Préparation d'index par un ordinateur à l'Institut français de recherches fruitières outre-mer (IFAC)
Philippe Ariès
L'IFAC a remplacé sa publication mensuelle de résumés que complétait un index annuel par un système d'information bibliographique mécanisé : une bibliographie mensuelle de notices analytiques complétée par un index mensuel par notions, avec possibilité de cumulation. L'indexation se fait d'après un thesaurus structuré à trois niveaux où les notions sont exprimées par des phrases-clés, et non par des mots simples comme dans d'autres systèmes automatiques
Du journal de résumés aux index « automatisés »
D'abord quelques mots d'introduction sur les raisons qui ont amené l'IFAC à « automatiser » graduellement sa documentation. Il ne s'agit pas en effet d'une création ex nihilo. Depuis 1956, l'IFAC publiait, en supplément à la revue Fruits, des index annuels cumulatifs dont la philosophie et les méthodes de fabrication manuelle ont été exposées dans le Bulletin des bibliothèques de France 1.
A cette époque (de 1956 à 1965) la documentation était composée : I° d'un journal mensuel de résumés, classés par grands sujets, 2° d'index par notions, annuels, puis cumulatifs par série de cinq ans. Une formule classique.
La croissance du volume documentaire a rendu de plus en plus longues les opérations d'analyse, d'indexation et surtout de fabrication. C'est pourquoi nous fûmes contraints, dès 1964, d'étudier les moyens d'alléger la fabrication des index en la rendant automatique. Nous ne voulions en effet rien changer de la conception intellectuelle de ces index, et à aucun prix nous ne nous serions ralliés aux formules élémentaires alors proposées et expérimentées (KWIC, lexiques sommaires de mots simples).
Il s'est alors passé un phénomène qui vaut la peine d'être noté. Nous étions partis avec la volonté d'automatiser une publication ancienne, sans rien changer de notre organisation générale. Or les possibilités inattendues, introduites par ces nouvelles méthodes, nous ont empiriquement amenés à adopter un système finalement différent de celui que nous avions l'intention de maintenir.
C'est ainsi que les index automatisés sont d'abord devenus mensuels (sans renoncer aux cumulations annuelles et pluriannuelles). Ensuite, publiés dans la même livraison que le journal de résumés, ces index, désormais mensuels, ont à leur tour réagi sur l'économie des résumés et du classement des résumés.
A la fin de cette période évolutive dont les épisodes n'importent pas ici, au système ancien et classique : journal mensuel de résumés - index annuels, s'est substitué le système désormais opérationnel :
I° Une bibliographie mensuelle où les notices (auteurs - titre - références - résumés condensés) sont classées par sources d'édition (revues, congrès, brevets...) et dans l'ordre alphabétique des noms de ces sources. Elles sont numérotées dans cet ordre, à la suite, et sans interruption depuis 1956 (c'est le numéro d'accès au document);
2° Les index par notions, tels qu'ils étaient auparavant, mais devenus aussi mensuels.
D'autre part, le long résumé du document, rédigé comme un petit article, a été remplacé par un, ou plusieurs, brefs condensés, écrits en style télégraphique, et préparés comme les compléments, propres au document, des différentes notions du thesaurus choisies pour le désigner. Le plus complet de ces condensés est répété à la fin de la notice bibliographique.
C'est ce système qu'il convient maintenant de décrire tel qu'il est, sans plus se préoccuper de ses origines. Il suffisait seulement d'indiquer dans quelles conditions empiriques il avait été conçu et adopté... sinon imposé.
La structuration à l'entrée.
On a trop l'habitude de distinguer les systèmes automatisés en opposant les éditions d'index à l'interrogation directe par la machine, dite aussi recherche aléatoire. Certes les résultats ne sont pas équivalents et on peut légitimement discuter de l'efficacité et de la rentabilité de ces deux procédés. Mais il ne s'agit en réalité que des différences entre deux manières d'exploiter un même fichier. A l'alphabétisation près (nécessaire pour un index publié, inutile pour une recherche directe), le fichier peut être le même dans l'un et l'autre cas. Ce qui importe, c'est moins le procédé d'exploitation que les principes et la philosophie qui ont déterminé l'organisation du fichier et qui s'expriment par les méthodes d'indexation du document et par le choix du langage documentaire. C'est surtout à ce niveau, plutôt qu'à celui de la sortie, que se distinguent ou s'opposent les systèmes de documentation automatique.
Ou bien il n'y a pas d'indexation, et la machine permet de permuter les mots d'un titre parfois amélioré, ce sont les index KWIC - ou bien il y a indexation, c'est-à-dire qu'on affecte au document un certain nombre de mots ou d'expressions linguistiques, (mots-clés, descripteurs...) : dans ce cas, il existe deux méthodes pour mettre le document en mémoire, qu'il importe de bien distinguer. On comprendra mieux à l'aide d'un exemple.
Soit le document qui traite des dégâts du froid atmosphérique sur les oranges en Californie.
Première manière : on indexe le document à chacun des mots caractéristiques :
Dégâts.
Froid atmosphérique.
Oranges.
Californie.
Donc quatre notions distinctes.
Pour retrouver ce document quand on interroge la mémoire (soit directement, soit d'après un index), il faut demander à la machine de sortir les documents traitant à la fois des dégâts et du froid atmosphérique, et des oranges, et de la Californie.
Cela impose d'ailleurs une méthode d'interrogation plus élaborée (afin d'éliminer les parasites), que les spécialistes appellent : une stratégie de recherches. Retenons seulement ici que l'expression sémantique qui définit le document est reconstituée au moment de poser la question. Elle n'entre pas avec le document dans la mémoire.
Deuxième manière : c'est l'expression sémantique, nécessairement élaborée, telle qu'elle ressort de l'examen du document, qui est entrée en mémoire. Autrement dit, on utilise dès l'entrée des structures complexes qui dans le cas précédent servaient seulement à la sortie.
Cette méthode est celle de l'IFAC. Dans l'exemple proposé, dégâts dus au froid atmosphérique des oranges en Californie, nous indexerons selon les notions suivantes :
I° Dégâts des oranges dus au froid atmosphérique (c'est une seule notion);
2° Orange - défense des cultures;
3° Californie - défense des cultures d'orangers.
Un thesaurus de phrases-clés.
De tels morceaux de phrases constituent la matière du thesaurus de l'IFAC.
Comment sont-ils obtenus ? Imaginons que nous ayons résumé un grand nombre de documents. Nous remarquons que ces résumés contiennent des éléments sémantiques communs. Nous retirons ces éléments, nous les mettons pour ainsi dire en facteur commun : les morceaux de phrase ainsi obtenus sont les phrases-clés du thesaurus. Dans le cas cité : Dégâts dus au froid atmosphérique des oranges, ou encore, épandage des engrais dans les vergers d'orangers, altération du fruit d'ananas congelé, etc.
Quand une phrase est commune à un nombre suffisant de documents, elle est donc considérée comme une phrase-clé, elle décrit une notion. Mais on comprend facilement qu'un thesaurus ne peut être présenté sous la forme d'une liste de milliers de phrases-clé d'au moins trois mots (sans compter les prépositions et les conjonctions). Il ne serait pas consultable.
Afin de permettre la consultation du thesaurus aussi bien pour l'indexation que pour la recherche, il faut donc décomposer les phrases-notions et les présenter sous la forme d'une liste de mots simples, comparables et alphabétisables. Notre usager cherche dans le thesaurus les mots qui lui viennent à l'esprit, il les cherche comme dans un dictionnaire. Mais à partir de ces mots en apparence simples, il va être aussitôt sollicité vers la phrase dont ces mots sont sortis après éclatement. En effet ces mots sont coordonnés entre eux, et la présentation graphique impliquera cette coordination, de telle manière que le lecteur reconstituera spontanément la phrase non écrite qui est cependant la véritable unité notionnelle.
Ainsi, si l'indexation est faite selon des expressions linguistiques complexes, le thesaurus, lui, est présenté sous forme d'un dictionnaire de mots « simples » tels qu'ils viennent naturellement à l'esprit du lecteur, mais il les coordonne aussitôt et conduit s ans retard l'usager vers la formule complexe qui a servi pour indexer le document et pour l'entrer dans la mémoire. Le thesaurus conduit donc l'usager des mots simples aux expressions complexes. Dans d'autres systèmes l'interrogateur suit le chemin inverse et la stratégie de recherches lui permet d'aller de la question complexe aux mots simples de l'indexation originelle.
Comment se fait la décomposition de la phrase en mots coordonnés ?
La phrase : « Dégâts dus au froid atmosphérique des oranges » s'écrira :
Froid atmosphérique (considéré comme un mot simple).
- Dégâts.
. Orange.
Les phrases sont décomposées en trois catégories de mots, que nous appelons mot I, mot 2, mot 3, (parce qu'ils sont codés par la perforation de I, de 2 ou de 3 dans la colonne 1 de la carte mécanographique). Les mots 2 sont précédés d'un tiret et les mots 3 d'un point.
Le classement des mots dans les catégories 1 ou 2 dépend de leur précision sémantique (et non pas de la place fixée par la syntaxe). Les mots de la première catégorie ont un sens sans équivoque (par exemple feuille, froid atmosphérique,...) les mots de la seconde catégorie (2) sont affectés de polysémie et leur sens ne se restreint que s'ils sont associés à un mot de la première catégorie (dégâts). Les mots de la troisième catégorie sont toujours des fruits.
On a donc quatre combinaisons possibles :
I° - le mot 1 isolé : froid atmosphérique. De tous les mots du thesaurus, le mot 1 est le seul qui, isolé, signifie une notion;
2° - mot 1 et mot 3 : Les feuilles (I) d'oranger (3);
3° - mot 1 et mot 2 : Les dégâts (2) dus au froid atmosphénque (I);
4° - mot 1 et mot 2 et mot 3 : Dégâts (2) dus au froid atmosphérique (I) des oranges (3).
Le thesaurus se présente donc graphiquement comme une série de groupes commandés par des mots 1 (pl. I). Ces groupes sont classés dans l'ordre alphabétique des mots 1 qui les commandent. A l'intérieur de chacun de ces groupes, les mots 2 sont alphabétisés séparément, ainsi que les mots 3. Donc trois séries d'alphabétisation à chaque niveau 1, 2, 3. Mais on insistera bien sur le fait qu'il s'agit seulement d'une présentation formelle pour la lecture du thesaurus, et aussi (on le verra) d'une astuce pour l'entrée en mémoire et pour éviter de trop longues perforations. En réalité, les mots autres que les mots 1 n'existent pas par eux-mêmes. Leur sens dépend de leur association entre eux. La présentation en trois niveaux permet au lecteur de reconstituer facilement le morceau de phrase qui est à l'origine et qui est la véritable notion.
Il est possible de coder le thesaurus en affectant à chaque mot, dans l'ordre de l'alphabétisation à trois niveaux, un numéro selon une série continue (sans tenir compte des positions de niveaux en 1, 2 ou 3) de I.000 en I.000, afin de permettre des intercalations de mots nouveaux à leur place alphabétique. C'est ce que nous faisons afin d'éviter de trop longues perforations et de trop coûteux triages sur machine. La recherche se fait sur des nombres de 6 chiffres, en zone fixe : nous savons les inconvénients de cette méthode; elle a cependant l'avantage d'être très économique. L'utilisation d'un thesaurus structuré sans codage exigerait qu'à chaque entrée, on perfore l'expression complète 1 + 2 + 3. Nous nous contentons d'un nombre qui, avec 6 ou 8 chiffres, peut signifier 1 + 2 + 3.
Les « condensés » du document.
Le thesaurus de l'IFAC est donc un thesaurus structuré en unités linguistiques composées de trois catégories d'éléments simples.
Or, même à ce degré d'organisation, la notion du thesaurus ne suffit pas à caractériser le document. Il faut que cette notion, par définition banale, soit replacée dans le contexte propre au document. Un rapport s'établit alors entre le caractère nécessairement banal de la notion du thesaurus et le caractère toujours particulier du document.
C'est pourquoi, lors de l'indexation, nous ajoutons à chaque notion du thesaurus qui a été choisie pour l'entrée en mémoire du document un résumé condensé, écrit entre parenthèses. Le condensé est moins une analyse ou un résumé, au sens qu'avaient ces mots dans le traditionnel journal de résumés, qu'un supplément à la notion du thesaurus : la notion du thesaurus et le condensé entre parenthèses constituent un ensemble complet.
Chaque indexation se décompose donc ainsi : notion du thesaurus, n° d'accès au document, résumé condensé du document.
Le résumé varie bien selon la notion du thesaurus qu'il complète et particularise. Toutefois, pour des raisons d'économie de perforation on tend (malheureusement) à réduire le nombre des libellés de résumés d'un document, tant que c'est possible sans déformer le sens de l'indexation. Aussi est-il fréquent qu'un même résumé soit commun à plusieurs notions. Cette tendance risque de s'accentuer avec l'augmentation du nombre des documents et par conséquent des indexations.
Deux exemples d'indexation d'un document.
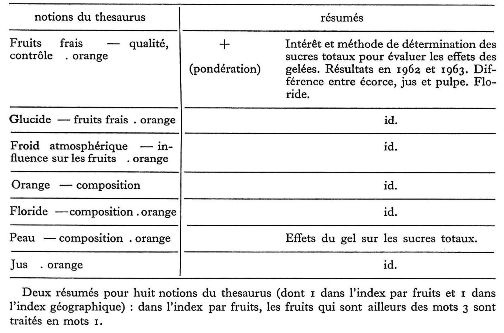
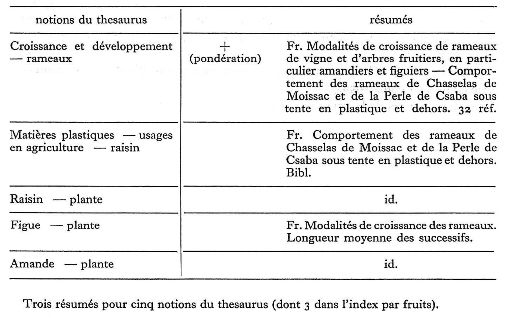
Dans chacun des deux exemples d'indexation complète de document ci-dessous, on a noté le signe + à l'un des endroits de l'indexation. Voici ce qu'il signifie : Parmi le nombre parfois élevé des notions choisies pour décrire un document, il en est toujours une, plus importante, qui caractérise le sujet. Cette notion, et le résumé qui l'accompagne, sont alors affectés du signe +.
Le signe + placé devant la parenthèse qui annonce le résumé signifie donc que la notion correspondante est la plus importante, et aussi que le résumé qui l'accompagne est le plus complet. Aussi ce résumé là est-il rédigé comme une notice descriptive, aussi complète que possible du document tout entier.
Premier exemple (voir figure)
Deuxième exemple (voir figure)
L'entrée des informations.
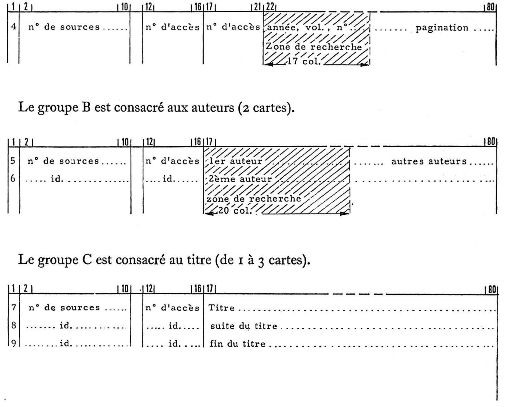
Étudions maintenant l'entrée des informations dans le système. Le support est la carte perforée.
Toutes ces cartes ont le même dessin général.
Sauf deux cas très particuliers (références et auteurs), il ne se fait pas de recherches dans la zone 17 à 80.
La zone code où se font toutes les recherches comprend trois parties :
I° la col. I. Code d'un chiffre définissant la nature de l'entrée : s'il s'agit d'une notion du thesaurus (I, 2, 3), s'il s'agit d'une information extraite d'un document (4, 5 ... 9).
2° de la col. 2 à la col. 10. Zone réservée à un nombre qui signifie soit une notion du thesaurus, soit une source de la littérature, selon que l'information concernée traite du contenu du document (cas du thesaurus-notions) ou des données bibliographiques (cas des sources). Nous considérons en effet la liste des sources (périodiques,'brevets, congrès etc.) comme un second thesaurus. Tout se passe comme si nous avions deux thesaurus : un grand thesaurus de notions et un petit thesaurus de sources.
3° de la col. 12 à la col. 16. Zone réservée au numéro d'accès au document : série continue depuis 1956.
Ces trois parties de la carte mécanographique se retrouvent dans les trois types d'entrées : entrées dans le fichier thesaurus, entrée dans le fichier bibliographique, entrée dans le fichier documentaire (voir figure).
Dans la zone 2 à 10, on perfore le numéro correspondant à la notion qu'on veut introduire, numéro encore jamais utilisé.
La zone 12 à 16 n'est pas utilisée, puisqu'elle est réservée au numéro d'accès d'un document.
Dans la zone 17 à 80, on perfore en alphanumérique le libellé du mot tel qu'il devra apparaître dans les éditions imprimées de l'index ou du thesaurus.
Le fichier thesaurus, sur bande, sera donc un fichier direct, dans l'ordre des numéros de code, qui correspondent à l'ordre alphabétique des mots en clair. L'alphabétisation des notions est une des difficultés de la préparation des index, quand on veut éviter de coûteuses comparaisons en machine.
Le fichier thesaurus est donc constitué par le code I, ou 2, ou 3 de la colonne I, par le numéro de notion, et par le nom de la notion, en clair.
Le fichier bibliographique.
Le fichier bibliographique est constitué par le numéro d'accès au document et par la notice bibliographique complète (références, auteurs, titre). C'est un fichier direct, dans l'ordre des numéros d'accès au document. C'est l'arrivée du document dans le fichier qui commande le choix de ce numéro, dans un ordre simplement séquentiel. Toutefois, on ne peut, dans un index publié, numéroter selon l'ordre chronologique de l'exploitation des documents. Les notices bibliographiques doivent être présentées dans un ordre autre que celui de leur arrivée dans le service et de leur dépouillement (ce qui au contraire est le cas quand il s'agit d'une mémoire destinée seulement à l'interrogation directe). Nous avons choisi l'ordre alphabétique des sources. Ce fichier est donc à la fois un fichier direct des documents numérotés à la suite, et un fichier inversé dans l'ordre alphabétique des sources. La coïncidence entre ces deux ordres sera assurée en 1968 par la machine 2. Les indexateurs et analystes ne connaîtront qu'une série numérique provisoire dans l'ordre de l'exploitation; la machine constituera ensuite un fichier inversé dans l'ordre alphabétique des sources, renumérotera définitivement à la suite les documents, et reportera enfin ces numéros définitifs à la place des nombres provisoires utilisés pendant l'exploitation.
La notice bibliographique est décomposée en trois groupes, A, B, C.
Dans tous ces groupes, la zone réservée au thesaurus (col. 2 à 10) sera consacrée au numéro de sources (à l'exclusion des notions : les notions n'ont rien à faire dans ces notices bibliographiques). Le thesaurus utilisé ici est le thesaurus des sources.
Le groupe A est consacré aux références (I seule carte). Voici son dessin.
Pour un même document, la zone 2 à 10 et la zone 12 à 16 sont toujours identiques dans les trois groupes A, B, C, puisqu'il s'agit toujours de la même source et du même numéro d'accès. Seule change la perforation de la col. I.
Actuellement ce fichier est encore manuel. Il sera mis sur bande magnétique au début de 1968.
Le fichier documentaire (Pl. 3).
C'est le fichier essentiel, avec celui du thesaurus. Il est automatisé depuis 1965. C'est un fichier inversé : les documents représentés par leur numéro d'accès et par un résumé de 1 à 6 lignes, sont classés dans l'ordre des numéros de notions. On compte en moyenne pour un document 5 à 6 notions.
Dans les cartes qui servent à l'entrée dans le fichier documentaire, la zone 2 à 10, la zone thesaurus, sera toujours réservée au thesaurus par notions. Il n'est plus question ici des sources.
Le dessin de la carte est donc le suivant (voir figure).
L'édition mensuelle des index.
Nous disposons donc de deux fichiers thesaurus (un thesaurus par notions, un thesaurus des sources), d'un fichier bibliographique et d'un fichier documentaire.
La combinaison de ces différents fichiers permet d'abord l'édition mensuelle des index.
I° L'index bibliographique par sources donne pour chaque document dans l'ordre des numéros d'accès : les références, les auteurs et le titre. Il est obtenu :
a) par comparaison du thesaurus-sources et du fichier bibliographique du mois (d'après les numéros codes du thesaurus-sources), afin de réunir tous les documents extraits d'une même source sous le nom de cette source.
b) par comparaison du fichier bibliographique et du fichier documentaire (d'après les numéros d'accès) afin de reporter à la suite de la notice bibliographique de chaque document le résumé précédé d'un + qui se trouve à la principale entrée par notions de ce document dans le fichier documentaire.
2° L'index par notions donne pour chaque notion concernée, les numéros d'accès au document complétés par un résumé. Il est obtenu par la comparaison du fichier documentaire du mois et du fichier thesaurus des notions (d'après les numéros de notions). Mais la structure ternaire du thesaurus exige une opération supplémentaire.
Quand le numéro de notion correspond à un mot 3, c'est-à-dire à un nom de fruit, ce mot seul ne signifie rien. Il faut que la machine recherche le mot 2 et le mot 1 qui, en s'associant à lui, lui donnent son sens réel. La machine remonte donc dans le fichier thesaurus pour retirer le premier mot 2 qu'elle rencontre en avant du mot 3 que représente le numéro de notion du fichier documentaire, puis à partir de ce mot 2, le premier mot I. La machine reconstitue donc la présentation en trois niveaux des mots du thesaurus, en y ajoutant, bien entendu, les numéros d'accès au document concerné, et les résumés de ce document (Pl. 2 et 3).
Les fichiers annexes.
Outre ces index qui sont publiés dans la revue mensuelle Fruits, d'autres fichiers cumulatifs sont prévus, à l'usage seulement du Centre de Documentation de l'IFAC, et comme sous-produits de la préparation des index.
I° Le fichier auteurs :
Il est obtenu par le reclassement du fichier bibliographique dans l'ordre alphabétique des deux principaux auteurs.
2° Le fichier de contrôle et de dépouillement des sources :
Il est obtenu en reprenant les informations du groupe A du fichier bibliographique (carte consacrée aux références). Ces informations sont classées dans l'ordre des sources (thesaurus-sources) et pour chaque source, selon l'année, le volume, le numéro.
Toutes les autres informations sont effacées, et remplacées par une statistique du nombre de documents extraits de chaque fascicule. Une interruption dans la série des années, volumes, numéros sera signalée par la machine comme une anomalie 3.
Ces deux cas (fichiers auteurs et fichiers de contrôle des sources) sont les seuls où une recherche est faite en dehors de la zone 1 à 16 de la carte mécanographique.
Conclusion.
On entre donc dans la mémoire pour chaque document :
I° les notions nouvelles du thesaurus et leurs numéros;
2° le numéro d'accès du document;
3° les auteurs;
4° le titre;
5° 5 à 6 résumés (identiques ou différents) correspondant à 5 ou 6 notions du thesaurus, désignés par leurs numéros.
Ces données permettent d'obtenir à la sortie :
I° un index bibliographique dans l'ordre alphabétique des sources et des numéros d'accès;
2° des index dans l'ordre alphabétique des notions (index analytique général, index par fruits, index par pays), où la notion du thesaurus est complétée chaque fois par un résumé.
Ces index peuvent être cumulés comme on le désire;
3° une édition à jour des thesaurus;
4° un fichier auteurs;
5° un fichier de contrôle des périodiques.
Toutefois le système ne se limite pas à ces utilisations actuelles. Rien n'interdit d'interroger le fichier documentaire selon les méthodes de la recherche aléatoire, sans passer par l'intermédiaire manuel des index imprimés. Cependant la « stratégie » sera alors simplifiée, puisque l'on ne combinera pas des mots simples, mais des expressions sémantiques déjà élaborées : on gagne donc une étape. Reste à savoir si la consultation manuelle d'index cumulés (complets ou partiels) n'est pas préférable : grammatici certant. Nous pensons qu'ils permettent de déborder le sujet étroit de la recherche, de voir à côté, dans les rubriques voisines. Tel qu'il est cependant, le système permet indifféremment la préparation d'index alphabétiques, la diffusion sélective, la recherche aléatoire.