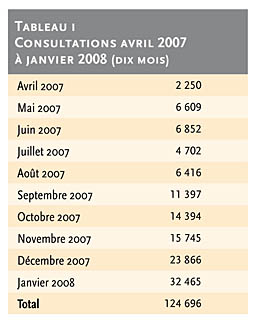
Ainsi qu’en témoigne le IMAGEtableau 1/IMAGE, le démarrage a été très progressif, le véritable décollage intervenant à fin du dernier trimestre 2007. Comparés aux 24 millions de consultations du Sudoc Web, les chiffres de consultation restent pour le moment marginaux mais, si la progression se confirme, ils pourraient représenter à terme jusqu’à 1 ou 2 points de la consultation totale du Sudoc. Des perspectives honorables, mais qui démentent le mirage entretenu parfois autour de Google d’une explosion des consultations.
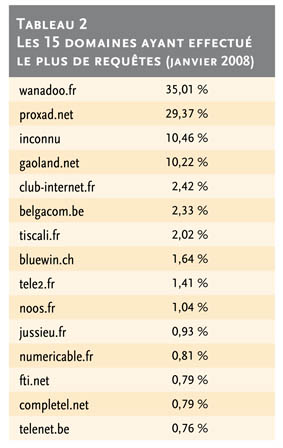
La prédominance des recherches en provenance du territoire national est imputable au mode d’affichage du Sudoc dans la page de préférences de Google Scholar (par défaut en France, volontaire à l’étranger).
La principale réserve porte sur l’indexation non exhaustive du Sudoc par Google Scholar. Le mode d’indexation de Google, sur lequel l’Abes n’a pas d’informations, exclut en effet une proportion non négligeable de documents. Des discussions sont en cours avec Google pour améliorer cette indexation.
L’indexation du Sudoc par Google est un élément de la stratégie globale de l’Abes pour assurer une plus grande visibilité aux ressources des bibliothèques universitaires françaises sur le web. Cette stratégie porte à la fois sur l’amélioration du Sudoc Web (sa customisation par les bibliothèques est prévue en 2008) et sur l’ouverture des données du Sudoc sur le web. L’accord avec Google constitue un élément de cette stratégie, sans doute emblématique en raison de la position dominante du moteur de recherche sur le marché et de sa surexposition médiatique, mais l’objectif de l’Agence est d’être encore plus présente dans une démarche proactive avec un large éventail de partenaires.
Janvier 2008