L'i.N.S.E.R.M. et l'information biomédicale
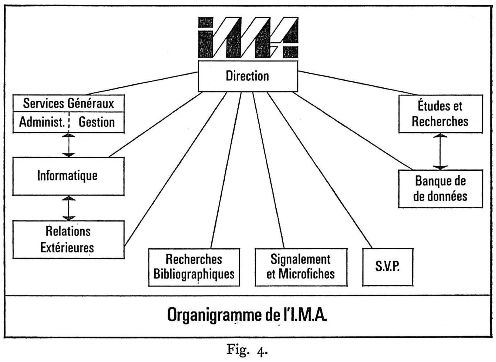
Pour répondre aux besoins spécifiques de la recherche biomédicale, l'Institut de la santé et de la recherche médicale (I.N.S.E.R.M.) a créé son propre centre documentaire I.M.A. (Information médicale automatisée). Tel qu'il a été conçu dans un premier temps, l'I.M.A. comporte trois services : un service chargé de centraliser et de satisfaire les demandes d'information générale; un service signalement et microfiches destiné à rationaliser l'acquisition et la répartition des documents par la création d'un stock central de données et la diffusion de microfiches; enfin un service chargé de répondre aux demandes de recherche bibliographique, de fournir des informations sur les systèmes documentaires opérationnels et de favoriser la diffusion de la littérature biomédicale française en participant au Medlars. Dans un second temps l'I.M.A. a établi un programme de banque de données (S.I.N.B.A.D.) permettant d'obtenir instantanément une réponse précise à tout type de question dans le domaine initialement choisi de l'enzymologie et ultérieurement de la toxicologie. Parallèlement l'I.M.A. mène des études de recherche sur les outils documentaires et procède à l'enseignement des techniques documentaires modernes.
L'Institut National de la Santé et de la Recherche Médicale (I.N.S.E.R.M.) est un établissement public à caractère administratif, placé sous la tutelle du Ministère de la Santé et de la Sécurité Sociale. Sa création en 1964 (en remplacement de l'Institut National d'Hygiène) a marqué une promotion et une extension très nettes de la recherche médicale. Sa mission, considérablement élargie comme l'indiquent ses statuts 1, comportait d'évidentes responsabilités en matière d'information scientifique. L'I.N.S.E.R.M. devait en effet « centraliser et mettre à jour toutes informations sur les activités de recherche médicale exercée tant en France qu'à l'étranger, effectuer, susciter, encourager des travaux de recherche médicale, ou participer à de tels travaux ».
Pour répondre aux besoins documentaires spécifiques de la recherche biomédicale, l'I.N.S.E.R.M. a créé en 1968 son propre centre de documentation: l'I.M.A. (Information Médicale Automatisée). En raison même de son importance nationale et des répercussions que ne manqueraient pas d'avoir, sur l'ensemble du réseau d'information du secteur biomédical, toutes les décisions prises à son niveau, l'I.M.A. devait apporter un soin tout particulier à la conception des services et des systèmes à mettre en place.
I. - Méthodes et programme
A. - Principes de base.
La création des différents services de l'I.M.A. a résulté d'un ensemble d'études préalables qui correspondaient à plusieurs impératifs catégoriques. Tout d'abord, on ne pouvait se dissimuler que les crédits alloués à la Recherche Médicale, si généreux soient-ils, ne correspondent jamais pleinement à ses besoins. Il fallait donc cerner avec la plus grande rigueur les problèmes à résoudre et adopter des solutions tout ensemble les plus efficaces et les moins onéreuses.
Cette double préoccupation correspondait d'ailleurs à une démarche adoptée aux États-Unis au début des années 60 : la programmation des décisions (Planning, Programming, Budgeting System ou P.P.B.S. - en français : Rationalisation des Choix Budgétaires, ou R.C.B.) -, méthode s'appuyant elle-même sur l'analyse de systèmes, facteur essentiel d'une programmation optimale (1).
En dépit de la complexité des systèmes d'information et des difficultés que l'on rencontre pour mettre en évidence leur efficacité, cette méthode se pratique maintenant dans plusieurs bibliothèques et centres de documentation (9).
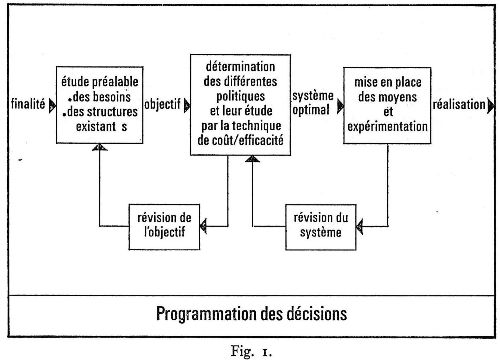
On peut la schématiser ainsi (fig. I):
A l'origine de toute étude de programmation des décisions se situe une finalité conçue a priori par une autorité responsable. Cette finalité se révèle soit quand apparaît un problème nouveau à résoudre, soit, le plus souvent, quand une lacune se manifeste dans un état de fait.
- La première phase consistera en une étude analytique préalable de la situation : mise en évidence des besoins, repérage des structures existantes. De cette étude émergera l'objectif précis à atteindre.
- La seconde phase comportera un recensement exhaustif des politiques susceptibles de réaliser ce but. Mais ce recensement peut donner lieu à une remise en question de l'objectif. La comparaison, pour chaque politique, entre coût prévu et efficacité attendue doit permettre de choisir le système optimal.
- Dans une troisième phase, le service sera mis en place et expérimenté. Les contraintes qui apparaissent au niveau des moyens peuvent entraîner une révision du système choisi.
- La quatrième phase est celle de la réalisation de l'objectif initial.
B. - Axes et programme de réalisation.
Devant l'ampleur des problèmes à résoudre, ces principes devaient être appliqués par étapes. Le système d'information prévu était destiné à l'ensemble de la communauté biomédicale (Recherche, Université, Industrie). Sa structure devait intégrer les services centraux, centres spécialisés, centres d'analyse de l'information, en un réseau permettant d'utiliser toutes les potentialités et de faciliter les échanges à tous niveaux.
Mais on comprendra aisément que l'I.N.S.E.R.M. ait voulu résoudre en priorité les problèmes documentaires de ses chercheurs. C'était d'ailleurs la tâche la plus difficile, en raison tant de l'importance cruciale de l'information pour la recherche biomédicale que de l'étendue, de la complexité et de la multiplicité des besoins à satisfaire. Mais le succès de cette première entreprise garantirait pour une large part la réussite dans les autres secteurs.
La réalisation de ce premier programme (qui se limitait à l'étude et à la mise en place des services centraux rigoureusement indispensables) a comporté les phases évoquées plus haut : définition des objectifs, analyse de la situation, conception des solutions possibles, expérimentation et lancement. Les programmes ultérieurs devaient se développer sur le même modèle.
Il importait en premier lieu de connaître avec la plus grande précision :
la population à servir (sa répartition géographique, et par discipline; les degrés d'ancienneté dans la recherche, la formation de base des chercheurs...), les habitudes documentaires des chercheurs (sources utilisées, lectures préférentielles) et leurs besoins documentaires, - les moyens disponibles en France ou à l'étranger, - les structures et circuits d'information et tous les éléments qui pourraient par la suite être intégrés en un réseau organisé.
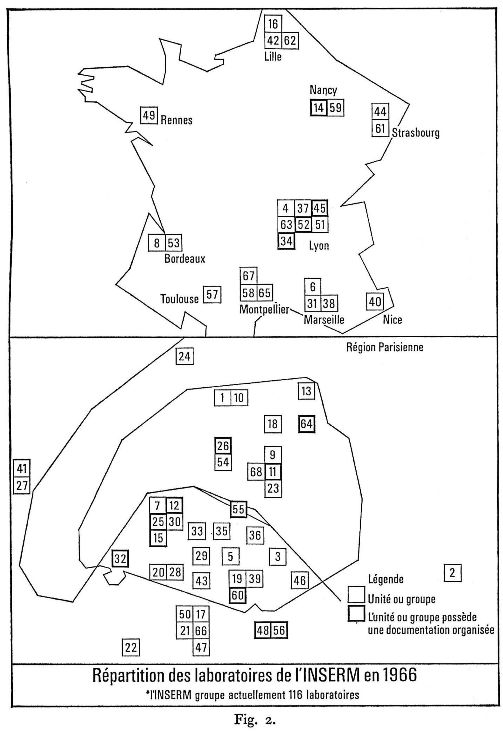
On a donc procédé en 1966 à un ensemble d'études : questionnaire envoyé à 500 chercheurs, suivi d'une centaine d'interviews; inventaire des moyens disponibles dans les laboratoires (fonds documentaire, équipements et personnel). Rappelons qu'à l'époque l'I.N.S.E.R.M. comprenait 66 laboratoires (116 aujourd'hui) et quelques centaines de chercheurs isolés (fig. 2).
Très schématiquement, les résultats de ces études dessinaient la situation suivante : les fonds documentaires des laboratoires de l'I.N.S.E.R.M. n'étaient pas exploités rationnellement ni harmonisés, - les chercheurs consacraient à des tâches documentaires un temps déjà excessif (un tiers de leur temps global de travail) -, ils étaient très insuffisamment informés des sources et des techniques documentaires modernes et en tous cas les utilisaient mal (11).
En conséquence, et tout en tirant le meilleur parti des ressources existantes, les services de documentation à créer devaient permettre au chercheur : d'accéder rapidement à un fonds documentaire normalisé, de disposer d'un « bureau central » d'orientation et d'information et surtout d'utiliser pour les recherches bibliographiques des systèmes automatiques, seuls capables de faire face au volume considérable et sans cesse croissant de la littérature biomédicale.
Pour résoudre ce dernier problème (véritable état d'urgence), les solutions qui s'offraient étaient claires : on ne pouvait que recourir à des systèmes déjà opérationnels, tel le MEDLARS 2. En effet, l'élaboration d'un système français de recherche bibliographique eût demandé plusieurs années et fait double emploi avec les systèmes américains. En revanche, l'I.N.S.E.R.M. devait et pouvait innover dans un domaine dont les immenses possibilités commençaient à apparaître : celui des banques de données.
Les très nombreuses et très précises informations recueillies grâce à ces études firent l'objet d'un rapport de synthèse (12) comportant un plan de réalisations à court terme, c'est-à-dire les trois premiers services centraux de l'I.N.S.E.R.M. (SVP, « Signalement et Microfiches » et « Recherche Bibliographique ») que nous décrivons plus loin.
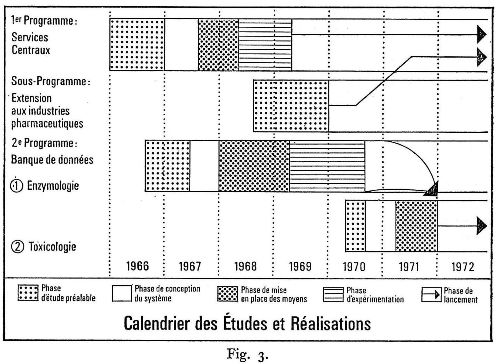
Toutefois, avant de mettre ce plan à exécution, il fut décidé d'expérimenter pendant un an ces trois services en faisant appel à la collaboration d'une dizaine de laboratoires de l'I.N.S.E.R.M. Cette expérimentation était en effet nécessaire pour vérifier « sur le terrain » les hypothèses de départ et pour tenir compte des problèmes que pouvaient soulever de profondes modifications dans les habitudes documentaires des chercheurs. La figure 3 montre la chronologie des phases de ces études et réalisations. On pourra y remarquer l'existence d'un « sous-programme » qui concernait l'extension des services centraux à une autre catégorie d'utilisateurs : les laboratoires pharmaceutiques. Mais dès l'étude initiale des besoins (1968-1969), il était apparu que cette population pouvait être satisfaite par le programme général.
D'autre part, un second programme d'envergure devait être élaboré dès la fin 1966 : le programme « banque de données », qui s'est développé selon les mêmes phases et le même modèle que le précédent.
L'objectif à atteindre était de constituer un système permettant d'accéder directement à des données (aux faits scientifiques eux-mêmes) et non plus seulement à des références bibliographiques. Après des études préalables, l'enzymologie a été choisie comme premier domaine. Fut élaboré ensuite un plan d'ensemble et furent mis en place les moyens nécessaires à une exploitation expérimentale : séminaires de formation des analystes, écriture des programmes... Une série de démonstrations a montré en 1969 qu'il était possible de passer au stade opérationnel. La réussite de ce premier programme a incité les responsables de l'I.N.S.E.R.M. à préparer la constitution d'une seconde banque de données, en toxicologie cette fois. Bien entendu, cette seconde opération bénéficiait de structures déjà en place et son déroulement en a été accéléré.
II. - Description des services centraux
Avant de décrire les services techniques de l'I.M.A., il convient d'évoquer l'infrastructure de cet organisme et les directions qu'il a prises au triple niveau scientifique, politique et économique.
A. - Infrastructure.
Établi dans le bâtiment I.N.S.E.R.M. du Centre Hospitalier de Bicêtre, l'I.M.A. a aujourd'hui un effectif de 45 personnes et dispose à quart de temps d'un ordinateur UNIVAC 1107 qui sera remplacé prochainement par un matériel plus moderne et plus puissant.
Outre ses services techniques « productifs », l'I.M.A. comporte des services généraux dont une section « Informatique » d'une importance particulière puisque la plupart des services assurés par l'I.M.A. sont automatisés. La cellule « Informatique » de l'I.M.A. remplit trois fonctions : analyser les besoins exprimés par les sections techniques; réaliser et mettre à jour des programmes de documentation automatique; assurer l'exploitation. La première fonction consiste essentiellement à analyser et à traduire en termes d'informatique les besoins exprimés par les utilisateurs. Tout projet correspondant à ces besoins fait l'objet d'une étude de faisabilité, puis sont précisés les moyens à mettre en œuvre, le planning de réalisation du projet, les caractéristiques générales de l'exploitation. Une fois établi ce cahier des charges, la cellule informatique fournira des produits correspondant aux objectifs qu'on se proposait d'atteindre et économiquement satisfaisants. En fait, on établit d'abord un programme prototype, puis un programme opérationnel susceptible d'être régulièrement corrigé et modernisé. Pour ce qui est, enfin, de l'exploitation proprement dite, la cellule informatique de l'I.M.A. exerce un rôle de surveillance et de contrôle de l'exécution des programmes. Elle garantit la pleine réalisation des objectifs et le respect des délais d'exécution. L'équipe informatique de l'I.M.A. comprend deux analystes, un programmeur, un préparateur de travaux, un opérateur et une perforatrice.
Autre élément essentiel de l'infrastructure de l'I.M.A. : sa gestion. Il faut en premier lieu assurer le meilleur rendement des crédits alloués. Sont donc appliquées les méthodes modernes de gestion que le secteur public adopte d'ailleurs de plus en plus. Parallèlement aux études classiques d'organisation destinées à améliorer les circuits internes d'information et la rentabilité des différentes sections techniques, l'I.M.A. applique certaines techniques de « management » du secteur privé : mise en place - tout en conservant le système comptable classique -d'une comptabilité analytique; lancement d'un « tableau de bord » synthétisant les différentes informations statistiques et devant provoquer des réactions en cas de distorsion par rapport aux normes pré-établies.
Mais la question se pose de savoir s'il faut aujourd'hui considérer l'information scientifique comme un « service public » ou comme un « produit commercial » vendable et soumis aux lois du marché. Ce dilemme émerge des travaux des nombreux groupes d'études nationaux ou internationaux sur l'économie de l'information. Sans opter pour l'une ou l'autre de ces deux tendances, l'I.M.A. s'oriente vers un régime d'autofinancement, du moins partiel. Un organisme scientifique ne saurait faire des bénéfices, mais il peut chercher à pratiquer des prix de ventes susceptibles de compenser des prix de revient. On simule en quelque sorte le fonctionnement d'une entreprise privée mais en obéissant à des motivations tout autres, puisqu'il s'agit avant tout d'exercer un meilleur contrôle sur l'efficacité des services et sur leur constante adaptation aux besoins des utilisateurs.
Le souci de rentabilité et le principe d'autofinancement imposaient de créer une section « relations extérieures » spécialement chargée d'études de marché et de la promotion des services. Mais par-delà ces préoccupations de caractère économique, l'I.M.A. poursuit une politique de sensibilisation des utilisateurs aux problèmes de l'information scientifique en leur faisant connaître les moyens modernes dont ils peuvent disposer et en faisant également appel à leur coopération. Cette politique promotionnelle se manifeste sous plusieurs formes : programmes audiovisuels, ensemble de brochures décrivant les services de l'I.M.A., conférences, séminaires d'initiation.
B. - S. V. P. : service d'information et d'orientation
A l'origine du service S.V.P. il y a deux préoccupations essentielles : répondre à un besoin très clairement exprimé par les chercheurs lors de l'enquête 1966; doter l'I.N.S.E.R.M. d'un « Central d'information » qui puisse canaliser et satisfaire les demandes d'informations de toute nature et de toute origine qu'on lui pose le plus souvent par téléphone.
Le S.V.P. a donc un double rôle. Plaque tournante, service d'aiguillage, il oriente les demandeurs vers les centres spécialisés. Mais il aide à résoudre des problèmes d'ordre pratique dans des délais très brefs.
La mise en place du service s'est effectuée progressivement car tout en répondant aux questions qu'on lui posait, le S.V.P. a dû constituer ses propres sources d'information. D'une part ont été rassemblés des ouvrages de références : répertoires de personnes physiques et organismes, annuaires et catalogues. De l'autre ont été créés des fichiers spécialisés concernant sigles, congrès, associations médicales, sources. Un système d'exploitation mixte (Peek-a-boo et dossiers) a été jugé le mieux adapté pour la période initiale.
Les questions reçues au centre sont enregistrées sur un formulaire étudié permettant de noter le maximum d'informations sur le demandeur, la question (date, forme, objectifs), la réponse (date, forme, temps de traitement et nom de la personne qui l'a faite), sources utilisées (internes ou externes), et observations telles que difficultés rencontrées, contrôle et jugement du demandeur sur la qualité de la réponse.
Les questions sont traitées dans un délai très court (80 % dans la journée), la plupart font l'objet d'une réponse directe. Dans le cas de questions très spécialisées, le S.V.P. oriente vers le centre qui détient le renseignement recherché.
Parallèlement au traitement proprement dit des questions, les fichiers et dossiers sont complétés par des informations recueillies dans des périodiques, des ouvrages et par les réponses faites aux questions reçues. Enfin, l'examen des sources utilisées et des observations portées sur les formulaires rend possible une réflexion constante sur l'orientation et l'organisation des outils existants ou à créer.
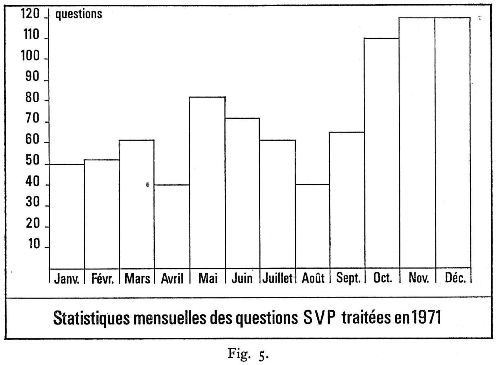
Les résultats enregistrés en 197I sont très significatifs : 870 appels téléphoniques ou demandes correspondant à environ 1 200 questions dont 98 % ont été satisfaites (350 questions en 1970) (fig. 5).
La clientèle du service appartient au secteur public comme au secteur privé. Une étude du profil des interlocuteurs et du type de questions traitées a été effectuée en 197I et ses conclusions vont permettre une meilleure orientation des services.
Le remplacement progressif des fichiers manuels par des fichiers de type Peek-a-boo -, puis éventuellement par un enregistrement en ordinateur et une interrogation sur console - permettra au S.V.P. de faire face à l'accroissement des demandes tout en maintenant des délais rapides de réponse. La connaissance approfondie des sources documentaires, les multiples contacts établis avec les centres spécialisés aboutissent dès maintenant à la constitution d'un véritable: réseau d'information. Telles sont les conclusions d'une enquête récente menée dans le cadre de l'I.M.A. Des efforts seront faits pour intensifier et développer ce réseau.
C. - Service « signalement et microfiches »
L'I.N.S.E.R.M. étant un organisme très décentralisé (une centaine de laboratoires répartis sur l'ensemble du territoire), ses laboratoires de recherches avaient tendance à multiplier les abonnements aux revues scientifiques. Il est donc devenu indispensable de rationaliser l'acquisition et la répartition des documents.
D'autre part il était nécessaire de permettre un acheminement très rapide des informations dans un domaine où la compétition entre équipes est élevée et où la durée de validité des articles n'excède pas quelques années.
On a donc créé un service de centralisation, signalement et diffusion rapide de la littérature biomédicale courante dont les objectifs sont les suivants : compléter le réseau documentaire offert par les bibliothèques, élargir le champ de lecture des utilisateurs et leur fournir des articles individuels dans les délais les plus rapides.
Après des études approfondies et une expérimentation d'une année (2) il est apparu que la diffusion de l'information sur support microfiche était la méthode la plus efficace pour remplir cette mission. Le prêt des périodiques aurait abouti à des délais d'attente trop élevés et inévitablement à une multiplication onéreuse des abonnements au niveau central. La photocopie systématique des articles se serait avérée trop coûteuse. En outre, l'emploi des microfiches permettrait d'obtenir des collections de documents d'encombrement réduit et de classement aisé, utilisables sur les lieux même du travail.
Depuis sa création en 1968, le Service « Signalement et microfiches » (S.S.M.) a constitué un stock documentaire considérable de 190 000 articles des 300 plus importantes revues mondiales reproduits sur microfiches; soit un volume d'environ 3 000 000 de pages (l'équivalent de 300 m de rayons de bibliothèque) accessible au chercheur dans son laboratoire.
La mise en place du S.S.M. s'est effectuée de la manière suivante :
a) Création du stock central de périodiques. Pour effectuer un choix très rigoureux des revues devant figurer dans cette collection, on s'est appuyé d'une part sur l'étude comparative de listes préexistantes, d'autre part sur l'évaluation faite par les chercheurs. Afin de faciliter la diffusion rapide des articles, une partie de la collection est microfichée intégralement ce qui implique des réajustements d'une année à l'autre en fonction des statistiques de répartition des demandes.
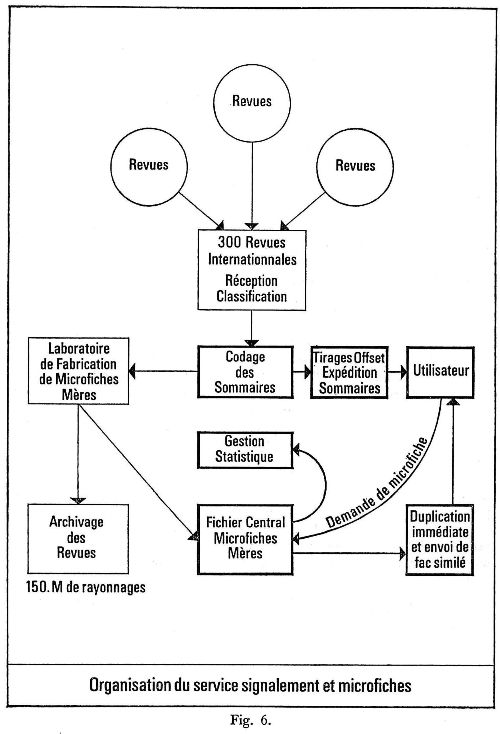
b) Mise au point des circuits d'information pour les deux principales fonctions : signalement des articles disponibles, par diffusion systématique des sommaires de chaque exemplaire de revue, au fur et à mesure de sa réception au fonds documentaire central. L'utilisateur a donc la possibilité d'effectuer une première sélection sur titre des articles susceptibles de l'intéresser. Envoi sur demande et par retour du courrier, de duplicata des microfiches du stock central (microfiches 105 X 150 pouvant contenir 24 pages de texte). Deux jours après sa demande l'utilisateur a donc la possibilité de lire l'article de son choix, sur lecteur-agrandisseur. Des tirages sur papier peuvent être obtenus au moyen d'appareils lecteurs-reproducteurs (fig. 6).
Mais l'emploi d'un support documentaire relativement nouveau ne pouvait manquer de susciter d'assez fortes réticences de la part des utilisateurs : d'une part ils avaient des habitudes documentaires fortement enracinés, de l'autre la lecture sur écran répugnait à beaucoup d'entre eux. Avant d'implanter définitivement le S.S.M., on a donc procédé à une expérimentation des services dans un domaine limité, la Biochimie et auprès d'une population de 100 chercheurs. Au cours de cette année d'expérimentation, on a pu observer un véritable retournement de la situation et l'adoption progressive des microfiches par l'ensemble des utilisateurs. L'expérience a mis en valeur les points suivants : importance de la préparation des utilisateurs (séminaires de mise en route) et de dispositifs de contrôle (interviews, visites, formulaires); importance de la répartition des appareils de lecture en fonction de leur type (lecteurs simples ou lecteurs-reproducteurs) et du nombre d'utilisateurs. Le S.S.M. assure un contrôle régulier et veille constamment à améliorer la qualité des microfiches et la rapidité des circuits.
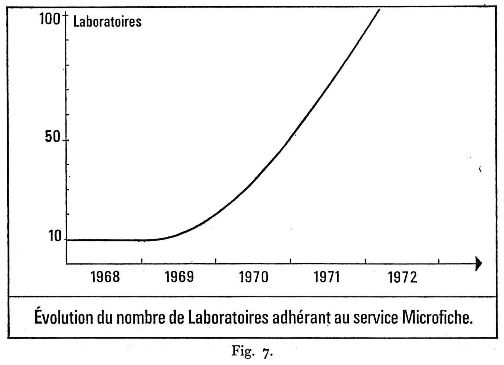
Trois ans après la fin de l'expérience et malgré le changement imposé aux habitudes documentaires, on constate : une augmentation rapide du nombre des adhérents, - 9 laboratoires servis en 1968, 97 en décembre 197I, dont une quinzaine du secteur privé (fig. 7) -, une population d'utilisateurs décuplée en 3 ans ce qui marque bien l'intérêt croissant porté par les chercheurs à cette forme de documentation. Les courbes statistiques sont particulièrement éloquentes. En 197I, le service a satisfait 62 000 demandes d'articles sur microfiches et il est vraisemblable que ce chiffre dépassera 100 000 en 1972, compte tenu de l'évolution des deux derniers trimestres 197I où la production est voisine de 350 duplicata par jour (fig. 8).
Une telle progression implique une organisation rigoureuse du service. Une chaîne de travail a été mise au point après étude analytique des tâches (70 composantes élémentaires).
Une étude générale d'amélioration de la rentabilité du système est en cours; dans cette optique sont prévus : la création d'un atelier de microphotographie à l'I.M.A. pour la fabrication des microfiches mères, (actuellement sous-traitées); la mise en place de moyens modernes de stockage, recherche en fichiers, duplication et distribution automatisées de microfiches, mécanisation de la gestion; enfin on prévoit une intégration à court terme des services S.S.M. et S.R.B. (liaison entre le système de signalement et le système d'accès aux documents).
D. - Service « recherche bibliographique » (S.R.B.)
Le volume des informations publiées est considérable dans le domaine biomédical et augmente régulièrement. Le rôle du Service « Recherche Bibliographique » est d'aider ses utilisateurs dans le travail préalable de sélection des informations utiles.
Créé à l'origine pour répondre aux besoins des chercheurs de l'I.N.S.E.R.M. en matière de bibliographie, le S.R.B. s'est progressivement ouvert à tous les secteurs de la recherche biomédicale, publics ou privés, et en particulier de toute industrie ayant un département de recherche biologique (industries pharmaceutique, alimentaire, ...).
Le S.R.B. a pour objectifs essentiels de répondre à toute demande de recherche bibliographique; d'informer sur les diverses possibilités offertes par les systèmes documentaires opérationnels; de favoriser enfin la diffusion de la littérature biomédicale française.
Un traitement efficace de l'information scientifique ne peut plus se concevoir sans recourir à l'ordinateur qui permet de compiler un volume considérable de données, accélère la recherche documentaire et assure une plus grande exhaustivité. C'est pourquoi le S.R.B. s'est spécialisé dans l'étude et l'utilisation des systèmes automatisés. Afin de mettre rapidement à la disposition des utilisateurs des services déjà opérationnels et d'éviter une duplication des systèmes existants, le S.R.B. a fait appel aux grands systèmes documentaires tels que MEDLARS, CHEMICAL ABSTRACTS, ASCA, EURATOM, BIOLOGICAL ABSTRACTS...
a) Étude critique préalable des systèmes documentaires automatisés.
Mais la première condition de l'efficacité de ce service était de procéder à une évaluation de ces systèmes pour connaître leurs possibilités spécifiques. On a donc entrepris une étude descriptive de chaque système : domaine couvert, organisation, antériorité, structure du langage documentaire utilisé, services offerts... ; puis une étude expérimentale basée sur des recherches rétrospectives ou des profils tests, destinée à apprécier l'efficacité du système tant au point de vue de sa maniabilité, que de la pertinence des réponses et de la rapidité d'entrée des informations dans le système. Les critères de choix essentiels ont été l'importance du domaine couvert, l'exhaustivité et l'ancienneté opérationnelle.
Actuellement trois grands systèmes documentaires couvrent l'ensemble des sciences biomédicales : celui de l' « Information Science Institute » (I.S.I.) (Philadelphie), MEDLARS (National Library of Medicine [N.L.M.]-U.S.A.), EXCERPTA MEDICA (Amsterdam). Il est rapidement apparu que seul MEDLARS pouvait être adopté, en 1968, comme système de base, en raison de son antériorité, de son domaine coïncidant exactement avec celui des chercheurs de l'I.N.S.E.R.M., de la souplesse de son organisation basée sur la répartition des tâches et la participation technique des filiales. L'étude expérimentale de MEDLARS a porté sur environ 1 500 recherches bibliographiques et 100 profils analysés et formulés, puis envoyés à l'étranger pour traitement sur ordinateur. Mais on a aussi étudié et testé selon la même méthode : ASCA (I.S.I.) EXCERPTA MEDICA pour le domaine biomédical, CHEMICAL ABSTRACTS pour le secteur chimique et biochimique, les systèmes EURATOM et INIS pour la médecine nucléaire, le système NASA pour la technologie médicale spatiale, SIE pour les projets de recherche en cours. Les études expérimentales visent moins à une évaluation rigoureuse des systèmes - comme celles effectuées par Cleverdon et Lancaster - dont le coût serait prohibitif, qu'à une connaissance approfondie de leurs structures et de leur potentialités.
b) Utilisation des systèmes documentaires automatisés.
Rappelons qu'un système documentaire automatisé comporte trois principales fonctions :
- l'analyse et l'entrée des données
- l'analyse et la formulation des demandes de recherche
- le traitement sur ordinateur.
Le S.R.B. participe à ces trois fonctions dans le cadre du réseau MEDLARS dont il est le centre français. En revanche, le S.R.B. n'assure ces fonctions que partiellement en ce qui concerne les autres systèmes de documentation automatique qu'il utilise couramment.
Nous nous étendrons peu ici sur le rôle du S.R.B. comme centre MEDLARS qui a fait l'objet de plusieurs études détaillées (5, 8, 10, 13). Il importe surtout de mettre en valeur le rôle joué par le S.R.B. lorsqu'il s'agit de confronter un utilisateur et sa demande de recherche bibliographique avec tel ou tel système de documentation automatique et ses contraintes propres. Cette fonction de médiateur est essentielle ne serait-ce qu'en raison du coût du traitement informatique qui impose beaucoup de rigueur dans la formulation préalable des questions. Le S.R.B. a donc acquis une connaissance approfondie des potentialités et des règles des systèmes documentaires automatisés, de plus en plus nombreux, susceptibles d'être utilisés dans le domaine biomédical. En corollaire, le S.R.B. doit assurer la formation de spécialistes non seulement au niveau de l'I.M.A. mais aussi dans le cadre des centres coopérants, français ou étrangers.
I. -Le Centre MEDLARS français.
En 1969 un accord a été conclu entre l'I.N.S.E.R.M. et la National Library of Medicine (U.S.A.) permettant à l'I.M.A. d'exploiter sur son propre ordinateur l'ensemble du fichier MEDLARS. Comme chaque centre du réseau MEDLARS, l'I.M.A. prend en charge l'analyse des revues biomédicales publiées dans son pays (140 revues françaises). Ainsi se trouve améliorée la diffusion des travaux scientifiques français.
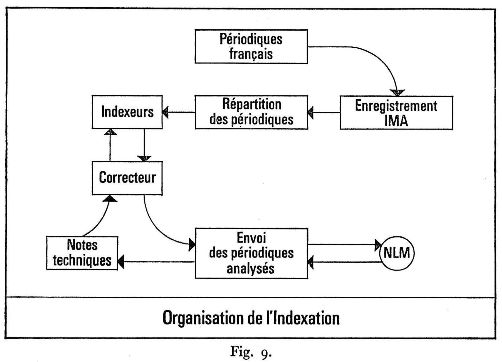
Dès 1969, ont été mises en place les structures nécessaires : création et organisation d'un service d'indexation (quatre personnes, dont trois ont fait un stage de six mois aux U.S.A.) et mise au point de circuits rapides d'information avec les éditeurs et avec la N.L.M. (fig. 9); extension du service de formulation des recherches et réorganisation de ce service en étroite collaboration avec la section informatique. En effet, l'exploitation de MEDLARS a nécessité la mise au point des programmes de traitement adaptés à la configuration de l'ordinateur de l'I.N.S.E.R.M. (UNIVAC 1107). Les normes et les codes du langage de formulation ont été mis au point en accord avec les caractéristiques et améliorations apportées par les programmes français.
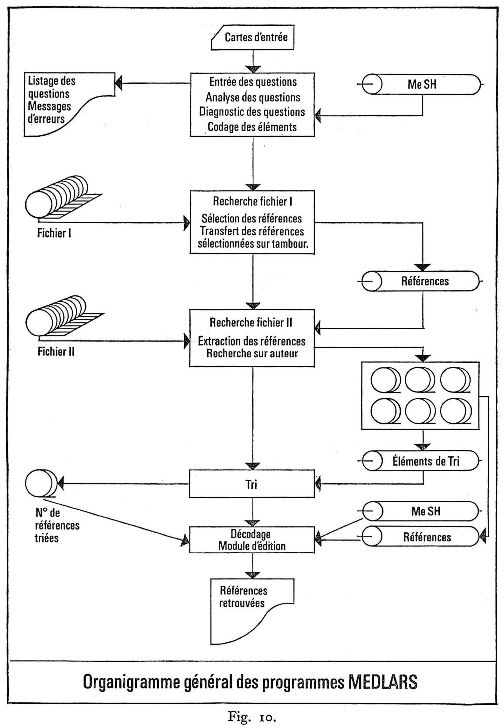
On peut distinguer trois programmes principaux (fig. 10) : Traitement des dictionnaires : grâce à un algorithme de compression du dictionnaire la codification est assurée entièrement en mémoire centrale, évitant ainsi de prohibitifs appels aux mémoires à accès direct. Programme de recherche : ce programme ne faisant intervenir qu'une partie du fichier (1) a été construit à partir d'un algorithme de traitement permettant une manipulation de bits, souple et rapide. Ceci permet de traiter en « batch » un nombre important de questions (plus de 100) et également d'éviter tout freinage dans le déroulement des bandes magnétiques. Ainsi est obtenue une réduction importante du temps de traitement. Programme de tri et d'édition : dans ce programme l'effort a porté sur la souplesse et la qualité de présentation des résultats. Un programme paramétré d'édition permet des présentations variées : impressions par ordre alphabétique, par langue, par date de publication..., édition sur papier ou cartes.
L'ensemble des programmes écrits en assembleur UNIVAC (SLEUTH) représente 14 000 instructions compte tenu des programmes de services nécessaires. Sous réserve de modifications peu importantes, le programme peut être utilisé pour tout système conçu à partir de mots clés, sa structure étant totalement indépendante du contenu des fichiers utilisés.
2. - La médiation entre l'utilisateur et les systèmes de documentation automatique.
Pour les autres systèmes de documentation automatique cités plus haut (ASCA., CHEMICAL ABSTRACTS, ...) le S.R.B. n'assure actuellement aucune fonction d'indexation ou de traitement informatique. Des analystes spécialisés dans les techniques propres à chaque système assurent la liaison avec les utilisateurs et traduisent en équation de recherche leurs questions qui sont ensuite envoyées pour traitement à des centres français ou étrangers.
Qu'il s'agisse de MEDLARS ou des autres systèmes, l'analyse des demandes de recherche bibliographique et leur mise en équation (formulation) se fait selon une démarche identique. Les demandes sont enregistrées sur un formulaire détaillé : énoncé précis de la question, objectif, exhaustivité souhaitée... Il s'agit soit d'une recherche rétrospective portant sur une période plus ou moins longue, soit d'un abonnement à une diffusion mensuelle sur « profil ». Chaque demande fait l'objet d'une étude préalable en fonction d'un certain nombre de critères (type de demande, urgence, domaine, période de temps à explorer). Puis la décision est prise d'utiliser un ou plusieurs systèmes, automatisés ou non. A ce stade, on fait également une estimation des résultats probables de la recherche et pour toute question un peu complexe, un entretien téléphonique avec le demandeur permet de lever les incertitudes. La demande est ensuite préparée pour le traitement.
Tout traitement documentaire nécessite la mise en coïncidence des termes de la demande et de ceux contenus dans les documents. Il faut donc recourir à un langage qui peut être « naturel », c'est-à-dire constitué de mots ou de racines de mots tirés du vocabulaire scientifique (CHEMICAL ABSTRACTS, ASCA) ou normalisé (MEDLARS). L'étape préparatoire au traitement automatique proprement dit, ou « formulation » de la recherche, consiste en une analyse conceptuelle de la demande, en la traduction des différents concepts dans le langage naturel ou normalisé approprié au système documentaire choisi et en une organisation des mots-clés en équation de recherche.
Ayant son langage propre et ses propres règles de formulation, chaque système requiert des analystes formés à toutes ces techniques documentaires. Par ailleurs, on conçoit aisément qu'un réseau d'information gagne en efficacité si la formulation des demandes est décentralisée. Les problèmes de formation se posent donc ici de façon très aiguë.
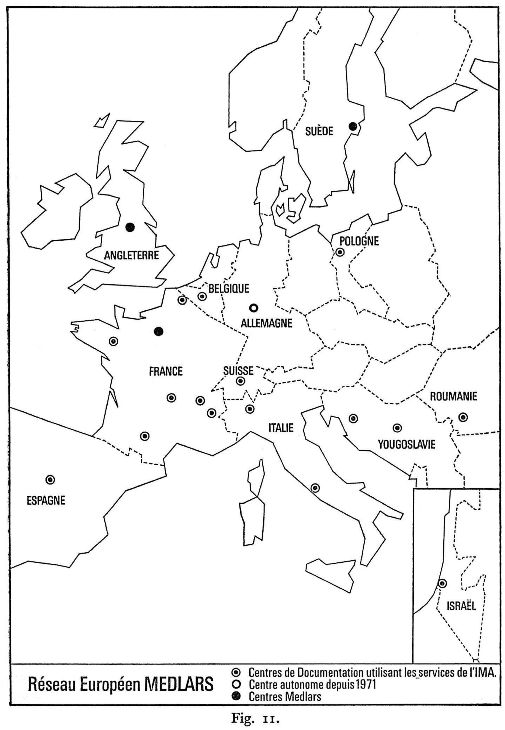
Le temps de formation d'un spécialiste est relativement long. Outre de bonnes connaissances scientifiques indispensables au départ, il doit acquérir une bonne culture dans le domaine de la documentation en général, tout en approfondissant les techniques spéciales aux systèmes documentaires automatisés. Enfin une longue pratique est absolument nécessaire. Formée à l'origine dans des centres étrangers (à la N.L.M. pour MEDLARS, à l'Université de Nottingham et au Karolinska Institut et pour CHEMICAL ABSTRACTS, BIOLOGICAL ABSTRACTS...), l'équipe du S.R.B. participe activement aux cours donnés à l'I.M.A. (voir en f) et aide à la création d'antennes régionales en France ou à l'étranger (fig. II).
c) Bilan sommaire des réalisations.
Les 140 revues françaises représentent environ 13 ooo articles analysés par an. La prise en charge de cette analyse dès 1969 a permis une accélération non négligeable de l'entrée des articles français dans le système, donc de leur parution dans l'Index Medicus, principale publication de MEDLARS.
Toutes les recherches rétrospectives ont été effectuées par MEDLARS. Plus de 4 ooo recherches ont été traitées par le S.R.B., dont environ 2 500 sur l'ordinateur de l'I.N.S.E.R.M. Pour la diffusion sélective sur « profil d'intérêt », la répartition est la suivante :
500 profils sont traités chaque mois par MEDLARS
40 profils hebdomadaires sont traités par CHEMICAL ABSTRACTS
20 profils hebdomadaires sont traités par ASCA
20 profils sont traités par d'autres systèmes.
Voici pour ces deux types de traitement les statistiques 197I :
I. - Répartition des questions par mode de demande.
10 % par téléphone
20 % par visite
45 % par lettre
20 % par l'intermédiaire de bibliothécaires formés au MEDLARS.
2. - Répartition des questions par origine des demandeurs.
30 % émanent de chercheurs I.N.S.E.R.M.
35 % émanent des facultés, hôpitaux, instituts, C.N.R.S., I.N.R.A. 3, etc.
15 % émanent de l'industrie privée
20 % émanent de l'étranger.
3. - Répartition des questions MEDLARS en fonction du temps de traitement.
24 % ont reçu une réponse dans un délai de 10 jours
24 % ont reçu une réponse dans un délai de 15 jours
35 % ont reçu une réponse dans un délai de 20 jours
17 % ont reçu une réponse dans un délai de 20 à 30 jours.
L'objectif est de réduire le temps de traitement à 10 jours maximum.
4. - Répartition des questions par domaine.
biochimie : 12 %
pharmacologie, toxicologie : 10 %
neurologie, psychiatrie : 7 %
reproduction, maladie néonatales : 6 %
circulation, hémodynamique, maladies des vaisseaux : 5 %·
Les recherches dans le domaine dentaire ont été relativement importantes r 3.5 %.
- L'élaboration d'un thesaurus médical bilingue français-anglais a été entreprise en 1970, à partir du Medical Subject Headings, thesaurus du MEDLARS. Cet ouvrage est sur le point d'être publié et comprendra 8 ooo mots-clés classés alphabétiquement (avec 9 000 références croisées), puis systématiquement. Un index anglais et un K.W.I.C. mis en annexe en faciliteront l'emploi.
d) Perspectives
Deux actions parallèles sont en cours pour harmoniser et coordonner le service Microfiches et le service Recherche bibliographique : éditions des profils sur cartes 105 X 150 (format identique à celui des microfiches), indication à la suite de la référence bibliographique du code de la microfiche. Le double de chaque carte ayant été fourni à l'utilisateur, celui-ci pourra l'envoyer directement au S.S.M. pour obtenir la microfiche.
Le S.R.B. envisage l'exploitation du MEDLINE, système de documentation à interrogation directe, dont le fichier est le même que celui du MEDLARS, mais réduit (le fichier MEDUNE correspondra à 1 ooo périodiques analysés au lieu de 2 800). Le MEDLINE (extension du MEDLARS) représente un progrès technique considérable : il permet de visualiser en temps réel des références résultant de la formulation et de corriger immédiatement sur le mode conversationnel la stratégie de recherche jusqu'à obtention de résultats satisfaisants. On peut tester ainsi les recherches avant tout traitement sur l'ensemble du fichier et offrir instantanément à l'utilisateur un échantillon de références bibliographiques en réponse à sa question.
E. - Système d'accès direct aux données : S.I.N.B.A.D.
Le service de Recherche bibliographique fournit des références. Le but du système que nous allons maintenant décrire est de répondre à un autre besoin : l'obtention immédiate d'une donnée précise. Les systèmes de documentation automatique « classiques » ne sont pas adaptés à ce type de problème : en réponse à une question ils fournissent une liste de références. Il reste alors, après sélection des titres les plus pertinents, à se procurer les documents_et c'est à la lecture qu'apparaîtra enfin l'information recherchée. On voit donc que pour répondre à ce type de question de tels systèmes sont lourds : la sélection est faite par approximations successives à 3 niveaux (par une formulation convenablement choisie, par élimination des titres non pertinents, par la lecture de l'article).
En revanche, le système d'accès aux données S.I.N.B.A.D. (Système Informatique pour Banque de Données) supprime toutes ces étapes et obtient, en réponse à une question précise, la donnée elle-même et ceci immédiatement. Il permet d'obtenir une réponse précise et instantanée à tout type de question portant sur les données.
Une réponse précise : elle peut être numérique (un pH, une température, une concentration, une activité enzymatique), ou non numérique (inhibiteurs d'un enzyme, symptômes liés à un toxique...). Ce peut être une réponse brute, ou élaborée (statistiques, recherches de différences ou de corrélations entre les données de base). D'autre part le fait d'obtenir directement la donnée n'exclut pas la possibilité de demander également la référence bibliographique; cependant il ne s'agit plus d'une étape obligatoire mais d'une information complémentaire. Enfin, les réponses sont toujours pertinentes par opposition aux systèmes classiques tolérant un certain pourcentage de bruit même dans les systèmes les plus performants, tel MEDLARS qui comporte une syntaxe rudimentaire.
Une réponse instantanée : l'intervalle entre la question et la réponse est très court, c'est dire qu'à l'échelle humaine la réponse paraît instantanée. Ceci permet le dialogue : il est en effet possible, en fonction de la réponse reçue, de moduler la question et de réaliser une véritable exploration du fichier. Il est bien sûr également possible d'utiliser l'interrogation en différé, par exemple pour des séries de tableaux statistiques.
A tout type de question : une des originalités du système est que le type de question n'est pas prédéterminé, ce qui l'oppose ici encore aux systèmes classiques. Ces derniers comportent en effet deux ensembles distincts (les descripteurs et les références) et ne permettent qu'un seul type de question. Au contraire, la banque de données comporte un seul ensemble de données organisé en classes dont chacune peut être indifféremment un élément de question ou de réponse : par exemple, la question peut porter sur les symptômes correspondant à un toxique déterminé ou bien sur les toxiques correspondant à un syndrome déterminé. Enfin, la question peut aussi être complexe et porter sur la fréquence des symptômes enregistrés en corrélation avec tel toxique, ou sur des recherches de différences... Toute forme de question est a priori possible.
Afin de réaliser les objectifs définis précédemment, le système doit comporter une rigoureuse organisation des données à l'entrée, des programmes performants de chargement et d'interrogation et un matériel permettant l'interrogation de la banque sur le mode conversationnel.
L'organisation des données à l'entrée doit être rigoureuse en raison de la précision souhaitée de la réponse, donc de la finesse de l'analyse. Le niveau de finesse est nécessairement plus élevé dans un tel système puisque dans la majorité des cas, la réponse doit se suffire à elle-même. Le haut niveau de finesse requis exige la collaboration des spécialistes de la discipline; mais'ceux-ci, au lieu de lire et d'analyser des documents de façon plus ou moins anarchique, le feront de façon rigoureuse, selon un code commun qui rendra l'information accessible à tous. En contrepartie, chacun aura accès à toutes les données recueillies par les autres analystes : c'est le principe de l'analyse coopérative.
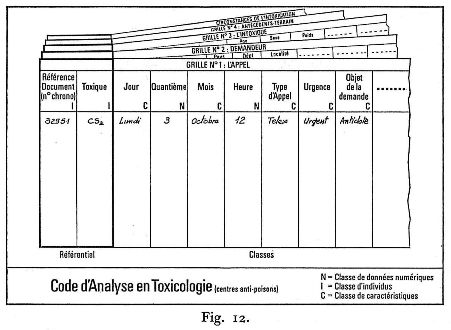
Enfin, l'organisation en classes des données est indispensable dans ce type de système. Pour chaque domaine il est donc constitué un ensemble de « grilles » dont chacune correspond à un aspect particulier du domaine (fig. 12). Dans chaque grille les données sont organisées en classes (colonnes) qui selon le nombre de termes qu'elles comportent ont été divisées en deux types : « caractéristiques » et « individus ». Deux classes d'individus, communs à toutes les grilles constituent le « référentiel » et permettent l'articulation des grilles entre elles. Ce sont d'une part la classe des références des documents, d'autre part la classe des éléments de base de la discipline (les enzymes en enzymologie, les toxiques en toxicologie...).
Les programmes de chargement et d'interrogation ont été écrits en langage d'assemblage UNIVAC 1107. Ils sont caractérisés par l'accès isotrope aux données, c'est-à-dire la sélection rapide des données pertinentes quel que soit le type de la question posée, sans balayage séquentiel de l'ensemble du fichier. Ceci impliquant une certaine redondance du fichier, l'accent a été mis sur les procédés d'économie de codage (7). En raison du caractère purement formel de leur mode de codage interne, les programmes S.I.N.B.A.D. sont applicables tels quels à tout domaine respectant les formats d'entrée représentés par les grilles d'analyse. Comme on le verra plus loin, les données peuvent être extraites d'articles de la littérature (enzymologie) ou de dossiers de malades (toxicologie).
I. - L'expérience pilote : analyse et exploitation de la littérature en enzymologie.
Le développement de la banque de données a suivi le schéma général décrit au chapitre « Méthodes et programmes ». Les objectifs de l'expérience pilote étaient de vérifier les hypothèses de départ : possibilité de recueillir l'essentiel du contenu d'un document à l'aide d'un code d'analyse constitué d'un ensemble de grilles, - possibilité de réaliser une analyse coopérative des documents par les spécialistes eux-mêmes, - possibilité d'obtenir une réponse précise et rapide à tout type de question.
Les étapes de l'expérience sont décrites dans un rapport de synthèse (3). Le domaine de l'enzymologie a été choisi en raison du nombre de spécialistes intéressés, de la relative normalisation du vocabulaire (nomenclature) et parce que l'enzymologie s'organise d'une manière relativement simple autour d'un référentiel commun : les enzymes. Le code, mis au point avec la collaboration de spécialistes réunis en Commission du Code, comporte 33 grilles et 532 classes de termes. Le système a été exposé, lors d'une série de séminaires, à 70 chercheurs qui avaient accepté d'utiliser ce code pour enregistrer le résultat de leurs lectures.
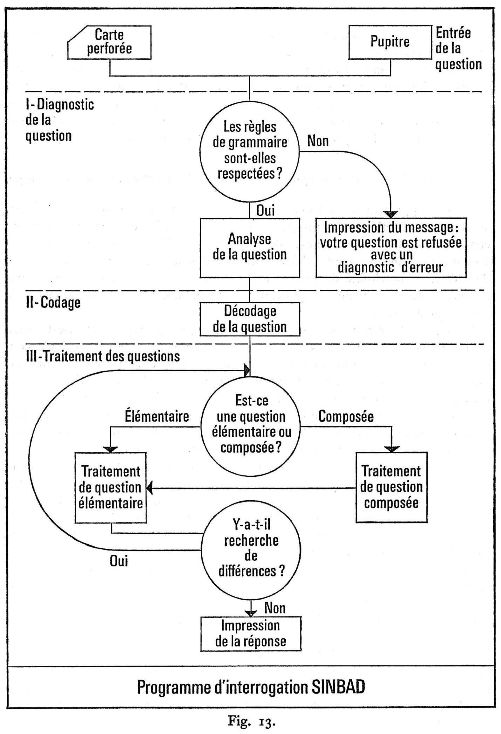
L'écriture des programmes de chargement et d'interrogation a été réalisée par deux informaticiens pendant une période de deux ans (fig. 13). Les programmes d'interrogation comportent 4 000 instructions et se divisent en quatres programmes principaux. Le programme de diagnostic de la question permet de séparer les éléments connus et les éléments recherchés, de distinguer une question élémentaire (portant sur une seule grille) d'une question composée, d'analyser la nature des opérateurs, de dépister des erreurs éventuelles et de déterminer le type de traitement nécessaire. Puis viennent les programmes de décodage, de traitement des questions élémentaires et de traitement des questions composées.
L'étude des résultats a fait l'objet d'une communication à l'Association nationale de la recherche technique (6). Pour l'analyse coopérative, les résultats ont été très positifs : cinquante spécialistes ont analysé régulièrement des articles en enzymologie et 5 000 séquences ont été ainsi enregistrées en machine. Le taux de duplication n'a pas excédé 3 %. Un même article, analysé par tous les coopérants au début de l'expérience, avait montré un taux de concordance remarquable. Enfin, lors de la réception des analyses, une vérification de la pertinence a été effectuée sur les analyses reçues, montrant la nécessité de conserver un contrôle central lors des applications ultérieures. En ce qui concerne les performances des programmes les prévisions ont été dépassées : le délai moyen de réponse a été de l'ordre d'une demi-seconde. Au cours d'une quinzaine de démonstrations publiques, complétées par plusieurs centaines d'interrogations expérimentales, les différentes possibilités du système ont pu être exposées et démontrées. En conclusion, les hypothèses de départ ayant été pleinement vérifiées, il était possible de passer au stade opérationnel.
2. - La phase opérationnelle : Réseau des centres anti-poisons.
Le caractère général des programmes les rend indépendants de la discipline choisie. Il était donc indifférent de choisir une nouvelle discipline pour passer au stade opérationnel. La toxicologie a été finalement retenue pour plusieurs raisons : existence dans ce domaine d'un besoin aigu et immédiat de réponse précise et rapide aux questions posées, - nombre des utilisateurs concernés particulièrement élevé, aussi bien dans le secteur public que dans le secteur privé, et dans des domaines aussi variés que la santé publique, l'agriculture, l'industrie, - enfin intérêt manifesté par différents groupes d'utilisateurs.
Les conditions économiques de fonctionnement de la banque ont d'abord été étudiées, ainsi que l'analyse des possibilités d'autofinancement dans le cadre de la toxicologie. Puis le domaine a été divisé en 5 secteurs ayant chacun leurs documents et leurs besoins propres et qui représentaient plusieurs étapes de mise en place : les centres anti-poisons, les services hospitaliers de réanimation et de désintoxication, les laboratoires de toxicologie expérimentale, les laboratoires de recherche sur les mécanismes d'action, les services de santé publique étudiant les effets à long terme.
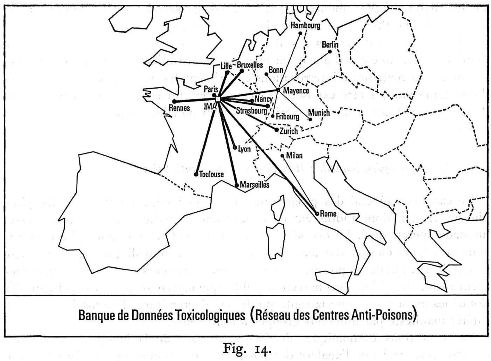
La priorité a été donnée bien entendu aux centres anti-poisons (C.A.P.). Une des principales fonctions des centres anti-poisons est la réponse aux appels téléphoniques concernant les intoxications; les fiches où sont consignées questions et réponses constituent ici le document de base. En Europe, 20 centres d'information téléphonique ont participé à ce programme : les centres français (Paris, Lyon, Marseille, Lille, Nancy, Rennes, Strasbourg, Toulouse), le centre belge (Bruxelles), le centre suisse (Zurich), les centres allemands représentés par Mayence, les centres italiens représentés par Rome (fig. 14).
La première étape a consisté à mettre au point une fiche d'appel commune à tous les centres et permettant d'enregistrer tous les renseignements jugés indispensables. Au cours d'une douzaine de réunions une fiche normalisée a été établie et acceptée. Elle comporte des informations sur l'appel, l'intoxiqué, le demandeur, la symptomatologie, le traitement..., (fig. 12). Elle correspond à une trentaine de grilles constituant la première partie du Code toxicologique. Le centre conserve un exemplaire de chaque fiche et en adresse un autre à l'I.M.A. (afin de préserver le secret médical, ce dernier ne comporte pas le nom de l'intoxiqué). Après avoir expérimenté cette fiche sur quelques centaines d'appels, les centres l'ont adoptée à partir du Ier janvier 1972. Dès la fin du Ier trimestre 1972 une première exploitation en mode conversationnel sera faite sur le stock enregistré; d'autres exploitations suivront au cours de l'année. En fin d'année les statistiques des différents centres pourront être faites en fonction des nombreux paramètres analysés.
Après le secteur des centres anti-poisons, les autres étapes pourront progressivement être réalisées. Les problèmes restant à résoudre actuellement ne sont plus d'ordre technique, mais sont des problèmes d'organisation. En effet, le système est d'autant plus efficace qu'il sert un plus grand nombre de coopérants, à la fois analystes et utilisateurs. Il déborde donc inévitablement le cadre d'une institution et doit organiser sa propre structure permettant à tous les spécialistes, quelle que soit leur origine, d'avoir accès à la banque de données.
Plus tard enfin, d'autres disciplines pourront être prises en charge : les disciplines prioritaires sont celles concernant les domaines de pointe où la nécessité d'une information précise et rapide se fait le plus sentir (pharmacologie, immunologie...).
F. - Études et recherches - Enseignement
Un des objectifs de l'I.M.A. est de contribuer à faire progresser les recherches dans le domaine des sciences de l'information, de participer à la promotion de nouvelles techniques documentaires et de s'attacher à former des spécialistes de l'information dans le domaine biomédical.
I. - Études et Recherches
Parallèlement aux études et recherches effectuées au sein de chaque service (voir ci-dessus : études d'organisation, comparaison des sources documentaires, élaboration de thesaurus et optimisation des traitements informatiques...), l'I.M.A. poursuit des études permanentes pour améliorer les outils documentaires et des recherches de caractère fondamental sur l'information. Elles se répartissent ainsi : études de besoins en documentation des différentes catégories d'utilisateurs (prolongeant l'enquête initiale); études du comportement du chercheur face à l'information et des processus actuels de la communication scientifique dans le domaine biomédical; études sur l'économie de l'information; études linguistiques, qu'il s'agisse de l'élaboration de thesaurus ou d'une approche de l'analyse automatique des questions, puis des documents; études informatiques sur les conversions de fichiers, les compressions de données, les langages d'interrogation évolués propres à faciliter l'accès au système des divers utilisateurs et préparant le passage du mode de traitement en « batch » au mode conversationnel. Des articles et communications à des congrès ont porté sur ces différents points.
2. - Enseignement des techniques documentaires modernes
Sollicité dans le domaine de l'enseignement universitaire et post-universitaire des techniques documentaires, l'I.M.A. participe à différents cours sur les langages, les systèmes documentaires et tous les problèmes méthodologiques ou pratiques que pose la communication scientifique :
a) cours de premier et deuxième cycle, encadrement des stagiaires, direction de mémoires dans le cadre de l'Institut national des techniques documentaires; cours et travaux dirigés dans le cadre de l'enseignement post-universitaire qu'organisent l'Association des documentalistes et des bibliothécaires spécialisés et d'autres associations; organisation de travaux pratiques pour le certificat d'informatique médicale.
b) L'I.M.A. organise également des cours de recyclage et des séminaires spécialisés. Ces derniers - d'une durée de deux semaines - constituent une initiation à la pratique des systèmes de documentation automatique et sont destinés essentiellement aux responsables des « centres coopérants ».
Il faut enfin évoquer le rôle de conseil assuré par l'I.M.A. au niveau des centres spécialisés et des laboratoires : études diagnostiques sur les besoins documentaires, conseils pour le choix des sources, des systèmes et des équipements, pour l'organisation des circuits d'information, pour l'établissement de répertoires de mots-clés et de micro-thesaurus.
L'I.M.A. contribue ainsi dans sa spécialité - tout en assurant une assistance technique immédiate - à la création d'un réseau national de spécialistes de l'information.
III. - Perspectives
L'I.M.A. a développé son action selon deux directions principales :
- création de services rapidement opérationnels, tels MEDLARS, et la diffusion de microfiches;
- recherche dans les secteurs de pointe, l'exemple le plus caractéristique étant la mise au point d'un système d'interrogation pour banques de données.
Cependant les objectifs de l'I.M.A. ne sauraient se limiter à la seule amélioration des outils documentaires. C'est la communication scientifique biomédicale qui doit être étudiée et améliorée dans tous ses aspects. Aussi les réalisations de l'I.M.A. se manifesteront-elles selon plusieurs axes distincts, qui concernent tant l'émission que la réception du « message documentaire ».
- Des enquêtes détaillées seront effectuées sur la manière dont les chercheurs font connaître leurs travaux, et pour mesurer l'audience de ceux-ci dans différents publics nationaux et internationaux.
- Des recherches seront poursuivies pour améliorer les moyens informatiques, en particulier des programmes de correction automatique d'erreurs, de conversion de fichiers, de compression de données, de langages d'interrogation plus élaborés, facilitant l'accès direct à l'ordinateur.
- L'I.M.A. contribuera à la constitution d'un réseau d'information sectoriel (biomédical) d'abord national, puis international; seront donc poursuivies des études d'organisation en vue d'une meilleure répartition des tâches. Une fois résolu le problème des services centraux, il importe d'une part de resserrer les liens avec les bibliothèques et les centres spécialisés, d'autre part de favoriser la création de centres d'analyse critique de l'information, encore trop peu nombreux.
La concentration des moyens (nécessitée par l'ampleur des besoins et pour des raisons d'économie) doit être assortie, à brève échéance, d'une décentralisation de l'accès rendue indispensable par la dispersion des utilisateurs. Il importe de mettre en place des moyens techniques propres à assurer des liaisons efficaces entre les utilisateurs et les centres de traitement ou de stockage de l'information. Il est frappant de constater qu'en dépit des grands efforts consentis pour assurer des délais de réponse rapides (grâce à l'emploi de l'ordinateur), les délais de communication en amont et en aval restent très élevés.
La dispersion géographique de tous les participants à un même système entraîne de grandes difficultés de coordination en ce qui concerne le stockage et la diffusion de l'information. Seule la création d'un réseau informatique complet est capable de résoudre ce problème en permettant l'accès à un ou plusieurs centres selon des procédures unifiées. Alors toute information pourra être retrouvée et diffusée rapidement. Il est d'autant plus légitime d'espérer atteindre ce but que la mise en commun des ressources correspond non pas à une simple addition, mais en réalité à une multiplication de celles-ci. Les progrès techniques permettent dès maintenant la mise en place de tels réseaux. Les progrès tant dans le domaine du hardware que dans celui du software mettent les machines centrales en mesure de soutenir un nombre important de terminaux de tous types. De même, grâce à l'évolution des mémoires de masse, on peut mettre à la disposition de l'utilisateur de façon permanente des fichiers de plus en plus importants pour des coûts de stockage de plus en plus faibles. L'essor des terminaux conversationnels constitue aujourd'hui un moyen simple de dialogue n'exigeant qu'une connaissance très faible des problèmes informatiques qu'ils soulèvent : ceux-ci sont totalement « transparents » pour l'utilisateur. Enfin, le réseau des télécommunications, grâce à son expansion au cours du VIe Plan, assure les liaisons nécessaires de façon de plus en plus économique.
Dans un deuxième temps, un tel réseau, essentiellement informationnel doit donner accès à un réseau médical général regroupant l'ensemble des ressources (statistiques, programmes de calcul, banque de données, etc.). Un tel ensemble est réalisable dans un avenir proche, malgré les contraintes qu'il implique. Mais les réalisations américaines (4) actuelles montrent que ces difficultés peuvent être surmontées à condition qu'un langage évolué unique soit adopté par l'ensemble des utilisateurs. Enfin, des liaisons avec les réseaux étrangers pourraient être mises en place, améliorant encore la diffusion rapide des informations et leur traitement. 4