Éléments d'un modèle pour la description des lexiques documentaires
La lexicographie naturelle qui vise à observer certains faits concernant les occurrences de mots dans une langue donnée (glossaires, thesaurus), se définit par opposition à la lexicographie documentaire qui aboutit à une liste de termes organisés ou non, destinés à l'indexation automatique ou non, et dont les classifications sont un groupe parmi d'autres.Le fondement des classifications peut être d'organisation sémantique (ordre des termes fondé sur l'essence des entités qu'ils désignent, le cas-limite étant la taxinomie), ou d'organisation syntaxique (ordre des termes fondé sur la fonction des entités dans un champ d'observation déterminé, le cas-limite étant la facette)
Le texte de M. J. C. Gardin que l'on trouvera ci-après est une contribution à la méthodologie des lexiques documentaires. Il a été écrit en février 1965 à l'intention d'un groupe de travail créé par la Délégation générale à la recherche scientifique et technique pour la mise au point de cette méthodologie.
Il n'est pas besoin de souligner l'importance des problèmes soulevés par M. Gardin qui se borne d'ailleurs à faire des propositions.
La typologie des lexiques documentaires qu'il présente appellera certainement des observations aussi bien de la part de ceux qui sont familiarisés avec les moyens traditionnels de la recherche documentaire que de la part de ceux qui expérimentent les méthodes les plus nouvelles ; des retouches pourront être suggérées à telle ou telle définition mais les tableaux de M. Gardin permettent, avec beaucoup de clarté, de situer les diverses formes de lexiques les unes par rapport aux autres.
Notre propos en publiant cette étude est de stimuler l'intérêt pour les études de lexicologie documentaire dont on sait qu'elles conditionneront en grande partie la réussite ou l'échec de l'automatisation de la recherche.
On travaille ici et là à l'établissement de thésaurus pour des domaines plus ou moins spécialisés ; il serait souhaitable que, le plus rapidement possible, des règles communes concernant leur établissement puissent être appliquées.
Le groupe de travail auquel a appartenu M. Gardin a d'ailleurs procédé à plusieurs études qui ont été multigraphiées. Nous en donnons la liste :
Brygoo (P. R.). - Le lexique documentaire du Service de documentation de l'Institut Pasteur, 46 p.
Brygoo (P. R.). - Modèle descriptif de lexique documentaire, 24 p.
Chonez (Nicole). - Préparation des bibliographies auto-indexées « Physindex ». Application à l'élaboration de vocabulaires spécialisés.-Centre d'études nucléaires de Saclay, mai 1964 (Commissariat à l'énergie atomique. Service de documentation. Groupe automatisation des fonctions documentaires, note AFD 44), 28 p.
Levery (F.). - Constitution et utilisation du lexique au cours de l'expérience de sélection automatique de documentation IBM-Saint-Gobain, 8 p.
Lévy (F.). - [Note sur les lexiques documentaires et plus particulièrement sur le lexique établi en 1962 et 1963 par le Centre d'analyse documentaire pour l'Afrique noire (CADAN)], 23 p.
Pagès (Robert), Gardelle (Marie-Claude), Vataire (Danièle), Duflos (Marie-Thérèse). - Note préliminaire sur un lexique d'analyse codée. - Paris, juin 1964 (Service de documentation du Laboratoire de psychologie sociale de la Faculté des lettres et sciences humaines de l'Université de Paris), 66 p.
Roger (J.). - Lexique documentaire. Sciences de la terre, 30 p.
Russo (F.). - Lexique pour l'analyse documentaire en histoire des sciences et des techniques, 2I p.
Russo (F.). - Observations [sur les lexiques documentaires], 6 p.
I. - Définitions préalables
Rappelons d'abord ce que nous entendons par Lexique documentaire : « tout ensemble de signes (mots naturels, symboles alpha-numériques, etc.), organisé ou non, servant à construire les représentations indexées de certains documents ».
Les termes même de cette définition appellent peut-être quelques précisions :
a) « signes » : dans une acception délibérément générale, tout symbole désignant les éléments de l'ensemble lexical (mots-clé, descripteurs, termes d'indexation, etc.), que ces symboles soient empruntés ou non à une langue naturelle, « en clair » ou « codés », alphabétiques ou numériques, etc.
b) « organisé » : présenté dans un ordre inspiré non par la forme des signes (ex. : l'ordre alphabétique), mais par leur signification (ordre sémantique, conceptuel, etc.). Les lexiques « non organisés » sont par conséquent ceux qui ne sont munis d'aucune structure sémantique, les signes étant présentés dans un ordre soit indifférent, soit purement formel (ordre des lettres, ordre des nombres, etc.).
c) « représentations (indexées) » : toute expression de certaines caractéristiques des documents traités : caractéristiques de forme (ex. : type de publication, format, langue, etc.) ou de contenu (ex. : disciplines, sujets, notions, etc.) - au moyen des signes précédents.
d) « documents » : tout objet, au sens large (objet concret, image, texte, etc.), considéré comme unité d'analyse et/ou de référence, dans les travaux d'indexation.
Les lexiques documentaires, ainsi définis, présentent une grande variété de formes, diversement nommées : glossaires, thésaurus, listes de mots-vedette, codes sémantiques, classifications, etc. L'objet de cette note est de proposer les éléments d'un modèle permettant de faire apparaître les traits distinctifs de chacun, et partant, les analogies et les différences observables d'un type de lexique à l'autre, indépendamment des appellations souvent changeantes qui leur sont données.
Parmi ces appellations, la plus courante est sans doute «classifications ». Dans un premier temps, nous proposerons une typologie générale des lexiques documentaires où les classifications sont définies comme un groupe parmi d'autres (§ II); puis nous reprendrons ce groupe particulier pour tenter de l'ordonner à son tour en fonction d'un nombre restreint de propriétés structurelles (§ III).
II. - Typologie générale
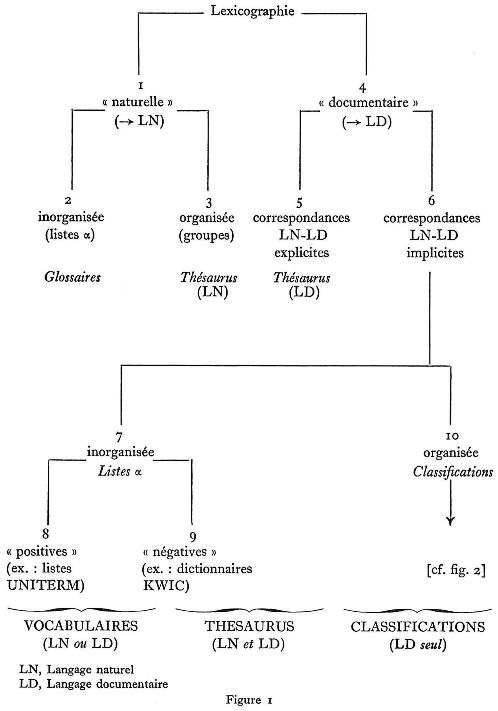
La figure 1 résume les principaux critères de la typologie proposée :
I. En premier lieu, la « lexicographie documentaire » (i.e. l'étude des lexiques documentaires ou de leurs modes de construction) est opposée à la lexicographie naturelle, comme l'entendent ou la pratiquent les linguistes à propos de langues naturelles quelconques. La première vise à l'établissement de listes finies de mots 1, toujours limitatives par rapport au vocabulaire de la langue naturelle dont elles sont dérivées, ces listes devant servir d'une manière ou d'une autre à la formulation de représentations indexées, plus courtes et plus stéréotypées que les expressions naturelles correspondantes. La lexicographie naturelle, en revanche, n'a pas cette fonction réductrice ou normalisatrice : elle vise seulement à observer certains faits concernant les occurrences de mots dans une langue donnée, à travers un corpus particulier.
S'il nous a paru nécessaire de faire une place à la lexicographie naturelle dans cette typologie, c'est que certains de ses produits sont en fait utilisés dans les travaux documentaires, parallèlement aux lexiques documentaires proprement dits; tel est notamment le cas des « glossaires » et des « thésaurus » définis ci-dessous (§ 2 et 3).
2. Par glossaires, nous entendons ici, conventionnellement, tout ensemble de termes naturels présentés dans un ordre non-signifiant, alphabétique par exemple : listes de termes techniques, vocabulaires spécialisés (bilingues, multilingues), microglossaires, dictionnaires scientifiques, etc. Dans ces glossaires, les termes peuvent être accompagnés de définitions, d'exemples, de traductions, etc.; en revanche, toute indication d'équivalence ou de voisinage entre les termes est en principe exclue (synonymes, formes canoniques, etc.), dans la mesure où le glossaire se rapproche alors d'un « thésaurus », dans l'un ou l'autre des sens ci-dessous (§ 3 et 5).
3. Ces mêmes ensembles de termes naturels peuvent être « organisés », c'est-à-dire groupés en vertu d'affinités sémantiques : dictionnaires de synonymes, associations d'idées, dictionnaires conceptuels, thésaurus, etc... C'est ce dernier mot que nous avons retenu pour désigner conventionnellement les lexiques naturels accompagnés d'indications sémantiques de ce genre. Précisons que l'ordre de présentation des entrées lexicales, dans les thésaurus ainsi définis, peut être indifféremment alphabétique (ex. : la version américaine du Thésaurus de Roget) ou conceptuel.
4. La lexicographie documentaire a été définie plus haut, par opposition à la lexicographie naturelle (§ I). Nous y distinguons deux grands courants : l'un, le plus ancien, aboutit à la constitution de listes de termes, organisées ou non, qui doivent servir à l'indexation documentaire, sans toutefois que soient explicitement données les correspondances entre chacun de ces termes et les mots ou phrases naturels qu'ils sont censés représenter. L'autre, au contraire, vise essentiellement à l'inventaire de ces correspondances, de telle sorte que le processus d'indexation puisse être régularisé jusqu'à être pris en charge par un automate quelconque. C'est ce dernier genre d'inventaire que nous définirons tout d'abord ci-dessous.
5. Partant des lexiques naturels envisagés précédemment (§ 2 et 3), il est facile d'imaginer que l'on puisse associer à chaque entrée une forme canonique destinée à servir de terme d'indexation, dans l'analyse documentaire. L'on établit ainsi une sorte de dictionnaire bilingue (ou multilingue), avec, « à gauche », les termes ou expressions d'une ou plusieurs langues naturelles, et « à droite », les équivalents canoniques du lexique documentaire adopté. Ces dictionnaires, que l'on nomme « dictionnaires automatiques » dans le domaine de la traduction mécanique, sont souvent désignés sous le nom de thésaurus dans les études consacrées à la documentation, par analogie avec les dictionnaires conceptuels envisagés plus haut (§ 3), dont ils sont en effet une sorte de développement. Nous avons conservé cet usage, en proposant cependant de distinguer les deux variétés de thésaurus par un suffixe : LN dans le premier cas (où seul le langage naturel est pris en considération), LD, dans le second (où l'on vise à ramener la terminologie naturelle à une base lexicographique donnée, dans un langage documentaire).
6. La recherche d'un système de correspondances entièrement explicite, entre termes naturels et termes d'indexation, est cependant une entreprise très récente; on n'en pourrait guère citer plus d'une dizaine d'exemples à ce jour. Le plus souvent, les termes d'indexation sont présentés sous forme de listes en quelque sorte autonomes, sans référence à leur image dans telle ou telle langue naturelle; les correspondances restent implicites, dans l'esprit des auteurs comme des utilisateurs de ces listes. Tel est le cas notamment des « classifications » innombrables dont on se sert dans les bibliothèques et les centres de documentation, où l'analyste n'a généralement à sa disposition que sa propre culture - « implicite » - pour interpréter tel ou tel texte dans les termes de telle ou telle classification.
Une manière d'objectiver cette interprétation sans avoir à construire les difficiles dictionnaires d'équivalences examinés au paragraphe précédent est de renoncer à l' « indexation » proprement dite - où l'on remplace fréquemment un mot ou une expression du langage naturel par un terme tout autre - pour se contenter d'une simple « extraction », où l'on retient un certain nombre de mots ou phrases du texte original, jugés particulièrement représentatifs de son contenu, sans leur faire subir aucune transformation 2.
Cette sélection est parfois laissée à la discrétion de l'analyste (cf. la méthode dite du « crayon rouge »...); ailleurs, elle est le résultat de certains calculs statistiques (cf. les méthodes de H. P. Luhn et de ses épigones). Mais elle peut aussi être obtenue par une simple consultation de tables, où l'on trouve, dans l'ordre alphabétique, les termes admis (ou au contraire exclus) dans les représentations documentaires visées. Ce sont ces tables que nous examinerons maintenant.
7. Ces listes alphabétiques ne doivent pas être confondues avec les « glossaires » définis plus haut ( § 2) : elles ne concernent pas la totalité des termes naturels, dans un domaine scientifique ou technique donné, mais seulement une sélection de ces termes, retenus pour les besoins de la représentation documentaire. C'est d'ailleurs en ce sens qu'elles appartiennent à la famille des « lexiques documentaires » plutôt qu'à celle des « lexiques naturels ».
8. Le cas le plus fréquent est celui des listes dites positives, où l'on énumère - variantes morphologiques incluses ou exclues (cf. note précédente) - les mots et groupes de mots que l'on considère à priori comme dignes d'être retenus, dans l'énoncé naturel d'un document (titre, résumé, ou texte intégral), pour en représenter le contenu. L'analyse devrait ici se ramener à une consultation de table, confiée indifféremment à un clerc ou à un automate.
Les listes dites « Uniterm », aux États-Unis, ont souvent été définies dans cette perspective de l'extraction. L'on pourrait dès lors contester la position où nous les avons mises, parmi les lexiques documentaires où les correspondances sont « implicites », avec le langage naturel : si la langue naturelle choisie pour désigner les « uniterms » est la même que celle des textes analysés, ces correspondances ne sont en effet omises que dans la mesure où elles sont données par construction... Il reste que rares sont encore, en fait, les listes dont l'emploi réponde à une définition aussi stricte :
a) les variantes morphologiques des bases enregistrées comme « uniterms » restent implicites le plus souvent;
b) de même, leurs équivalents dans la terminologie (ou dans la phraséologie) de langues naturelles différentes, pourtant soumises au même processus de réduction par référence aux mêmes listes.
Une large part est ainsi laissée à l'interprétation de l'analyste; c'est pourquoi nous avons placé ces listes dans la catégorie des lexiques documentaires sans correspondances explicites avec le langage naturel, à l'inverse des thésaurus précédents (§ 5), en les distinguant seulement par le caractère « inorganisé » de leur présentation, à l'inverse des classifications (§ III).
9. Une autre manière de contrôler l'extraction est d'établir à priori une liste non plus des termes admis, mais des termes exclus : sont alors retenus comme critères de repérage, pour un document quelconque, tous les termes trouvés dans l'énoncé de ce document qui n'appartiennent pas à la table des mots exclus (mots-outil, formules d'introduction, etc.). Ces listes négatives sont utilisées principalement pour la fabrication automatique des index de permutation, diversement nommés (KWIC, Tabledex, Wadex, Physindex, etc.).
N. B. Un dictionnaire « négatif » ne définit évidemment pas un lexique documentaire, stricto sensu : ce dernier n'est que le « complément » du dictionnaire, au sens logique du terme, dans une langue naturelle donnée. D'autre part, les correspondances entre lexique naturel et lexique documentaire ainsi défini n'ont nul besoin d'être explicites, pour les mêmes raisons que précédemment (§ 8). C'est donc par abus, si l'on veut, que les dictionnaires négatifs sont cités ici, en considération de l'analogie de leur forme (« inorganisée ») et de leur visée (l'extraction) par rapport aux listes précédentes (§ 8).
10. Les listes « positives » de mots-clé rangés par ordre alphabétique sont souvent accompagnées de renvois, qui les apparentent en fait à des classifications : écrire « a, voir aussi b, etc. » est une manière d'indiquer qu'il existe un certain rapport entre a et b, comme l'exprimerait un ordre classificatoire tel que :
C (classe, terme générique, etc.)
- a
- b etc.,
ou encore :
- a (terme générique)
- b (terme spécifique) etc.
Ces mêmes listes ne sont d'ailleurs parfois que l'index alphabétique des termes appartenant à une classification déterminée; ce sont ces classifications que nous examinerons maintenant.
III. - Classifications
Par « classifications », rappelons que nous entendons ici tout ensemble organisé de termes destinés à l'indexation documentaire, quel que soit le procédé utilisé pour exprimer l'organisation en question (renvois, listes, codifications, etc.). a) « ... termes destinés à l'indexation... » : cette restriction n'est là que pour rappeler l'opposition énoncée plus haut entre les organisations sémantiques définies dans un lexique naturel (« thésaurus », § 3 ci-dessus) et celles qui sont définies dans les limites d'un lexique documentaire. Le terme « classification » est ici réservé aux secondes, par convention.
b) « ... quel que soit le procédé utilisé pour exprimer l'organisation... » : cette autre restriction vise à écarter de notre sujet, au moins dans un premier temps, les observations relatives aux codes associés à telle ou telle classification (système décimal, symboles alphanumériques, affixes, etc.).
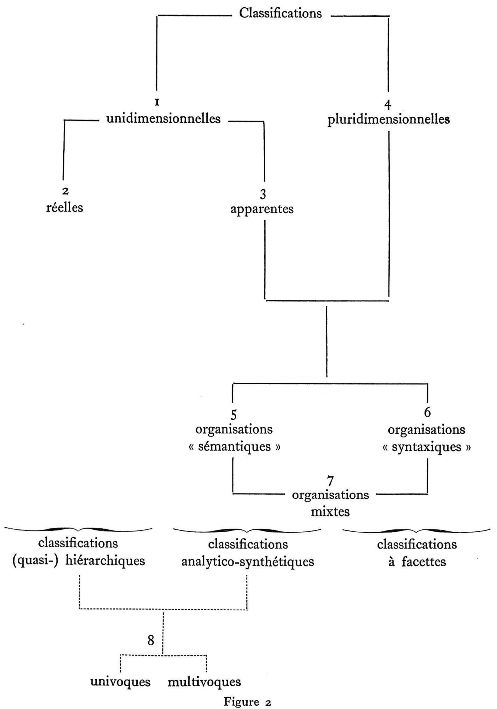
C'est en effet par leurs traits structurels qu'il semble raisonnable de définir les principaux types de classification documentaire, et non par l'emploi qu'elles font de telle ou telle recette symbolique. Une caractéristique majeure, à cet égard, est le nombre des relations analytiques 3 prises en compte pour organiser le lexique : tel est l'objet de la première distinction posée à la figure 2, entre classifications « unidimensionnelles » et « pluridimensionnelles ».
I. Par « dimensions » d'une organisation lexicale, nous entendons la nature des relations analytiques qui la constituent. Une classification est unidimensionnelle, par conséquent, lorsqu'elle prend en compte une relation analytique et une seule. Tel est le cas de l'immense majorité des classifications établies à ce jour, où seule la présence d'une relation est marquée par le fait de placer un terme dans un groupe ou sous une classe donnée, sans que rien indique de façon explicite de quelle nature est cette relation, ni les différentes interprétations qu'elle peut revêtir d'un groupe à l'autre.
En fait, cette unicité de « dimension » n'est souvent qu'apparente; sous la qualification de « hiérarchique » fréquemment donnée à cette relation unique, l'on découvre sans peine des types de rapport tout-à-fait différents - qualification, localisation, instrumentalité, etc. - qui n'ont rien de commun avec une relation d'inclusion. C'est pourquoi nous proposons de distinguer entre l'unidimensionnalité « réelle » ou « apparente » :
2. L'unidimensionnalité réelle est celle, par exemple, des systèmes taxinomiques tels qu'on les construit dans les sciences naturelles, où la relation constitutive est effectivement unique, à tous les niveaux et pour tous les groupes de la classification. A notre connaissance, les classifications en usage dans la documentation ne sont unidimensionnelles de cette manière que localement, pour certaines parties de l'organisation (ex. nomenclatures d'espèces naturelles, de corps chimiques, etc.); ailleurs, d'autres relations sont en cause, mais elles restent anonymes, et, pour cette raison, confondues avec la relation hiérarchique stricte (qui l'est aussi...).
3. Cet anonymat des relations analytiques masque en effet leur diversité, dans les classifications dont l'unidimensionnalité n'est qu'apparente, comme il arrive le plus souvent. Un effort d'analyse serait particulièrement souhaitable pour dégager les différents types de rapports implicitement pris en compte dans l'architecture de chaque organisation; c'est en effet dans le choix de ces rapports (leur nombre, leur nature, leur fonction, etc), que se manifeste l'originalité d'une classification, du point de vue structural, et, par conséquent, sa place dans une typologie des lexiques documentaires.
4. Une fois séparées les diverses catégories de relations analytiques sous-jacentes à une classification, celle-ci apparaît comme une organisation pluridimensionnelle, où chaque terme peut en droit être rattaché à plusieurs classes, en vertu de « dimensions » différentes. L'exemple actuellement le plus développé du genre est sans doute le « Semantic Code » de la W.R.U., aux États-Unis.
Que la pluridimensionnalité soit délibérée à priori (comme dans le Semantic Code), ou au contraire dégagée à posteriori (comme on le suggérait plus haut), il reste à trouver un principe de partage entre différents types de classifications pluridimensionnelles, fort nombreuses. Celui que nous proposons est fondé sur une distinction empirique entre deux catégories de rapports analytiques, selon que leur fondement (ou si l'on préfère leur fonction dans le langage documentaire) est d'ordre « sémantique » ou « syntaxique ». Définissons maintenant le sens que nous donnons à ces termes.
5. Par ordre sémantique, tout d'abord, nous entendons un ordre des termes (c'est-à-dire des objets ou des notions qu'ils désignent) qui soit le reflet d'un ensemble de définitions couramment admises, dans un groupe humain donné (par exemple, la communauté scientifique au xxe siècle, etc.). Si l'on admet que ces définitions visent à exprimer certaines caractéristiques inhérentes des entités visées, c'est-à-dire toujours valides (sinon toujours pertinentes) et quel que soit le contexte dans lequel on les considère, la classification adoptée peut être conçue comme l'image d'un ordre (provisoirement, localement) naturel, où la signification primitive des termes détermine leur place dans l'organisation générale. C'est en ce sens que nous appelons celle-ci « sémantique », par opposition à un autre type d'organisation, dite « syntaxique », que nous définirons maintenant.
6. Par organisation syntaxique, nous entendons un ordre des termes fondé non plus sur l'essence des entités qu'ils désignent - telle au moins qu'elle se manifeste à travers un corps de définitions - mais sur leur fonction particulière, dans un champ d'observation déterminé (ex. : un classement de l' « iode » parmi les « matériaux utilisés dans la fabrication de produits pharmaceutiques », etc.). 4. Les propriétés considérées pour grouper les termes sont ici contingentes, en ce sens qu'elles sont valides seulement dans un contexte restreint, celui-là même auquel la classification tente alors de s'adapter (dans l'exemple ci-dessus, « la fabrication des produits pharmaceutiques »).
Tel est le cas des organisations dites « à facettes », au moins dans le sens restreint qu'il faut, semble-t-il, donner à ce terme pour lui garder quelque spécificité par rapport à la notion générale de classe ou de catégorie sémantique. 5
7. S'il est facile de concevoir des organisations exclusivement « sémantiques » ou « syntaxiques », selon les critères précédents, il reste que la plupart des classifications en usage dans la documentation paraissent être mixtes : les points de vue « essentiels » et « fonctionnels » y sont tantôt alternés, tantôt combinés, en proportions et dans des ordres séquenciels variables. Sans doute est-ce à ce genre de classifications mixtes que s'applique l'épithète « analytico-synthétique », en usage dans certains manuels; la séparation des deux catégories de rapports est en tout cas un moyen commode d'ordonner ces classifications sur une échelle continue, depuis l'ordre strictement « sémantique » des taxinomies les plus pures, jusqu'à l'ordre exclusivement syntaxique de certains lexiques à facettes.
8. Dans ce dernier cas - classifications à facettes - tout terme peut en droit apparaître en plusieurs régions du lexique, selon les différentes classes fonctionnelles auxquelles on entend le rattacher (ex. : l'iode comme « Matière première », comme « Produit final », comme « Réactif », etc., dans un lexique relatif à l'industrie pharmaceutique). Les mêmes répétitions s'observent aussi dans les organisations » sémantiques », telles qu'on les a définies ci-dessus, et sensiblement pour les mêmes raisons. Ainsi, dans un système taxinomique quelconque, la récurrence de certains groupes de termes (par exemple, une section « Membres » répétée dans différents chapitres A, B, C... consacrés aux espèces animales, etc.) sert à marquer en fait un rapport syntaxique (membres de A, membres de B, etc.), d'un autre ordre que les rapports hiérarchiques de la taxinomie. La répétition des mêmes termes sous différentes classes d'un lexique est donc un indice que ce dernier est organisé de manière à rendre compte de relations non seulement sémantiques, mais en quelque sorte grammaticales, comme les lexiques à facettes. Il peut être utile par conséquent de distinguer entre les classifications dites univoques, où un terme occupe une place et une seule, et les classifications multivoques, avec répétitions. Tel est le sens de la dernière dicotomie proposée, au bas de la figure 2.
9. D'autres caractéristiques sont encore concevables, portant par exemple sur les termes d'indexation eux-mêmes, dans ces classifications :
- degré de généralité sémantique,
- fonction logique éventuelle (ex. : les « compound descriptors »),
- forme codée, etc.
ou sur l'aspect quantitatif du lexique considéré globalement (nombre de termes, nombre de classes, nombre moyen de niveaux d'inclusion, etc.). Il semble cependant que la recherche des propriétés structurelles définies ci-dessus soit finalement plus féconde pour une description fine des lexiques documentaires.