Une Expérience de sélection automatique de documentation
Expérience menée en 1949 par la Cie Saint-Gobain et la Cie IBM France sur un fichier réel de chimie minérale et organique (I0.000 documents), utilisant un ordonnateur IBM 705 et ayant essentiellement un but méthodologique (lexique des mots clés constitué à partir de l'analyse de chaque document). L'entretien qui complète l'étude apporte quelques précisions sur l'expérience et annonce l'application prochaine de la même méthode au Bulletin signalétique du Centre national de la recherche scientifique en même temps qu'il permet à M. Levery d'exprimer quelques vues personnelles sur la sélection automatique
En juin 1959 se terminait une expérience de sélection automatique de documentation entreprise conjointement par la Compagnie de Saint-Gobain et IBM France. Cette expérience fut présentée dans une brochure portant la date de décembre 1960 et diffusée par les deux organismes 1.
Le texte que nous présentons ci-dessous, et qui a paru également dans la Revue internationale de la documentation 2, constitue une présentation plus résumée mais contemporaine de la précédente ; elle est due à Mlles G. Picot et M.-L. Déribéré-Desgardes, ingénieurs à la Compagnie de Saint-Gobain, et à M. F. Levery, ingénieur à la Compagnie IBM France. Nous remercions la Compagnie de Saint-Gobain d'avoir bien voulu nous autoriser à publier ce texte.
Il nous a paru intéressant de publier cette étude au moment où le Centre de documentation du Centre national de la recherche scientifique (C. N. R. S.) s'apprête à faire une expérience qui aura des points communs avec celle de Saint-Gobain et qui portera sur la documentation rassemblée par le Bulletin signalétique du C. N. R. S. C'est pourquoi, après le texte de Mlles Picot et Déribéré-Desgardes et de M. Levery, on trouvera quelques compléments d'information que M. Levery a bien voulu nous apporter au cours d'un entretien qui a eu lieu à la Direction des Bibliothèques de France, le 26 février 1962.
L'évolution des sciences et des techniques qui caractérise notre époque s'est accompagnée d'un accroissement considérable de la documentation spécialisée. Les services de documentation sont de plus en plus surchargés, au moment même où leur rôle devient essentiel, et les méthodes traditionnelles deviennent souvent insuffisantes en face de cette abondante littérature.
Dans ces conditions, il devient nécessaire d'envisager des méthodes différentes susceptibles de traiter des fichiers documentaires de grande importance avec le maximum de rapidité et de précision.
Les possibilités des ordinateurs électroniques ont été souvent évoquées pour traiter les différents problèmes documentaires : analyses automatique des textes, indexage et résumé automatique des documents, enfin sélection de la documentation.
Les travaux qui ont été effectués dans ce sens par la Compagnie de Saint-Gobain et la Compagnie IBM France avaient pour but d'expérimenter une méthode de sélection automatique sur ordinateur.
Cette expérience fut réalisée sur un fichier réel de chimie minérale et organique; elle avait essentiellement un but méthodologique.
Buts de l'expérience.
Il convenait de répondre aux deux questions suivantes :
- la création d'un fichier de documentation susceptible d'être traité par une machine est-elle possible dans des conditions suffisantes de rapidité, de simplicité et de coût ?
- les résultats obtenus sont-ils valables, c'est-à-dire suffisamment précis et complets ?
On voit que ces deux questions consistent surtout à déterminer une méthode : analyse et classement d'une part, sélection d'autre part. Le choix même de la méthode, l'analyse des résultats obtenus, devaient permettre, par ailleurs, de déterminer les caractéristiques de l'ordinateur capable d'appliquer les principes choisis dans les meilleurs conditions de rapidité et de rentabilité.
Le choix d'une méthode de sélection de documentation suppose que les buts recherchés soient clairement définis. D'un point de vue théorique, ces buts sont au nombre de deux.
La méthode doit être telle que les documents superflus obtenus au cours de la sélection soient les moins nombreux possible. Il s'agit donc de minimiser une fonction « bruit » ou « parasite ».
Les réponses doivent être complètes, c'est-à-dire que le nombre des documents manquants doit être nul. Il faut donc aussi réduire au maximum une certaine fonction « silence ».
Dans la pratique, il apparaît toujours une troisième fonction à minimiser qui est la fonction « coût ». Cette dernière fonction dépend des difficultés d'utilisation de la méthode et des matériels nécessaires.
Il est facile de montrer que ces trois fonctions sont contradictoires : le « bruit » maximum (obtenu en considérant le fichier complet comme réponse à une question) correspond, en effet, au « silence » minimum et le manque total de réponse à une question correspond au « silence » maximum, mais au minimum du « bruit ».
Quant à la fonction « coût », il est évident qu'elle ne peut qu'augmenter si l'on cherche, à l'aide de moyens puissants, à minimiser simultanément les deux autres.
Dans ces conditions, tout choix de matériel ou de méthodes dépendra de l'importance relative que l'utilisateur attache à chacune des fonctions précédentes. Il sera, par exemple, décidé que les documents parasites devront représenter, au maximum, 50 % des réponses. Le problème consiste alors à définir les moyens et les méthodes qui satisfairont à cette contrainte, tout en rendant minimum la fonction « coût ». Nous ne connaissons, actuellement, aucun procédé rigoureux permettant d'aborder ce problème d'optimisation dont le modèle mathématique reste à découvrir. Nous sommes donc amenés, dans ces conditions, à multiplier les expériences, ce qui revient d'ailleurs à résoudre le problème posé par une sorte de simulation.
Choix de la méthode.
L'expérience réalisée en commun par la Compagnie de Saint-Gobain et la Compagnie IBM France consistait à représenter les documents qui formaient le fichier, de la manière la plus simple possible, sans aucune référence à un système de codification préalable. Les entrées des documents devaient être faites en utilisant, comme critères de représentations, des « mots-clés » sous une forme alphabétique naturelle.
Ces mots, choisis par un analyste, devaient exprimer les notions fondamentales contenues dans le texte. Pour ce choix, l'analyste était totalement libre, tant au point de vue du nombre que de la nature des mots-clés.
Ce système avait été choisi de préférence à une méthode de codification par classes fixes et hiérarchisées, du type traditionnel, qui risquait d'être vite dépassée, en raison du progrès rapide de la branche chimique. D'autre part, une codification aurait exigé que l'analyste exécute un véritable travail de traduction qui aurait rendu sa tâche difficile. Enfin, cela aurait interdit, pour l'avenir, une tentative d'indexage automatique à partir des mots contenus dans les textes.
La méthode expérimentée consistait donc à former, pour chaque document, une liste de mots du langage naturel qui constituait une sorte de résumé télégraphique des notions contenues. Il se définissait ainsi, au fur et à mesure de l'arrivée des documents, un langage documentaire, dénué de grammaire et de syntaxe, dont le vocabulaire était formé par l'ensemble des mots-clés utilisés par les analystes.
Les documents étant ainsi analysés, il devenait relativement simple d'effectuer une sélection de documentation : chaque demande de documentation pouvait, en effet, être considérée comme une certaine suite de mots-clés et le problème consistait à trouver automatiquement les documents dont la représentation contenait cette suite.
Il apparaît aussitôt que la valeur d'une telle méthode tient essentiellement au « lexique des mots-clés » constitué au cours des analyses. Il fallait que la machine soit capable, au cours de la sélection documentaire, d'effectuer certaines associations entre les mots-clés de ce lexique.
Ces associations étaient de deux types :
- Tous les mots-clés synonymes, trouvés au cours de l'analyse des documents différents devaient être réunis.
- Tous les mots-clés possédant entre eux certains caractères de dépendance ou de hiérarchie devaient être regroupés. Par exemple, une demande concernant les halogènes devait prendre en considération les documents traitant du chlore, du brome, du fluor, etc...
Ce travail, effectué systématiquement, conduisant à l'élaboration d'un lexique organisé sémantiquement, c'est-à-dire à un « trésor » du langage documentaire correspondant à la bibliothèque enregistrée.
Le but de l'expérience consistait donc à vérifier que :
- la représentation des documents à l'aide de mots-clés, ainsi que la constitution d'un « lexique », puis d'un « trésor » était possible.
- la sélection obtenue était valable.
Cette dernière question tendait à mesurer la fonction « bruit » et la fonction « silence » du système.
Le « bruit » pouvait provenir du manque de syntaxe dans la représentation des documents. Par exemple, une demande concernant les forets pour aciers allait sélecter les documents traitant des aciers pour forets. Le « silence » pouvait être dû à une très grande limitation du nombre de mots-clés choisis, à une insuffisance du lexique, ou à la difficulté de poser correctement les questions.
Pour réaliser cette expérience, un fichier de 10.000 documents fut constitué et traité sur un Ordinateur IBM 705. En fait, une machine aussi puissante n'était pas indispensable pour un fichier aussi réduit, mais elle présentait des avantages de rapidité, de capacité et de facilité de programmation qui permettaient de ne pas compliquer le problème de recherche de méthode par d'autres difficultés d'ordre technique.
Présentation de l'expérience.
Les documents étaient de nature diverses : articles de revue, brevet, etc... dont la plupart se présentaient sous forme de résumés, établis soit par les revues d'extraits spécialisés, soit par le service Documentation lui-même.
Bordereaux de documentation.
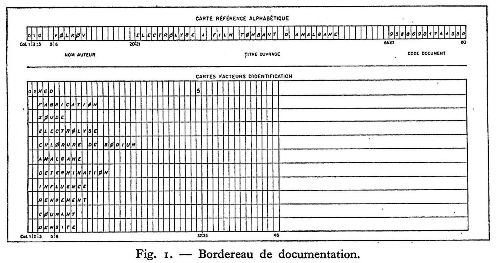
Pour chaque document, un bordereau de documentation (figure I) était établi par le documentaliste chargé de l'analyse.
Ce bordereau de documentation comportait plusieurs lignes, chacune d'elles étant la représentation exacte d'une carte perforée. Ces cartes étaient de deux types.
Sur les deux premières lignes constituant les cartes titres était consigné tout ce qui devait apparaître en clair lors de l'impression des réponses : numéro d'enregistrement du document, titre (exact ou modifié du document), nom de l'auteur ou de la société et références bibliographiques.
Sur les autres lignes constituant les cartes mots-clés étaient inscrits les mots-clés représentant l'analyse du document. Chaque bordereau comportait 22 lignes. Si ce nombre était insuffisant, on pouvait utiliser un deuxième bordereau.
Quelques règles simples fixaient l'écriture de ces mots-clés, par exemple :
- un indice permettait de distinguer les substantifs, les adjectifs et participes, les noms propres et noms commerciaux, les mots tronqués (les mots-clés étant arbitrairement limités à leurs 29 premières lettres).
Les mots étaient employés sous leur forme grammaticale la plus simple :
- Substantifs, au singulier.
- Adjectifs, au masculin singulier.
Les mots-composés, correspondant à deux ou plusieurs notions distinctes, étaient coupés, ex. :
Fibre de verre était coupé en Fibre
Verre.
Les mots composés, correspondant à une notion unique, étaient conservés,
ex. : Simili-cuir était conservé et écrit : Similicuir.
Les mots composés désignant des groupes de produits chimiques étaient coupés, ex. :
Ester vinylique était coupé en Ester
Vinylique.
Les mots composés représentant un produit chimique défini étaient conservés, ex. :
Acétate de vinyle était conservé et écrit : Acétate de vinyle.
Le temps moyen de rédaction d'un bordereau de documentation à été de sept à huit minutes.
Lexique des mots-clés et des groupes.
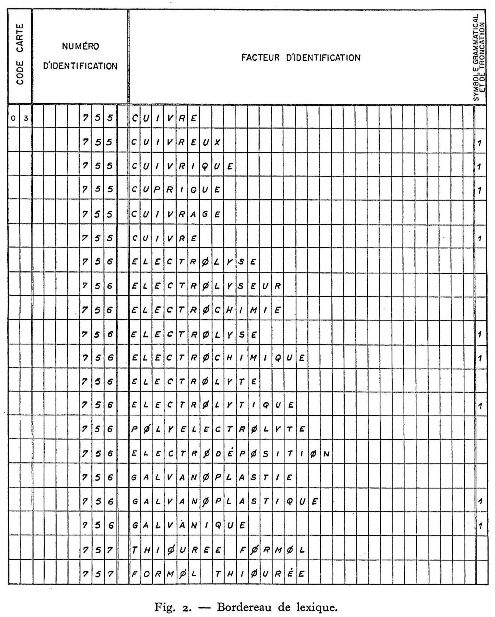
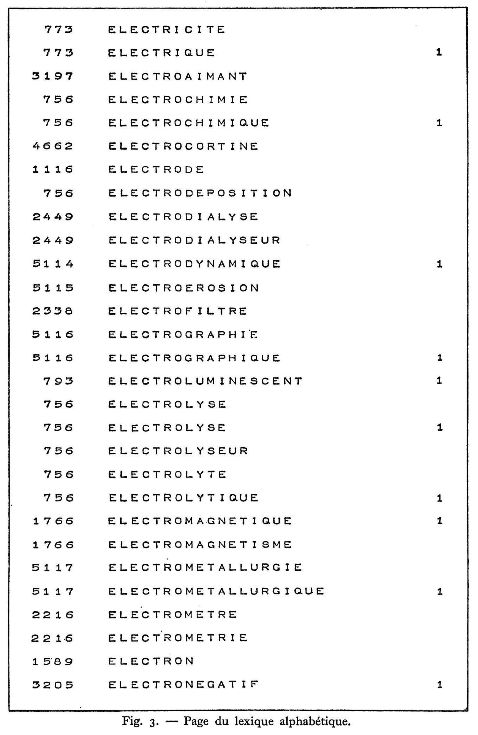
L'ensemble des mots-clés utilisés constituait un Lexique dans lequel tous les mots-clés synonymes ou de sens très voisins, ou encore de forme grammaticales différentes, étaient groupés sous un même numéro : ce numéro ne constituait nullement une codification mais permettait à la machine, au cours de la sélection, de retrouver les mots-clés de même sens. Ce lexique se présentait sous deux formes : alphabétique et numérique (figures 2 et 3).
Le lexique n'a pas été établi à priori, mais au fur et à mesure de l'apparition des mots-clés nouveaux dans les bordereaux de documentation; un premier lexique a été édité, groupant les mots-clés relevés dans les 1 200 premiers bordereaux ; cette édition a été complétée aux bordereaux 3 500, 5 500, 10 000, par simple comparaison mécanographique entre les mots-clés utilisés dans les bordereaux et les mots-clés du lexique précédent. Cette méthode permettait également de déceler certaines erreurs dans l'orthographe des mots-clés.
Le nombre des mots-clés nouveaux diminuait régulièrement à chaque mise à jour : au début de l'expérience, tous les mots-clés étaient nouveaux, au 10 000e document, on ne trouvait plus qu'un mot-clé nouveau pour quatre documents environ. Le travail de recherche des synonymes s'en trouvait allégé d'autant.
Sur les 10 000 documents analysés, la moyenne du nombre de mots-clés par document était de 8. Le lexique comportait 12 316 mots-clés groupés sous 5 957 numéros.
C'est à partir de ce lexique qu'un regroupement par classes a fait apparaître des liaisons sémantiques et hiérarchiques dont on aurait à tenir compte lors du traitement des demandes; des liaisons ont permis de constituer le Lexique de groupes.
Représentation en machine.
Les cartes perforées obtenues, après avoir été triées, étaient enregistrées sur bandes magnétiques, constituant ainsi trois fichiers :
Lexique alphabétique des mots-clés, occupant environ 180 mètres de bande.
Liste de la bibliothèque, constituée par les cartes titres triées sur le numéro de document et occupant environ 200 mètres de bande.
Fichier global, classé par numéro de mots-clés : chaque numéro de mot-clé était suivi par l'ensemble des numéros de documents dont la présentation contenait ce mot-clé. Ce fichier occupait environ 300 mètres de bande.
Sélection des documents.
La sélection était obtenue à partir des fichiers précédents. A chaque demande correspondait une suite de mots-clés. La sélection se faisait en comparant les numéros de documents associés à chacun de ces mots-clés. Un document répondant à la question devait se retrouver sous chacun des mots-clés caractéristiques de la demande. Ce système de comparaison permettait d'introduire une certaine logique dans les demandes.
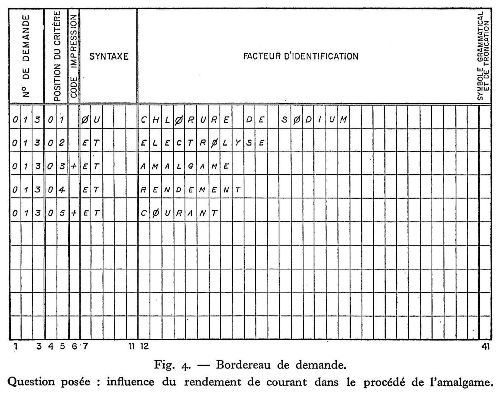
Pour chaque demande, un bordereau de demande (figure 4) était établi par le documentaliste. Pour chaque mot-clé on indiquait le numéro de la demande, la position du mot-clé dans la demande, le niveau auquel les réponses devaient être éditées, l'opération logique associée.
Trois opérations logiques étaient possibles :
et, intersection de mots-clés;
ou, réunion de mots-clés;
sauf, exclusion par intersection de mots-clés.
Les mots-clés étaient inscrits par ordre décroissant d'importance et de précision; par exemple, une demande concernant la fabrication de l'acide phtalique par oxydation du xylène en présence de catalyseurs au bromure de manganèse, était formulée à l'aide des mêmes mots-clés qu'une demande concernant les catalyseurs au bromure de manganèse, susceptibles d'être utilisés dans la fabrication de l'acide phtalique par oxydation du xylène; seule la position des mots-clés variait d'une demande à l'autre.
Rédaction de la première demande :
ou acide phtalique
et fabrication
et oxydation
et xylène (Ier niveau de précision)
et catalyseur
et bromure de manganèse (2e niveau de précision).
Rédaction de la deuxième demande :
ou bromure de manganèse
et catalyseur (Ier niveau de précision)
et acide phtalique
et fabrication
et oxydation
et xylène (2e niveau de précision).
Les différents niveaux de précision permettaient d'obtenir des réponses de plus en plus fines; au cas où il n'existait aucun document contenant tous les mots-clés de la demande, le chercheur obtenait néanmoins des réponses aux questions moins précises, contenant un nombre plus limité de mots-clés.
Au cours de l'expérience, une centaine de demandes ont été traitées; le nombre de mots-clés par demande était très voisin de 5 ; le nombre des niveaux de précision variait entre 1 et 4, la moyenne était très voisine de 2.
Traitement des demandes en machine.
Le programme utilisé au cours de l'expérience permettait de traiter 30 demandes au cours d'un seul passage en machine, la bande du fichier global n'étant déroulée qu'une fois.
Les demandes étaient introduites sous forme de cartes perforées dans l'ordinateur, où s'effectuaient automatiquement les opérations suivantes :
La lecture du lexique permettait de trouver le numéro associé à chaque mot-clé. Le fichier global était ensuite lu, mot-clé par mot-clé. Les enregistrements intéressés par les demandes étaient reproduits sur bande magnétique; le fichier réduit ainsi constitué était traité demande par demande, selon la position des mots-clés dans la demande; les opérations logiques de comparaison étaient alors effectuées sur ce fichier réduit. Les numéros de documents sélectés étaient enregistrés sur une bande magnétique; les titres correspondants étaient recherchés dans la bande liste de la bibliothèque et les réponses étaient imprimées (fig. 5).
Résultats de l'expérience.
Cette méthode a permis de retrouver 92 % des documents recherchés : la fonction « silence » du système était donc limitée à 8 %. Le nombre de documents superflus, c'est-à-dire la fonction « bruit » était de 25 %, chiffre très inférieur au pourcentage de documents qu'il fallait éliminer lorsqu'on devait explorer manuellement un fichier classique. Ces documents superflus pouvaient d'ailleurs être facilement repérés à la seule lecture du titre.
Avec la méthode expérimentée, le temps nécessaire pour traiter 75 demandes a été d'environ un jour et demi pour la rédaction des bordereaux de demande et d'une heure, environ, pour le travail en machine, chiffres qu'il est très intéressant de comparer aux deux semaines de travail nécessaires pour traiter ces mêmes demandes dans un fichier classique contenant les mêmes documents.
Les premiers résultats de cette expérience ont montré qu'un travail relativement simple de constitution de fichiers permettait d'obtenir un « bruit » et un « silence » suffisammment faibles pour envisager l'utilisation pratique de la méthode.
L'analyse des documents manquants a permis de trouver les causes du « silence » et les moyens qui pouvaient y remédier : analyse plus poussée des documents, augmentation du nombre des groupes.
Des conclusions intéressantes ont pu être dégagées quant à l'élaboration d'un langage documentaire. Par exemple, l'analyse systématique des fréquences des mots-clés conduit à la vérification de certaines lois expérimentales de distribution analogues à la loi de Zipf. Ces constatations laissent envisager des améliorations techniques du système. Ainsi l'organisation des fichiers en mémoire pourrait utiliser les caractéristiques de fréquence, ce qui permettrait d'atteindre les informations plus rapidement.
Un système utilisant des mémoires à disques magnétiques à accès direct aux enregistrements correspondant aux mot-clés, pourrait profiter d'une telle organisation, ce qui diminuerait les temps de recherche d'une manière intéressante.
En outre, l'expérience a permis de déterminer quel était le temps de réponse du système. Ce temps consiste essentiellement à préparer correctement les demandes; il est donc indépendant de l'importance du fichier. Dans ces conditions, le système expérimenté sera d'autant plus intéressant que la masse documentaire sera plus grande.
Cette expérience ne doit être considérée que comme une étape sur la voie de la mécanisation totale des problèmes documentaires; elle précise certaines données qui serviront à aborder, au cours d'expériences ultérieures, les problèmes plus ambitieux d'analyse automatique des documents.
Entretien avec M. Levery
Q. - Vous avez utilisé pour l'expérience Saint-Gobain un ordinateur IBM 705. Vous écrivez vous-même : « en fait, une machine aussi puissante n'était pas indispensable pour un fichier aussi réduit, mais elle présentait des avantages de rapidité, de capacité et de facilité de programmation qui permettent de ne pas compliquer le problème de recherche et de méthode par d'autres difficultés d'ordre technique ». Aujourd'hui utiliseriez-vous la même machine?
R. - En 1959, nous voulions faire une expérience méthodologique. Nous aurions pu utiliser tout aussi bien des procédés manuels, nous avons utilisé la machine pour accélérer l'expérience et non pas dans le but de savoir si les machines étaient bien adaptées. Nous voulions définir les caractéristiques d'un fichier documentaire à base du langage naturel, de manière à pouvoir dégager en conclusion le type de machine nécessaire. Nous nous sommes aperçus que ce qui comptait le plus dans l'expérience était l'indexage. Une machine très simple était suffisante. Il faut en réalité des machines capables de lire très vite ce qui n'est d'ailleurs pas le cas de l'IBM 705. Il faut aussi des machines qui soient capables d'imprimer très vite car il y a beaucoup de « sorties ». Le calcul interne est réduit à très peu de chose puisqu'il s'agit en fait de comparaisons sur des numéros : c'est pourquoi une machine ayant une petite capacité de calcul est suffisante. Avec des machines ayant des disques magnétiques au lieu de bandes, le temps de sélection serait accéléré, comme nous l'avons d'ailleurs dit dans nos conclusions. Ceci pour deux raisons : la première c'est que l'on pourra atteindre directement les informations de la machine sans avoir besoin de faire défiler le fichier et la deuxième raison c'est qu'on pourra traiter immédiatement les demandes sans avoir besoin de les grouper alors que c'est une nécessité avec les bandes magnétiques. Actuellement, il faudrait faire appel à des ordinateurs beaucoup plus petits, du type 140I (machines de série dont il y a 350 exemplaires environ en France) avec des bandes magnétiques et autant que possible des disques magnétiques.
Q. - Est-ce avec un 140I que vous allez entreprendre l'expérience du C. N. R. S. ?
R. - Oui, avec un 140I à bandes et disques. Un essai sera effectué avec le service de recherches bibliographiques du Centre de documentation du C. N. R. S. On compte utiliser le Bulletin signalétique en prenant, pour commencer, certains fascicules de la Ire et de la 2e parties. Le fichier sera sans doute constitué sur des bases voisines de celles de l'expérience de Saint-Gobain.
Q. - A-t-on l'intention d'établir le lexique du C. N. R. S. à partir des documents eux-mêmes?
R. - Le lexique serait constitué, au début, à partir des analyses du Bulletin signalétique.
Q. - La matière du Bulletin signalétique sera-t-elle découpée en un certain nombre de fichiers ?
R. - Au début tout au moins, des fichiers séparés seront constitués. A chacun de ces fichiers correspondra un lexique, et l'on composera ensuite ces lexiques pour voir les ambiguïtés qui en résulteraient si on les fusionnait. On veut être assuré que les mêmes mots sont pris dans le même sens, par exemple dans le vocabulaire chimique et dans le vocabulaire médical.
Q. - Compte-t-on, dans cette expérience, utiliser des vocabulaires déjà existants ?
R. - On a l'intention de laisser la liberté la plus grande à l'analyste. Tout se passe pour lui comme si chaque fois qu'il a un document entre les mains, ce document était le premier qu'il analyse. Il dégage les notions qui lui apparaissent importantes à la lecture. Ensuite les mots sont étudiés un par un, organisés et tous conservés. Il y a une différence avec l'expérience de l'Euratom, où l'analyste est libre mais où un comité décide ultérieurement si les mots doivent être conservés ou non.
Q. - Sur le tableau 2, je lis à la première ligne et à la sixième ligne : 755 Cuivre. Y a-t-il vraiment répétition ?
R. - Non. Car vous pouvez constater dans la colonne de droite, en face du deuxième « cuivre » le chiffre 1 qui indique qu'il s'agit d'un adjectif, c'est de cuivré qu'il s'agit ici. Comme nous le disons dans notre étude, un indice permet de distinguer les substantifs, les adjectifs, les participes, etc... pour lever les ambiguïtés, par exemple entre soude et soudé, usage et usagé.
Q. - Pourriez-vous expliquer pour les profanes ce qu'il faut entendre par la loi de Zipf à laquelle vous vous référez en fin d'article ?
R. - Cette loi s'exprime en lexicographie de la façon suivante : lorsqu'on étudie les fréquences de répétition de tous les termes du lexique et qu'on les classe par ordre de fréquence décroissante, on a pour le premier mot une certaine fréquence f1, pour le deuxième mot une fréquence f2 et pour le nlème mot une fréquence fn. La loi de Zipf qui est une loi expérimentale est que n × fn est sensiblement une constante. Si le premier mot apparaît 3 000 fois, le deuxième mot apparaîtra 1 500 fois, le troisième mot apparaît 1 ooo fois, etc... Lorsqu'il s'agit de sélection de documents, nous avons une loi qui n'est pas exactement la loi de Zipf. Le premier mot apparaît 3 000 fois, le deuxième mot apparaît 2 ooo fois, viennent ensuite deux mots qui apparaissent 1 ooo fois et si on faisait l'étude des fréquences on aboutirait à une courbe au lieu d'une droite. Ceci est important car ceci fixe la distribution des mots dans le vocabulaire. Lorsque nous avons classé notre fichier par mots-clés, nous constatons que nous avons des mots-clés très sélectifs parce qu'ils intéressent très peu de documents et au contraire des mots-clés très peu sélectifs parce qu'ils se retrouvent à peu près dans tous les documents. Si je prends par exemple le mot le plus fréquemment reporté, soit 3 000 fois, sur 10 000 documents, on peut dire qu'il y a un document sur 3 qui contenait ce mot. Ce mot n'est pas sélectif, c'était le mot « emploi ». Les mots qui sont apparus en tête étaient les mots comme « emploi », « préparation », « synthèse », « analyse »... Ce sont des mots coûteux du point de vue de l'interrogation parce qu'ils mettent en œuvre une masse de documentation considérable, mais ils sont très peu sélectifs. Ce sont des mots qu'il faut éviter au stade de la question. Il faut les inclure cependant dans la représentation des documents parce qu'ils peuvent servir dans des questions extrêmement générales.
Q. - Les questions peuvent être de « finesses » très diverses et on peut remarquer, d'après votre étude, que la recherche se fait à plusieurs niveaux.
R. - Cette question de finesses successives dans les réponses nous a amenés à dégager une notion nouvelle. Dans tous les systèmes de documentation quels qu'ils soient, on fait une hypothèse de base d'après laquelle le langage que l'on se propose d'utiliser, qu'il soit codifié ou qu'il s'agisse d'un élément du langage naturel, est valable aussi bien pour représenter les documents que pour exprimer les demandes. On représente les documents et les demandes par une clé unique. Cette hypothèse est fausse parce que un document est l'expression d'une connaissance précise et une recherche documentaire est, à un certain point de vue, l'expression d'une ignorance; si une personne pose une question c'est qu'elle est ignorante d'un certain sujet et n'est pas en mesure de le préciser.
Q. - Il convient cependant de faire une distinction entre des questions posées par des usagers qui connaissent très bien le problème considéré mais désirent obtenir des références bibliographiques et ceux qui connaissent plus ou moins bien, ou plus ou moins mal le sujet et qui le formulent en effet, comme vous le dites, dans un langage très différent de celui du document.
R. - On doit aboutir à dégager deux vocabulaires : vocabulaire de langage de l'informé qui est le langage documentaire proprement dit, et le langage du non-informé qui est issu du premier et qui est utilisé pour les demandes. Ces deux langages sont parfaitement séparés. Il y a une véritable traduction à opérer lorsqu'une personne pose une question pour l'exprimer dans le langage documentaire.
Q. - C'est bien ce que vous faites puisque d'après les questions posées par les usagers vous établissez le bordereau de demande. Il y a pour ainsi dire une traduction de la demande ?
R. - Très exactement. Il y a un travail intellectuel qui consiste à remplacer les termes vagues qu'emploient généralement les demandeurs par des termes précis qui peuvent se trouver dans le document. Ceci suppose des connaissances que la personne chargée de l'établissement du bordereau n'a pas toujours. Aussi étudions-nous actuellement si cette traduction du langage de demandeur dans le langage du document ne pourrait pas être faite automatiquement et on aboutit à cette notion qui a été dégagée par des américains comme Mr. Stiles, du Département de la défense, qui définit ce qu'il appelle un facteur d'association entre les notions. On pourrait représenter cela comme « l'environnement » d'une notion. Si on a une notion qui a une certaine forme dans le langage des documents et une forme différente dans le langage des non-informés, ces deux formes différentes de la même notion font partie du même environnement et si l'on peut dégager automatiquement l'environnement d'une notion, on pourra faire le passage de l'un à l'autre. Pour dégager l'environnement d'une notion, Stiles se sert du fichier documentaire lui-même, c'est-à-dire qu'il essaye de trouver dans les documents un certain coefficient de corrélation entre les différentes notions qui apparaissent dans le fichier. Il le définit d'une manière mathématique d'ailleurs. On arrive à des résultats très intéressants. C'est par ce type de raisonnement que l'on arrivera à trouver que dureté et usure font partie du même environnement, alors qu'ils ne sont pas synonymes et qu'ils ne sont pas hiérarchiquement liés. Une question qui concernerait la dureté des aciers doit faire penser au mot usure. Un demandeur sera intéressé par l'usure des aciers, il ne pensera pas à un document qui traitera de la variation de la dureté de l'acier. Le mot dureté fait partie du langage de l'informé. Le mot usure est une notion beaucoup plus diffuse. Ce terme d'ailleurs sera employé par la plupart des demandeurs, sauf par des demandeurs très informés qui, par exemple, voudront savoir ce qui a été publié dans les brevets.
Q. - Le problème des brevets n'est-il pas très différent ?
R. - La personne qui pose une question concernant les brevets est généralement plus informée que le brevet lui-même qui est volontairement rédigé en termes quelquefois vagues. Pour revenir à mon exemple de dureté et d'usure, ce qu'il faut c'est que lorsqu'on posera la question : usure de l'acier, la machine aille d'elle-même rechercher la notion dureté.
Q. - Les demandes que vous avez utilisées dans votre expérience de Saint-Gobain étaient-elles des demandes posées par des usagers ou ont-elles été inventées pour les besoins de la cause ? Il me paraît très important pour une expérience d'utiliser au maximum des demandes réelles.
R. - Nous avons utilisé en partie des demandes inventées et en partie des demandes réelles. Quand je dis qu'il y a eu des demandes inventées, il s'agit en fait de demandes d'un caractère particulier. On voulait s'assurer que la machine retrouverait bien les documents qu'il fallait, de sorte que nous avons demandé à des personnes étrangères au service de prendre quelques documents au hasard dans la pile des documents qui avaient été indexés et de poser leurs questions à propos de ces documents, mais sans savoir comment ils avaient été indexés. C'était une opération de vérification et de contrôle.
Q. - Ce qui m'a frappé dans votre expérience c'est qu'elle est, à certains égards, un combiné du système de fiches à caractéristiques, de cartes perforées et d'ordinateurs. Votre système est fondé sur le groupement des documents autour de chaque mot-clé. Votre méthode s'apparente à celle que l'on emploie dans un fichier traditionnel où l'on recherche les mots-clés pour ensuite trouver la référence au document. Vous interrogez le fichier global pour chaque mot-clé et vous constituez un fichier réduit, comme si vous extrayiez d'un fichier les fiches correspondant à chacun des mots-clés retenus.
Je voudrais poser une autre question : comment envisagez-vous la mise à jour de vos différents fichiers enregistrés sur bandes magnétiques?
R. - On prévoit de faire une mise à jour de ces fichiers aussi souvent qu'il serait nécessaire. Au C. N. R. S., cela pourrait être fait toutes les semaines ou tous les quinze jours. Lorsqu'une nouvelle masse de documents a été traitée, cette masse sera caractérisée éventuellement par de nouveaux mots du lexique qui vont nous donner un nouveau lexique alphabétique réduit à ces nouveaux mots. Elle va nous donner également un fichier global exactement de la même nature que le fichier global de la documentation antérieurement traitée où tous les documents sont indexés par des mots-clés, mais on ne retiendra, bien entendu, que les mots-clés correspondant aux nouveaux documents. Nous aurons donc le lexique ancien sur une bande magnétique et le lexique nouveau sur bande magnétique. Tous les huit jours on créera une troisième bande magnétique qui sera le lexique complet. Cette fusion s'opèrera entre trente et quarante secondes. Dans le cas du fichier global l'établissement du fichier complet sera plus long car il faut lire tout le fichier global.
Q. - Le fichier global que vous avez utilisé pour Saint-Gobain ne comprenait que 10 000 documents, mais si demain on envisage de faire un fichier global pour l'ensemble du Bulletin signalétique depuis sa création, referait-on un fichier global mis à jour tous les huit jours. Ne serait-ce pas trop long ?
R. - Du point de vue de la technique de la machine, aucune difficulté. Mais en réalité on profitera des demandes puisque pour interroger le fichier global on est obligé de toute façon de le faire défiler entièrement. En même temps qu'on lira le fichier global pour constituer un fichier réduit on opérera sa mise à jour en constituant une troisième bande.
Q. - Pouvez-vous nous donner quelques précisions sur les temps de lecture ?
R. - Je vous ai dit tout à l'heure qu'il fallait des machines rapides. Une bande complète de 700 mètres (plus dense que celles utilisées dans l'expérience de 1959) se lit à peu près en quatre minutes. Il est d'ailleurs très difficile d'évaluer les temps. La lecture d'un fichier global comportant plusieurs centaines de milliers de documents se chiffre en minutes plutôt qu'en secondes.
Q. - On peut en outre poser plusieurs questions simultanément, 30 je crois en même temps, dans l'expérience de Saint-Gobain.
R. - Ce n'est pas tellement le temps de lecture du fichier global qui est important, c'est le temps de lecture du fichier-bibliothèque, c'est-à-dire qu'ayant les numéros des documents il faut retrouver la référence de chaque document. Il faut compter un tiers du temps pour repérer les numéros des documents correspondant à une question et deux tiers pour rechercher les références des documents. Plus le nombre des éléments de la référence associée à chaque numéro de document est grand, plus le temps augmente.
Supposons un document représenté par 8 critères, et supposons un fichier ne dépassant pas un million de documents, nous allons avoir 6 positions nécessaires pour représenter un numéro de document (999 999). Ces 6 positions vont se retrouver 8 fois dans notre fichier parce qu'il y a 8 critères. Nous allons donc avoir 48 positions dans le fichier total qui vont intéresser ce document. D'autre part, dans le fichier-bibliothèque, à ce numéro de document de 6 positions va être associée la référence et celle-ci nécessitera beaucoup plus de 48 positions. Il faudra donc beaucoup plus de positions sur la bande magnétique pour caractériser un document que pour retrouver le numéro correspondant. S'il faut 100 positions pour le titre d'un document (nom d'auteur, titre, etc...) et 48 pour caractériser ce document au stade de la recherche, on pourra dire qu'il faudra deux fois plus de temps pour la lecture du fichier-bibliothèque. Au C. N. R. S. nous pensons que 120 positions environ seront utilisées pour la référence d'un article (ce qui représente deux cartes, mais le nombre des cartes n'est pas limité).
En principe il faut éviter de trop développer la référence car cela coûte cher. Il n'y a pas non plus de limitation dans le nombre de mots-clés par document : si on met 20 mots-clés par document, cela coûtera cher, mais on le fera quand même s'il le faut.
Q. - Si, sous réserve de quelques modifications, la méthode suivie à Saint-Gobain était étendue au C. N. R. S. c'est, pensons-nous, parce que cette voie est la meilleure ?
R. - Oui, mais je n'ignore pas qu'il y a actuellement beaucoup d'études apportant des éléments nouveaux. Ce qu'il faut avant tout c'est ne pas vouloir écraser les mouches avec un marteau-pilon.
Je suis de très près les travaux de M. Gardin avec Syntol (Recherche d'un langage documentaire comportant la traduction de toutes les relations syntactiques qui existent entre les termes), travaux absolument remarquables. Je pense que cela donnera des résultats très intéressants dans quelque temps, et même assez rapidement, mais les degrés de complexité auxquels atteint M. Gardin, ne s'imposent pas pour tous les types de documentation. Dans l'esprit de M. Gardin, il s'agit de définir un langage documentaire valable pour n'importe quoi. Mais cela est une complication inutile pour 9/10e des fichiers de documentation.
Pour caractériser un document, nous avons par exemple les mots A, B, C; nous savons que l'ensemble de ces mots ne peut caractériser un document sans risque d'erreur. Dans le cas de la chimie nous avons par exemple 25 % de documents superflus parce que nous avons tous les cas où la liaison entre les termes peut être bouleversée. Nous savons que les termes outil et acier peuvent donner outil pour acier et réciproquement et qu'un des documents pourra être repéré à tort par une des demandes outil pour acier. Le problème est de déterminer le degré de redondance d'un langage, c'est-à-dire dans quelle mesure les liaisons qui existent entre les mots sont imposées dans le langage ou ne le sont pas. Nous savons que cela varie considérablement d'un fichier documentaire à un autre. Dans le cas des sciences exactes, ce type de redondance est assez élevé, 25 % de documents superflus n'est donc pas très grave, d'autant que les documents superflus le sont totalement et que cela se décèle immédiatement à la lecture du titre. Nous avons la possibilité d'utiliser quelque chose de simple qui donne des résultats suffisants et on ne doit jamais négliger l'aspect économique.
Si je prends maintenant un cas dans le domaine des science sociales, nous avons les mots : influence, bourgeoisie, XVIIIe siècle, protestantisme, je peux avoir : l'influence de la bourgeoisie protestante sur le XVIIIe siècle - l'influence du XVIIIe siècle sur la bourgeoisie protestante - l'influence de la bourgeoisie sur le XVIIIe siècle protestant, ou l'influence du protestantisme sur le XVIIIe siècle bourgeois. Dans les sciences de l'homme, la représentation des documents à l'aide des seuls mots-clés est très nettement insuffisante, il faut donc améliorer le système et plus spécialement en ce qui concerne les sciences de l'homme. L'idée de M. Gardin est de trouver un système qui doit prendre en charge toutes les notions ou toutes les relations possibles entre les notions dans un document quelconque, mais cela complique considérablement l'entrée. Ce que fait M. Gardin est plus ambitieux que ce que nous allons faire et plus intéressant mais pour certains types de documentation. Ce que je veux voir c'est quels sont les fichiers qui s'accommodent de systèmes simples, quelles sont les imperfections de ces systèmes simples pour chaque type de fichiers, quelles sont les améliorations à apporter à chaque type de fichier pour éviter ces inconvénients. Je ne définis pas un langage documentaire mais des systèmes documentaires adaptés. Je suis beaucoup plus expérimental.
Q. - Il faut certainement poursuivre parallèlement les expériences sur les machines et les études linguistiques.
R. - Ce que je ne sais pas, et seul l'avenir le dira, c'est si le meilleur système documentaire ne se dégagera pas d'un certain nombre d'expériences. M. Gardin étudie le langage en soi et voit comment l'information est supportée par les mots; il se sert de cette étude pour créer un système documentaire. Mais c'est à long terme. En ce qui me concerne, je considère que j'ai des fichiers à créer avec des systèmes simples, je les améliore, je fais un inventaire des méthodes nécessaires pour chaque type de fichier et je vois si de cet inventaire il se dégage une idée générale. Peut-être arriverai-je aux mêmes résultats que lui.
Q. - Des expériences semblables à celle de Saint-Gobain ont-elles été faites aux États-Unis ?
R. - Il y en a une qui a été faite à la « General Electric » sur un nombre supérieur de documents, mais en utilisant un fichier de mots-clés fixés a priori, il y a aussi une autre expérience faite à l'Euratom (ISPRA) également avec un fichier a priori. L'expérience de Saint-Gobain, à ma connaissance, est la seule expérience faite avec un vocabulaire issu des documents eux-mêmes.
Une expérience très intéressante est menée à Pittsburg sur une indexation de textes juridiques où le but recherché est de supprimer complètement l'analyste. Ce sont les mots qui sont contenus dans le texte - la totalité des mots d'ailleurs - qui servent à indexer le document. Tous les mots du texte sont considérés à égalité comme étant des mots-clés.
Q. - Ne s'agit-il pas là d'un cas particulier, car il paraît impossible d'utiliser comme mots-clés tous les mots de tous les articles signalés dans le Bulletin du C. N. R. S. par exemple ?
R. - Mais l'intérêt de cette expérience de Pittsburg est de permettre de voir quels sont les mots qui sont intéressants et importants, quels sont ceux qui sont demandés ?
Q. - Que pourriez-vous me dire à propos des machines à lire ?
R. - La première difficulté vient de la lecture du texte proprement dit. Il faut que la machine soit capable de reconnaître les caractères les uns des autres, par exemple un A d'un E. Il existe à l'état de prototypes des machines capables de reconnaître des caractères alphabétiques dactylographiés avec une souplesse qui reste assez grande; une forme de caractère est imposée mais avec une certaine marge. On peut envisager d'ici quatre ou cinq ans, sans être trop optimiste, que la lecture optique de caractères dactylographiés ou imprimés sera résolue. Déjà maintenant on sait lire des chiffres. Tous les chiffres peuvent être directement lisibles. Il faudrait obtenir que les éditeurs s'astreignent à avoir un type de caractères imposés ou acceptent d'avoir comme sous-produit de leur dactylographie une bande perforée. Toutes les machines à écrire peuvent recevoir un perforateur de bande. A partir du moment où ce qui est reproduit dans un texte se trouve également reproduit sur bande perforée (type code 5 canaux-code Telex) le problème de la lecture automatique serait résolu. Pas besoin de lire le caractère imprimé si on peut lire le caractère perforé.
Q. - Cela supposerait que tout article de périodique soit reproduit en même temps sous forme de bande perforée.
R. - A un moment ou à un autre, tout article a fait l'objet d'une dactylographie et par conséquent pourrait faire l'objet d'une bande perforée. Dans tous les centres où l'on fait des essais de lecture automatique des textes, les chefs de centres ont obtenu que leurs machines à écrire soit connectées avec des perforateurs de bandes pour avoir des éléments d'étude. Ensuite il faut que la machine dégage les idées fondamentales. Il faut procéder à des recherches de fréquence qui donnent des résultats en anglais mais pas en français. S'il existe dans un texte une idée fondamentale, l'auteur doit être amené à revenir sur cette idée. Il va insister et en insistant il va en principe répéter les mêmes mots et l'emplacement où les mots sont répétés coïncide avec l'emplacement du texte où est exprimée l'idée fondamentale, ce qui va servir d'une part à déterminer les parties du texte qui serviront au résumé automatique, et d'autre part à dégager les mots répétés qui sont censés être l'idée fondamentale. Cela va très bien en anglais mais pas en français parce que l'auteur français évite les redites. Si l'on voulait arriver je crois au même stade où en sont les Anglais et les Américains, il faudrait incorporer à la machine un dictionnaire des synonymes, et on retombe dans le problème qui nous préoccupe aujourd'hui. Il faut que la machine soit capable de regrouper non pas au niveau du vocabulaire mais au niveau de la notion. En outre, les Anglais ont l'avantage d'avoir une langue morphologique pauvre. En anglais, le mot n'est pas déformé ou peu déformé et souvent répété. En français, il n'est jamais répété mais est toujours déformé. La méthode, il est vrai, peut être testée sur une autre langue que le français. On fait actuellement des progrès mais on ne s'occupe pas du français.
Q. - Arrive-t-on avec ces machines à lire à dégager, avec un pourcentage valable, les notions importantes ?
R. - J'ai fait l'expérience avec le fichier Saint-Gobain. J'ai pris un certain nombre de documents. J'ai fait cette analyse de fréquence, j'ai rapproché cette fréquence au stade de la notion par l'intermédiaire du dictionnaire des synonymes, j'ai comparé la liste des mots que j'obtenais avec la liste des mots qu'avait choisis l'analyste. J'obtenais sur une moyenne de 8 mots choisis par l'analyste 5 communs avec la méthode purement mécanique. Que dire des trois autres : étaient-ils mieux choisis par la méthode mécanique ou par l'analyste, je n'en sais rien a priori. Pour vraiment le savoir il faudrait avoir les mêmes documents dans deux fichiers parallèles, l'un indexé à la main, l'autre indexé par la machine, poser les mêmes questions et comparer les résultats. Je ne connais personne qui ait fait une telle expérience, cela demanderait des moyens financiers considérables, cela supposerait que tous les documents utilisés auraient été pré-perforés.