Études de CAS
Le traitement de l'IST par les indicateurs scientométriques
Henri Dou
Parina Hassanaly
Albert Latela
Maurice Milon
La croissance exponentielle de l'information scientifique et technique rend sa maîtrise de plus en plus difficile. Pour en faciliter l'accès, les auteurs proposent des techniques d'analyse de données, ici celles des Chemical abstracts, par des programmes informatiques associés à des représentations graphiques.
Scientific and technical information has become uneasy to handle because of its exponential increase. For a better access, the authors offer new techniques of data analysis (Chemical abstracts) based on processing programs with graphic output.
Les scientifiques se trouvent actuellement confrontés à une masse croissante d'informations. Durant la dernière décennie, les bases et banques de données ont permis de faire face à cette inflation. Elles ne suffisent plus aujourd'hui au traitement correct des informations. De nouvelles techniques, faisant appel au traitement informatisé local, à l'analyse factorielle, au traitement des graphes, etc., vont permettre de mieux analyser la littérature pour prendre des décisions adaptées au contexte de la recherche effectuée. Cet article a pour but de présenter quelques résultats représentatifs obtenus par des méthodes originales développées dans notre laboratoire 1.
Nous prendrons comme exemple des informations issues de la chimie. Mais il faut garder à l'esprit que toute banque de données structurée en champs homogènes peut faire l'objet du même traitement (1). La démarche de départ est la suivante. Si on peut extraire de la littérature un ensemble de références à partir d'un certain nombre de descripteurs, cet ensemble est souvent volontairement restreint au sujet décrit par les mots clés utilisés, mais il est aussi limité par la capacité de lecture du demandeur d'information. Ainsi les banques de données et les puissants progiciels d'interrogation sont actuellement utilisés bien en deçà de leurs capacités, le but final étant souvent de réduire les réponses au strict nécessaire, ce qui élimine toute capacité d'innovation et de découverte en « feuilletant » (browsing).
En effet, le volume de la littérature croît, le nombre d'années antérieures accessibles augmente (environ 20 années actuellement), ce qui conduit pour des recherches même fines, à des ensembles de références importants. On aboutit alors à un paradoxe, puisque les outils modernes ne sont pas utilisés pour augmenter la capacité de réflexion et d'innovation, mais pour restreindre à des limites acceptables un sujet de réflexion. C'est pour cela que nous nous sommes engagés, au Centre de recherche rétrospective, dans une réflexion et une conception de produits qui permettront d'apporter un certain nombre de solutions à la situation antérieure.
Le but poursuivi est d'effectuer une recherche large, même très large, puis d'analyser celle-ci avec des programmes de traitement de l'information assez proches des systèmes d'intelligence artificielle. On peut ainsi, sans connaître les descripteurs utilisés, ni les mots, ni les codes employés, dégager les idées et les concepts les plus fréquents, ainsi que les groupes de références qui les contiennent. On aboutit donc tout de même à des ensembles analysables par un individu, mais sans restriction de recherche au départ.
Les méthodes scientométriques utilisent le concept suivant : élargir la recherche au départ, même au-delà des capacités de lecture du demandeur, puis analyser les références en « local », par des programmes de travail spécifiques, afin d'obtenir les informations sous-jacentes, les centres d'intérêt, et les relations entre les travaux plus ou moins liés par des données ou des idées communes.
Les Chemical abstracts (2) indexent la littérature chimique, en utilisant plus de 12 000 périodiques. Plus de 450 000 articles sont résumés chaque année. Cet outil bibliographique est diffusé soit sous forme de produit papier, soit sous forme d'une banque de données accessible en ligne. Le format des références est généralement constitué de différents champs qui se prêtent bien à une exploitation informatique. Ils sont caractérisés par des intitulés de champ et peuvent être imprimés ou stockés sur disque soit en format standard, soit selon l'ordre spécifié par l'utilisateur.
Le premier exemple des différentes méthodes de traitement des informations concerne le champ des codes de catégorie (CATEGORY CODES), qui, dans le cas présent, contient la ou les sections des Chemical abstracts auxquelles le sujet se rapporte. La chimie est ainsi divisée en 80 sections. Dans une bibliographie d'une centaine de références (ce qui est assez commun en recherche) , il n'est plus possible d'effectuer une analyse manuelle de l'ensemble des thèmes mis en relation par l'ensemble constitué au départ.
Dans le champ des termes indexés (INDEX TERMS), il existe des numéros de registre (Registry numbers), qui caractérisent de façon univoque, mais sans signification chimique particulière, les composés utilisés (3). Ces numéros de registre sont de l'ordre de 5 à 10 et plus par référence, selon les domaines étudiés.
Une bibliographie de 100 références va conduire à la génération d'environ 500 à 1 000 numéros de registre. Leur analyse n'est plus du ressort de la simple lecture et ne peut pas être réalisée par les progiciels accessibles à travers les serveurs de banques de données. Ce sont des lacunes de cette sorte que comblent les recherches actuelles en science de l'information, principalement lorsqu'elles sont appliquées aux sciences exactes.
La même remarque peut être faite en ce qui concerne les mots contenus dans les termes supplémentaires (SUPPLEMENTARY TERMS) en langage libre. Dans ce cas, le simple classement de ces descripteurs est sans objet (ils sont trop nombreux), et il faut recourir à la méthode des co-occurrences des paires de mots (4, 5) pour aboutir à une information supplémentaire par rapport aux données de base de la recherche : une paire de mots a un contenu en information bien supérieur à la somme du contenu informatif des deux mots isolés.
Le traitement des sections
Chaque référence est caractérisée par une section principale, et, dans certains cas, par une (ou des) section secondaire si la publication concerne un autre domaine de recherche. Le traitement automatique du champ des codes (CC) permet alors de déterminer :
- les pôles de recherche principaux d'un sujet ;
- la cartographie des liaisons qui existent entre pôles de recherche au niveau du sujet considéré.
Les pôles de recherche d'un sujet
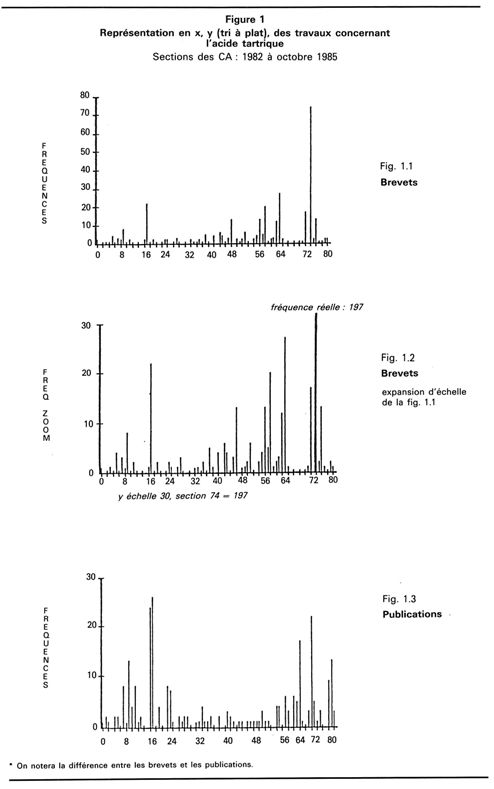
L'analyse en fréquence de la répartition des sections principales dans une recherche bibliographique concernant les brevets traitant de l'acide tartrique ( fig. 1.1 et 1.2) et les autres types de documents concernant le même composé (fig. 1.3) mettent en évidence les différences de pôles de recherche (définis par les numéros de sections des Chemical abstracts) entre la recherche appliquée (fig.1.1 et 1.2) et la recherche fondamentale (fig. 1.3).
Par exemple, en recherche appliquée, la section 74 (Radiation chemistry, Photographic and other related process) est le pôle de recherche principal, alors qu'en recherche fondamentale ce sont les pôles 16 (Fermentation, Bioindustrial chemistry) et 17 (Food and feed chemistry) qui sont les plus importants. On peut ainsi, par cette technique, effectuer des comparaisons rapides entre domaines, thèmes, auteurs, laboratoires, etc. Ces comparaisons sont possibles dans le temps, puisque pour une période donnée (dans notre cas la 1 1e collection), la structure et le contenu des sections restent identiques.
La cartographie des liaisons qui existent entre les pôles de recherche
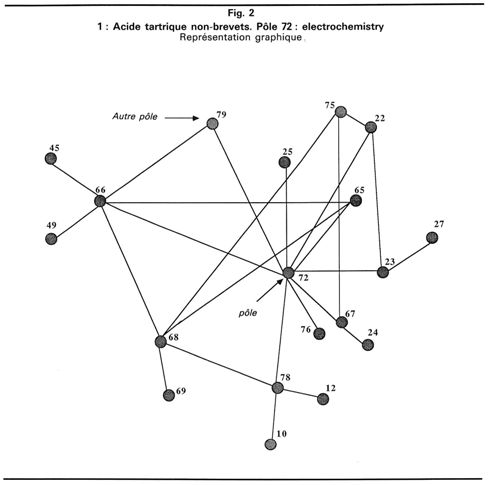
La représentation précédente permet de dégager des pôles de recherche, mais n'explicite pas les relations de ces derniers avec les autres domaines de la chimie. Pour arriver à déterminer celles-ci, nous considérons les sections secondaires qui sont présentes dans les références bibliographiques des sujets analysés. Ainsi le pôle Electrochemistry (section principale 72), dans les publications traitant de l'acide tartrique, est associé à un certain nombre de sections secondaires ; on détermine ainsi les premières liaisons du graphe (fig. 2.1). Lorsque ces sections secondaires deviennent des sections principales, celles-ci génèrent à nouveau des liaisons, ce qui complète le graphe du pôle. Celui-ci est terminé lorsqu'il n'y a plus de sections secondaires, ou que les sections considérées deviennent un autre pôle de recherche.
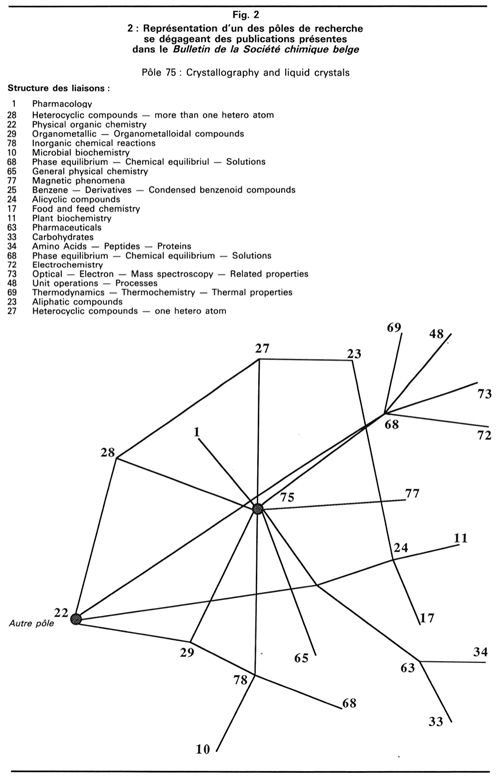
On aboutit ainsi à un graphe de relations entre le pôle considéré et les autres domaines de la chimie. On peut donc déterminer les noeuds principaux qui vont constituer des éléments de comparaison. Cette méthode est généralisable selon les besoins et peut être utilisée comme outil de gestion scientifique (exemple de la figure 2.2 qui décrit en détail un pôle obtenu à partir de l'analyse des publications publiées par le Bulletin de la Société chimique belge).
Le traitement des numéros de registre
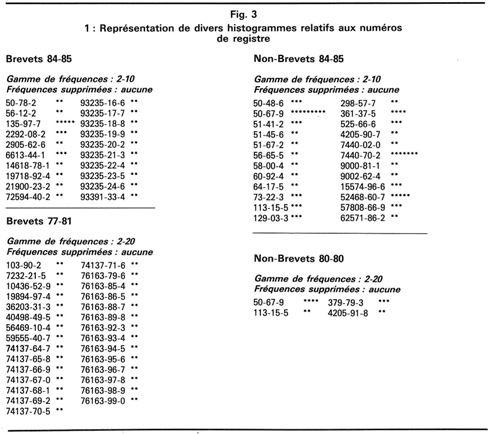
Les composés chimiques sont représentés dans les Chemical abstracts par un numéro de registre. Sur l'ensemble des 7 000 000 de composés répertoriés depuis 1967, plus de 70 % n'apparaissent qu'une fois dans la littérature. Il est donc intéressant, pour une bibliographie donnée, de traiter automatiquement ces derniers, afin de déterminer l'histogramme de leur apparition dans les travaux analysés. Divers profils, correspondant à des types de documents différents sont représentés dans les figures 3.1, et 3.2, les périodes considérées étant de 1982 à nos jours et de 1977 à 1981. Les ensembles bibliographiques ont été réalisés avec les mots clés suivants, recherchés sur l'index de base : HEADACHE x AND P/DT et HEADACHE × NOT P/DT.
HEADACHE(S)
- pour la période 1982-1985 : 256 références
- limité à la période 1984-1985 : 94 références
- se décomposant en : 22 brevets et 72 autres travaux
- pour la période 1977-1981: 177 références
- limité à l'année 1980 : 58 références
- se décomposant en : 17 brevets et 41 autres travaux
Ces résultats permettent de déterminer pour un sujet donné un profil standard, avec les produits les plus usuels. Ce profil sert alors de témoin dans le temps. Le même sujet est traité à intervalles réguliers et analysé de façon identique. Si le traitement fait apparaître une différence avec le profil standard, cela met en évidence des changements dans les habitudes de recherche, ou l'émergence de nouvelles molécules (6, 7, 8).
Comme le programme met en évidence les numéros de publications dans la recherche bibliographique en regard des numéros de registre utilisés, il est possible de tracer le graphe des relations existant entre les divers travaux. En ce sens, cette méthode conduit à des résultats différents de ceux obtenus en ligne avec les commandes ZOOM, GET, MEMTRI, utilisables sur différents serveurs 2. On peut comparer l'ensemble des numéros de registres avec une liste de composés cible organisés en fichier informatique (par exemple des catalyseurs). On aboutit alors à une sélection des travaux sur des critères croisés : la présence d'un ou de plusieurs composés cible ; la déviation des travaux par rapport au profil standard des numéros de registre (par comparaison des deux histogrammes).
Il est évident que les molécules qui ont une structure très proche ont des numéros de registre différents. Ce phénomène limite les applications de la méthode, car on ne pourra pas homogénéiser les composés recherchés par sous-structure. A l'heure actuelle ceci n'est possible que par traitement des tables de connection ou des notations WLN 3 des composés chimiques, car la recherche en ligne par sous-structure ne permet plus ensuite de manipuler les résultats de la façon précédente.
Pour conclure, les banques de données bibliographiques qui sont des outils de recherche documentaire destinés à cerner un problème spécifique, peuvent aussi servir d'instrument de mesure et d'évaluation grâce aux différents champs documentaires. Un traitement adapté de cette information permet de faire de la recherche documentaire un outil d'analyse stratégique (9).