Présentation du système d'indexation « PRECIS »
D'après l'expérience faite par le Département des arts du spectacle de la Bibliothèque nationale
Anne-Marie Ferrier
Le système PRECIS (Preserved Context Indexing System), conçu et utilisé depuis 1969 par la British National Bibliography a fait l'objet d'une expérience, pratiquée par le Département des Arts du spectacle de la Bibliothèque Nationale. Cette expérience offre l'occasion d'une analyse détaillée du système et de l'importance de ses deux composantes : partie sémantique concrétisée par le thésaurus, partie syntaxique concrétisée par l'utilisation des opérateurs de rôle.
PRECIS (Preserved Context Indexing System), elaborated and used at the British National Bibliography since 1969 has been experimented in the Département des Arts du Spectacle at the Bibliothèque Nationale. There is a detailed analysis of the system and of its two main parts : semantic with a thesaurus, syntatic with use of role operators.
Entre juillet et novembre 1976, le Département des Arts du spectacle a tenté une expérience d'indexation matières automatisée utilisant le logiciel documentaire PRECIS II de la « British Library ». Cette expérience limitée à l'indexation de 100 ouvrages a abouti à l'élaboration d'un catalogue expérimental. Il s'agit d'un catalogue à deux niveaux, composé d'un index matières renvoyant à une deuxième partie constituée des notices auteurs.
Notons tout de suite que cette présentation n'est qu'une des possibilités offertes par PRECIS en matière d'édition. Elle nous a été imposée par les conditions de travail : l'index matières a été produit à Londres, grâce à l'obligeance du « Subject Systems Office » 2 », qui s'est chargé du traitement des données envoyées de France; il n'a pas été possible d'entrer en machine les notices auteurs qui ont été dactylographiées.
PRECIS (Preserved Context Indexing System) est un système conçu et utilisé depuis 1969 par la British National Bibliography qui, lorsqu'elle a adopté le format MARC, a souhaité automatiser intégralement sa production y compris l'index matières.
Le système dans son ensemble comporte deux aspects :
- une méthode d'analyse du sujet qui aboutit à l'écriture d'un chaînage de concepts.
- un ensemble de programmes qui permettent à l'ordinateur de manipuler le chaînage pour produire les entrées de l'index. C'est essentiellement le premier de ces aspects que nous présenterons ici. En effet c'est la méthode d'analyse qui a déterminé le choix du système. Elle nous a paru se démarquer très nettement des systèmes déjà existants et aboutir à une amélioration de la qualité de l'indexation.
Bien qu'il ne soit pas dans mon propos de faire l'historique de PRECIS, il apparaît cependant que certains éléments relatifs à son élaboration contribuent à éclairer la conception générale du système.
Il est par exemple évident que les recherches menées par le « Classification Research Group » pendant de nombreuses années, ont contribué de façon importante au développement de PRECIS. Ce groupe qui se situe à l'origine dans la lignée de Ranganathan, a envisagé la classification comme une opération comportant deux étapes : l'analyse du sujet pour en découvrir les différents éléments ou facettes, puis l'organisation de ces facettes selon un ordre constant.
Cette même démarche se retrouve au cours de l'indexation avec PRECIS. Elle amène à établir un double contrôle :
- contrôle du vocabulaire de manière que le même concept soit toujours exprimé par le même terme ou la même expression.
- contrôle de l'ordre d'énumération des termes choisis pour aboutir à l'expression d'un sujet précis.
Nous voyons apparaître ici les deux composantes du système : la partie sémantique qui sera concrétisée par le thésaurus, et la partie syntaxique qui sera concrétisée par l'utilisation des opérateurs de rôle.
Le processus de l'analyse : l'emploi des opérateurs de rôle.
Dans un premier temps, l'indexeur formule un énoncé verbal rendant compte du sujet de l'ouvrage. Puis chaque concept constituant le sujet est affecté d'un opérateur qui indique le rôle logique de ce concept par rapport aux autres.
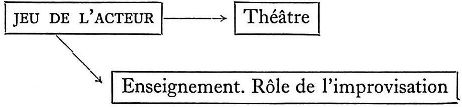
Un ouvrage sur L'Improvisation dans l'enseignement du jeu de l'acteur donnera lieu à l'analyse suivante. On cherchera d'abord s'il y a un concept représentant une action, car de même que dans le langage naturel le verbe est le noyau autour duquel s'articule la phrase, l'action (quand il y en a une) est le noyau autour duquel s'articule le chaînage PRECIS. « Enseignement » est une action et sera codé (2). L'objet de cette action est le «jeu de l'acteur » qui sera codé (I). « Improvisation » sera codé (3), comme agent de l'action. Pourtant, dans le cas présent, bien que le concept « improvisation » ait une part de responsabilité dans l'accomplissement de l'action, on ne peut pas le considérer comme directement responsable de cette action. C'est pour exprimer cette nuance qu'on introduit dans le chaînage le mot « rôle ». On obtiendra donc le chaînage suivant :
(I) jeu de l'acteur
(2) enseignement$w du
(s) rôle$v de l'$v dans l'
(3) improvisation
(Nous reviendrons plus tard sur les codes$v et$w.)
On peut accroître la complexité de l'analyse et considérer par exemple que l'expression « jeu de l'acteur » fait partie de l'entité « acteur », on codera alors « acteur » (I) et on traitera « jeu de l'acteur » en élément dépendant du concept précédent, introduit par l'opérateur (p). Il est par ailleurs nécessaire d'introduire la notion de « théâtre » puisque c'est à ce seul art du spectacle que se réfère l'ouvrage. Le terme « acteur » sera donc considéré à son tour, comme un élément dépendant du concept précédent « théâtre ».
On obtiendra pour finir le chaînage suivant :
(I) théâtre
(p) acteur
(p) jeu de l'acteur
(2) enseignement$w du
(s) rôle$v de l' $w dans l'
(3) improvisation
Les termes dans le chaînage sont disposés selon la valeur croissante des opérateurs numériques. Cette disposition n'est pas faite pour privilégier un terme quelconque et ne correspond en aucun cas à l'importance relative des termes. Elle est le résultat de conventions d'analyse. Il appartient à l'indexeur de choisir, en utilisant un code particulier lors de l'entrée des données, quels termes devront apparaître en vedette dans l'index. Chaque terme choisi aura ainsi le rôle principal dans l'entrée dont il est la vedette.
Le chaînage, assorti de certains codes annexes, est entré en machine. Puis l'ordinateur génère les entrées de l'index selon l'un des trois formats du système. (Le choix du format dépend, pour chaque entrée, de l'opérateur du terme mis en vedette.)
On obtiendra donc les entrées suivantes :
THÉATRE
Acteur. Jeu de l'acteur. Enseignement. Rôle de l'improvisation. ACTEUR. Théâtre
Jeu de l'acteur. Enseignement. Rôle de l'improvisation.
JEU DE L'ACTEUR. Théâtre.
Enseignement. Rôle de l'improvisation.
IMPROVISATION. Théâtre
Rôle dans l'enseignement du jeu de l'acteur.
Chaque entrée se présente sur deux lignes, et comprend le plus souvent trois parties (cf. tableau 1)
L'attention de l'usager est ainsi guidée dans deux sens à partir du terme mis en vedette. « Théâtre » indique le contexte plus large dans lequel se situe le « jeu de l'acteur », alors que le groupe « Enseignement. Rôle de l'improvisation » indique un aspect plus spécifique.
Les opérateurs ne figurent pas dans les entrées. Lorsque la relation entre deux termes est implicite, il y a simplement juxtaposition des termes. Mais dès qu'il peut y avoir ambiguïté, la relation est exprimée en clair par l'adjonction de locutions prépositives introduites par les codes$v et$w.
Nous avons volontairement choisi un exemple complexe, pour montrer avec un seul chaînage, plusieurs des caractéristiques du système. La majorité des chaînages est en fait plus simple et la technique d'analyse syntaxique s'acquiert facilement en une dizaine de jours, ce qui n'est pas grand chose comparé aux avantages du système.
En effet, le travail de l'indexeur se borne à l'écriture du chaînage. C'est l'ordinateur qui « écrit » les entrées. Chaque entrée cite le sujet dans son entier sans qu'il y ait jamais perte même partielle d'information. La procédure d'analyse permet de rendre compte de façon précise du contenu d'un ouvrage. Enfin les entrées sont suffisamment proches du langage naturel pour permettre à n'importe quel utilisateur de les interpréter correctement.
La construction du thésaurus
Nous abordons maintenant l'autre composante du système, l'aspect sémantique. S'il est vrai que l'originalité du système PRECIS réside dans la codification et l'expression des relations syntaxiques entre les termes d'un même sujet, la construction du thésaurus n'en est pas pour autant négligée.
Des différentes méthodes utilisées à cet effet, PRECIS a choisi la méthode analytique. C'est-à-dire qu'il n'y a pas, préalablement à l'utilisation des règles syntaxiques, à disposer d'un thésaurus qui serait établi à priori. C'est au cours de l'indexation, et au fur et à mesure qu'il rencontre des termes nouveaux que l'indexeur les introduit dans le thésaurus. Cette méthode a plusieurs avantages :
- basée sur la documentation existante, elle garantit que les termes choisis sont significatifs de l'étude et de la pratique du sujet.
- lorsqu'on indexe dans un domaine spécialisé, elle résout le problème des domaines marginaux en évitant de délimiter trop rigidement le champ du thésaurus, puisque les mots apparaîtront au fur et à mesure des besoins. - enfin, l'élaboration d'un thésaurus n'est jamais terminée, à des notions nouvelles correspond une terminologie nouvelle. La méthode analytique permet l'entrée immédiate de ces notions.
Une telle méthode n'exclut pas une grande rigueur dans l'établissement des relations sémantiques entre les termes du thésaurus. Conformément à la norme ISO 2788, PRECIS reconnaît trois sortes de relations (relations d'équivalence, générique ou associative) concrétisées dans l'index matières par des renvois Voir et Voir aussi.
Une fois le chaînage écrit, chaque terme ne figurant pas encore dans le thésaurus est considéré en dehors de son contexte. On cherche alors les synonymes, les termes génériques et les termes associés.
A partir du terme « acteur », par exemple, on déterminera que « comédien » est un terme synonyme, puisque les acteurs appartiennent à la catégorie des « artistes ». On aura ainsi constitué un premier niveau de relations :
artiste
acteur - comédien
qui donneront lieu aux renvois suivants :
Comédien Voir : Acteur
Artiste Voir aussi : Acteur
Dans PRECIS, le thésaurus est géré par un processus indépendant de la syntaxe. Chaque terme admis est affecté d'un numéro identifiant son adresse dans le fichier en machine. A chaque type de relation sémantique (relation d'équivalence, générique ou associative) est associé un code qui lui est propre. Le réseau des relations est établi une fois pour toutes, lorsqu'un terme apparaît. Les renvois seront reproduits automatiquement dans l'index chaque fois que le terme figurera de nouveau dans un chaînage.
A l'issue de cette présentation trop rapide du système, nous insisterons sur le fait que comme dans tout système automatisé, la qualité des résultats dépend de la qualité de l'analyse préalable. Cette phase reste l'apanage du cerveau humain. Avec ses règles d'analyse logique et ses principes d'organisation sémantique PRECIS fournit un modèle très sophistiqué permettant une amélioration du niveau de l'indexation.
Le système PRECIS a fait l'objet de nombreuses publications en langue anglaise. Nous nous bornerons ici à signaler l'ouvrage de base indispensable à quiconque veut étudier sérieusement le système :
AUSTIN (Derek). - PRECIS a manual of concept analysis and subject indexing. - Londres : The Council of the British National Bibliography, 1974. - 551 p.; 29,5 cm.