Sabir : un système automatique de bibliographie, d miormation et de recherche en carcinologie
M. Wolff-Terroine
Le Sabir, système automatique de mise en mémoire et d'exploitation d'informations médicales et scientifiques dans le domaine de la carcinologie, créé à l'Institut Gustave Roussy, offre depuis deux ans aux spécialistes du cancer un instrument de recherche bibliographique spécialisée de caractère international, complémentaire des systèmes à visée encyclopédique. Il est réalisé grâce à l'élaboration d'un langage artificiel présenté sous la forme d'un thésaurus alphabétique multidimensionnel et de tableaux synoptiques par champs sémantiques qui permettent d'indexer les documents analysés. Les informations enregistrées sur une machine à bande perforée sont pour deux tiers publiées dans la revue mensuelle Cancer, revue bibliographique. Les programmes opérationnels permettent d'accepter des informations écrites en langage normalisé français, anglais ou allemand, de répondre à des questions formulées dans l'une de ces 3 langues et de fournir des réponses avec les descripteurs des références sélectionnées énoncés en français, anglais ou allemand.
Parmi les innombrables problèmes qui préoccupent les cliniciens et les chercheurs du domaine biomédical, le problème de l'information a pendant longtemps été tenu pour secondaire et soluble à l'échelon individuel. Alors que les ingénieurs, chimistes ou physiciens, sans doute à cause d'un esprit à tendance plus pragmatique, ont depuis longtemps compris l'intérêt de services généraux fournissant des informations rapides et de valeur, il faut bien reconnaître que, dans l'ensemble, les sciences biologiques accusent un net retard dans ce domaine. En médecine, en particulier, si diverses possibilités de l'information numérique, telles que : enregistrement des dossiers de malades, enquêtes étiologiques, essais thérapeutiques contrôlés..., offrent de par le monde des études sérieuses et de nombreuses réalisations, la situation est totalement différente dans le domaine de l'information non numérique. Tout le monde connaît l'énorme travail fait par la « National Library of Medicine » avec MEDLARS et plus récemment celui fait par Excerpta medica avec INFONET. Mais, hormis ces centres à vocation encyclopédique, il y a peu de centres spécialisés de qualité, en particulier en Europe. Il semble que, à quelques exceptions près, l'Europe ait moins bien compris que les États-Unis ou l'U.R.S.S., l'urgence de la création de centres d'information spécialisés et soit peu disposée à soutenir de tels centres, soit du point de vue financier en leur fournissant des crédits, soit du point de vue intellectuel en favorisant les carrières de médecins et de chercheurs dans cette nouvelle branche des sciences biomédicales.
Si la question de la recherche des informations est à l'heure actuelle un problème difficile dans les domaines à limites bien définies, elle devient extrêmement complexe quand il s'agit d'un domaine multidisciplinaire tel que la recherche cancérologique. En effet, le cancer envisagé dans son ensemble couvre un nombre de domaines extrêmement variés allant de la pathologie aux sciences fondamentales telles que la biochimie, la virologie, l'immunologie, la radiobiologie etc... Les chercheurs travaillant dans ce domaine ont à consulter d'innombrables revues, de nombreux index, sans être sûrs pour autant de n'avoir rien laissé échapper, car les domaines d'investigation sont variés et ne se recouvrent que partiellement les uns les autres. La même situation se retrouve au niveau des services de traitement de l'information.
La « National Library of Medicine » à Bethesda, Excerpta Medica à Amsterdam, ont entrepris avec MEDLARS et INFONET une mise en mémoire de la totalité de la littérature biomédicale. Quelle que soit la valeur foncière du travail fourni par ces organismes, en particulier en ce qui regarde la normalisation de la terminologie médicale, il n'en reste pas moins que, a priori, les services rendus par ces grands organismes sont d'une portée relativement limitée pour le médecin et le chercheur spécialisés. En effet, par définition, ces grands services sont encyclopédiques, et il leur est impossible d'être en même temps généraux et spécifiques.
De plus, au nom de quelle pétition de principes, un service qui se veut général examinerait-il la littérature dans l'optique particulière qui correspond à une spécialisation déterminée : il ne peut ni ne doit faire un tel choix.
Vu l'absence de spécificité, au niveau de l'analyste, au niveau du langage d'analyse (ou d'indexation), au niveau du point de vue d'après lequel un article est lu, on ne peut espérer que des médecins et chercheurs hautement spécialisés soient pleinement satisfaits par les produits finis fournis par les systèmes généraux.
Ceci est particulièrement vrai dans des domaines de pointe comme le cancer où les thèmes de recherche et partant le vocabulaire, évoluent très rapidement et sont multidisciplinaires.
Par opposition ou plutôt en complémentarité avec les systèmes généraux tels que MEDLARS ou INFONET d'Excerpta medica, SABIR est un système spécialisé fait par des médecins et des informaticiens pour des médecins (Fig. I).
Sa spécialisation se manifeste à 3 niveaux :
- qualification des analystes
- spécialisation du langage d'indexation
- qualification des formulateurs de questions
- feed-back continu usager↔ système et
système ↔ développement de la science.
I - Analyse de la littérature
La sélection des documents, leur analyse en profondeur, c'est-à-dire la reconnaissance et la sélection des concepts intéressant la carcinologie, l'expression de ces concepts, sont effectuées par des médecins et des chercheurs scientifiques. Ces médecins et chercheurs sont choisis en fonction de leur activité actuelle dans les divers domaines spécialisés de la clinique et de la recherche en carcinologie. Il va de soi, en effet, que l'évaluation du document et la sélection des concepts qui le caractérisent ne peuvent illustrer l'évolution scientifique du moment que si elles sont faites par des médecins intervenant dans le cadre même de la spécialisation qui est la leur. La [reconnaissance au sein d'un article des notions classiques ou neuves est l'apanage du scientifique engagé dans l'évolution actuelle de sa spécialisation.
Par conséquent, SABIR n'utilise pas quelques médecins analysant la littérature, mais toute une équipe de spécialistes des différents domaines considérés; ainsi c'est un pédiatre qui analyse la littérature pédiatrique, un virologiste les articles de virologie... Ces analystes dont l'activité ordinaire s'exerce au lit du malade ou dans un laboratoire de recherche peuvent réellement extraire les notions importantes d'un document situé dans leur propre sphère d'intérêt.
Il est bien évident que cette exigence de spécialisation et de très haute qualification des analystes a comme corollaire un travail coopératif. En effet, un institut, si grand et si varié soit-il, n'a jamais en son sein des représentants de chacune des sous-disciplines de son domaine. D'emblée la nécessité d'une coopération et même d'une coopération internationale s'est imposée. SABIR, dès le départ, a donc été construit dans cette optique.
II - Software d'indexation
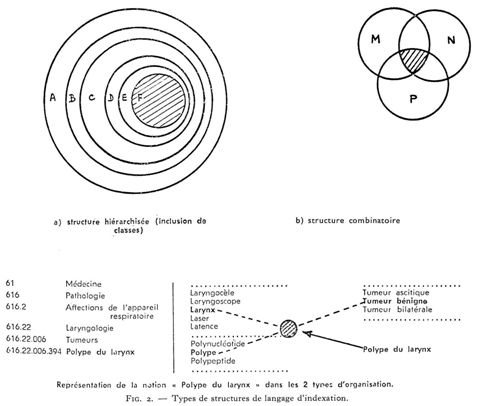
On sait que les langages artificiels d'indexation se divisent en 2 grandes catégories
- a) les langages classificatoires à structure hiérarchisée
- b) les langages à structure combinatoire.
On peut donc opposer la structure rigide mais permettant la mise en évidence de hiérarchie du premier système d'organisation linguistique à la souplesse, associée à une dispersion des notions, dans les systèmes combinatoires (Fig. 2). SABIR a essayé d'associer les avantages de ces 2 types d'organisation, tout en minimisant leurs inconvénients.
Le langage artificiel créé se présente donc sous 2 aspects :
- Thesaurus alphabétique multidimensionnel
- Tableaux synoptiques par champs sémantiques.
A - Thesaurus
Le thesaurus représente la somme des parties lexicales et sémantiques du langage documentaire : il fait donc une sélection des concepts, puis caractérise les relations implicites et explicites de ces concepts.
La partie lexicale du Sabir issue des analyses de la littérature actuelle en carcinologie, garantie par la qualité des analystes ayant procédé à la sélection des concepts, répond à la double exigence d'utilité et d'économie. En effet, sitôt apparue dans la littérature, la notion engendre le mot du langage documentaire. A son tour, celui-ci suit les vicissitudes de l'évolution scientifique de cette notion, se décomposant éventuellement en notions plus fines, reflétant à tout instant la connaissance scientifique du moment.
La partie lexicale du SABIR est assortie d'une organisation sémantique traduite par l'énoncé des relations implicites reconnues pour l'heure entre les concepts. Cette organisation est donc, essentiellement évolutive et constitue l'image actuelle des connaissances médicales et scientifiques en cancérologie. Issue de documents récents et soumise à débat entre chercheurs et médecins, elle possède sur les traités classiques l'avantage d'une mise à jour permanente en fonction de la littérature internationale. Cette mise à jour consiste en fait à reconnaître la nature systématique implicite de relations, jusqu'alors inconnues ou observées de façon occasionnelle.
En pratique, les concepts retenus sont donc étudiés sous les aspects suivants :
I. Concept considéré sous sa forme préférentielle
2. Note explicative (s'il y a une possibilité d'ambiguïté)
3. EMPL : Use (synonymes ou quasi-synonymes du terme préférentiel). Cette indication ne signifie pas le rejet du terme considéré; le terme est accepté à l'entrée, mais après traitement en calculateur il sera traduit sous sa forme préférentielle.
4. EP : used for (synonymes se rapportant au terme préférentiel)
5. TL : broader term (terme de hiérarchie supérieure)
6. TE : narrower term (terme de hiérarchie inférieure)
7. TR : related term (termes reliés). Cette relation, autre que les relations d'ordre hiérarchique, décrit les relations d'un concept avec son environnement; la nature de ces relations est très variée.
8. ALL : traduction allemande
9. ANG : traduction anglaise (Fig. 3, 4).
Un ensemble de programmes assure la gestion du thesaurus et son édition par ordre numérique et alphabétique. Ils assurent aussi un certain nombre de contrôles, en particulier :
- contrôle du code numérique :
- un même code ne peut être donné à 2 énoncés alphabétiques différents.
- un concept ne peut avoir 2 codes numériques différents.
- contrôle des relations : ceci pour éviter qu'un terme soit en même temps générique et spécifique par rapport à un même terme.
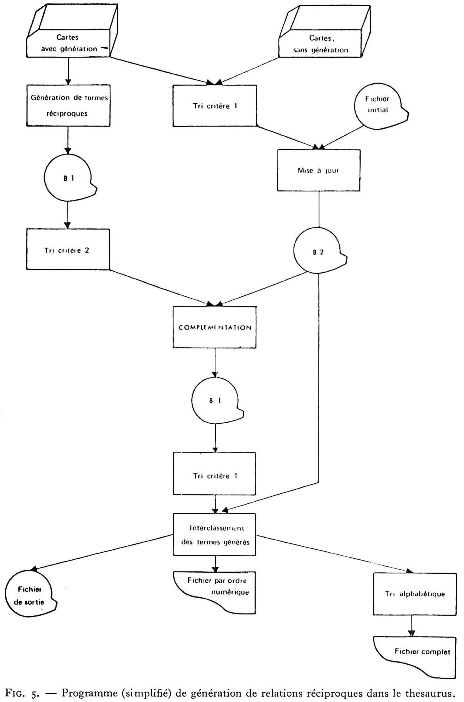
Le même programme assure d'autre part la génération automatique des relations réciproques :
broader term ↔ narrower term,
synonym ↔ preferred term,
related term ↔ related term (Fig. 5)
Ce mode de structure se différencie des langages documentaires tels que celui de MEDLARS ou d'Excerpta Medica par les caractéristiques suivantes :
I. La présence d'un très grand nombre de synonymes et de formes scripturaires pour un concept donné. En effet l'exigence même de la haute qualification de l'analyste impose de réduire sa tâche à un apport strictement intellectuel en le déchargeant de la formalisation que suppose l'usage d'un langage documentaire. Le travail de traduction en un mode normalisé d'expression est donc automatisé sur la base d'un dictionnaire de synonymes. Ce dictionnaire comprend environ 20 ooo termes pour 4 000 concepts retenus.
2. L'importance attachée aux termes reliés : en effet la notion d'environnement sémantique est à la base de tout système de documentation automatique, elle seule permet de moduler les questions pour obtenir un taux de rappel élevé. C'est le nombre et la variété de ce réseau sémantique qui font la valeur d'un thesaurus, formant ainsi une somme des connaissances actuelles dans le domaine considéré (des travaux sont entrepris à l'Institut Gustave-Roussy pour mettre en évidence, par calculateur d'autres relations, ceci en utilisant en particulier des études de fréquence de cooccurrence entre concepts).
3. Un même terme peut avoir plusieurs termes génériques : il n'y a donc pas structure hiérarchisée à inclusion de classes mais entrecroisement de branches de graphes.
B. - Tableaux synoptiques
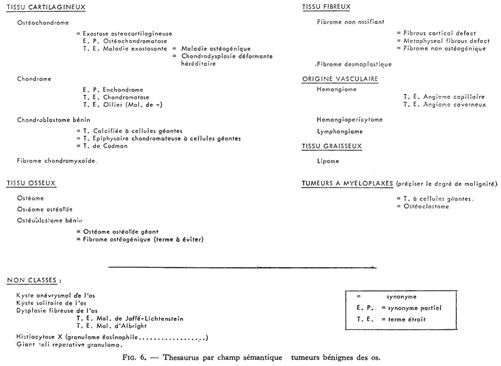
Le thesaurus présente donc les concepts par ordre alphabétique, il situe chaque concept dans son environnement immédiat.
Son avantage est de présenter une vue analytique de chaque élément du langage artificiel. Cependant lors de la formulation des questions et lors d'incertitudes au stade de l'indexation, une vue synthétique du langage artificiel est nécessaire. On a donc adopté une deuxième représentation du langage sous forme de tableaux synoptiques des divers champs sémantiques. Ces tableaux regroupent les concepts ressortissant à un même champ, ainsi que la mention explicite des niveaux de relations qui les organisent. Les notions qui président au regroupement des concepts ne constituent pas nécessairement des descripteurs du lexique (Fig. 6, 7).
III - Organisation du travail d'analyse
800 périodiques, des livres, des comptes rendus de congrès, sont systématiquement examinés pour y repérer tous les articles intéressants de la carcinologie. Une répartition est faite entre les divers analystes en fonction de la spécialisation de la littérature (voir ci-dessous, l'apport d'analyses fait par des centres coopérateurs). Les analystes formulent en concepts normalisés les notions importantes de l'article considéré. (Ils ont de plus la possibilité d'ajouter des termes strictement descriptifs qui ne seront pas des termes de recherches). Avant perforation, un contrôle manuel de la qualité de l'analyse est effectué par un médecin-documentaliste (Fig. 8).
IV - Mise en mémoire des informations
Les informations sont directement perforées sur une machine à bande perforée. Une bande programme permet l'introduction automatique de codes qui identifieront les diverses sous-unités de l'information (par exemple : auteurs, références, descripteurs...) en effet, celles-ci ne subissent pas toutes le même traitement en machine.
La bande perforée est prise en compte par le calculateur qui en assure la traduction et en élimine tous les codes parasites, puis elle subit une série de contrôles de validité (exactitude de la forme, validité des codes, conformité des abréviations de périodiques...). Puis un contrôle humain est effectué au niveau de l'orthographe des titres. Les descripteurs sont ensuite confrontés avec le dictionnaire des synonymes mis en mémoire : les descripteurs nouveaux sont alors adoptés, soit définitivement, soit temporairement, ou bien ils sont rejetés.
On obtient ainsi sur bande magnétique un fichier bibliothèque, se prêtant à toutes les manipulations ultérieures.
V - Traitement
Les informations ainsi enregistrées vont subir différents types de traitement.
I. Revue bibliographique.
Les deux tiers environ des informations ainsi stockées sont publiées dans une revue signalétique mensuelle Cancer, revue bibliographique. Elles y sont réparties en chapitres d'une façon non point théorique mais pragmatique, après étude des besoins des usagers.
Les caractéristiques des articles cités sont traitées suivant la technique de permutation qui donne un index permettant une voie d'accès aussi bien à des notions fines qu'à des notions d'ensemble apparaissant ainsi dans leur contexte. Cet index réalisé sur un langage normalisé et non d'après les mots du titre comme il est d'usage, ne présente donc pas les risques d'ambiguïté des index KWIC classiques (Fig. 9).
2. Dissémination sélective et questions aléatoires.
Les questions posées au système peuvent être, soit des recherches rétrospectives aléatoires, soit des disséminations régulières d'information, d'après un profil documentaire établi, puis soumis à corrections et modifications, en liaison constante avec le demandeur. Il y a là un feed-back usager-système permettant une optimisation ultérieure. Afin de réduire au maximum le bruit, un questionnaire spécial a été édité, pour permettre au demandeur de mieux préciser son problème et d'expliciter tout ce qui pour lui est implicite mais n'est pas évident pour ceux qui formaliseront la question (Fig. 10).
L'expression des questions en langage normalisé est effectuée par des médecins utilisant les ressources du thesaurus et des tableaux synoptiques.
La formulation des questions est fondée sur la logique booléenne, utilisant plusieurs intersections et de très nombreuses modulations sur les sommes logiques : il n'y a pas de limite au nombre de facteurs entrant dans une question. La stratégie de recherche dans un but d'économie et d'efficacité associe fichier inversé et fichier direct. Un nouveau programme de recherches plus performant prenant en compte automatiquement l'extension de certaines relations est en cours d'écriture.
Tous les documents ainsi sélectionnés par le calculateur sont soumis à un contrôle humain qui permet d'éliminer les fausses associations de descripteurs et éventuellement de reformuler la question avec plus ou moins de détails, de façon à élever ainsi le taux de précision et à s'adapter au mieux aux besoins exprimés par le demandeur.
VI - Coopération internationale
Comme il a été dit au début, le système SABIR par ses exigences de haute qualification tant au niveau de l'analyse que du software d'indexation impliquait la possibilité d'une coopération, cette coopération s'effectuant aussi bien sur un plan national qu'international.
Pour pouvoir réaliser ce projet, le thesaurus a été traduit et l'on a maintenant un thesaurus trilingue français-allemand-anglais. Vu la difficulté de la nosologie médicale, vu les différences de conception sur de nombreux problèmes biomédicaux entre pays franco, anglo et germanophones, des questions de biunivocité difficiles à résoudre se sont présentées.
A l'heure actuelle des programmes opérationnels permettent :
- d'accepter à l'entrée des informations écrites avec le langage normalisé dans l'une des 3 langues du système,
- de répondre à des questions formulées dans l'une des 3 langues du système,
- de fournir des réponses avec les descripteurs des références sélectionnées énoncés en français, allemand ou anglais (Fig. 10).
D'autre part, pour faciliter les communications éventuelles, l'ensemble des programmes a été écrit de façon modulaire et en COBOL (alors que la majorité des programmes de documentation automatique sont écrits en assembleur).
Sur un plan pratique, des accords ont été conclus avec divers instituts, le « Deutsches Krebsforschungzsentrum de Heidelberg », l'Institut d'oncologie de Varsovie... etc, pour un partage du travail d'analyse. Les analyses arrivent sous une forme directement assimilable par le calculateur - le transcodage est la seule opération à effectuer. Dans le cas de configuration de calculateur extrêmement différente, une étude a été entreprise pour assurer les points de contrôle à des stades homologues du traitement et de même avoir une logique identique pour la stratégie de recherche même si son déroulement en machine est différent.
VII - Améliorations envisagées
I. Les composés chimiques constituent une partie importante de tout thesaurus consacré à la biomédecine en général et à la carcinologie en particulier. Or la formule structurale de ces composés est très imparfaitement rendue par un système de descripteurs. Un enregistrement spécial basé sur des critères différents, mais infiniment plus précis, sera réservé aux composés chimiques avec possibilité de liaison avec l'enregistrement de la littérature.
2. Des études portant d'un côté sur le corpus déjà en mémoire, de l'autre sur des textes de carcinologie en langage naturel, cherchent à enrichir le langage artificiel exposé plus haut. En particulier différentes fonctions de mesure sont testées en vue d'une détection automatique de l'environnement conceptuel des termes du langage.
On essaye ainsi de dégager une méthodologie générale permettant la construction automatique de thesaurus.
D'autre part, à l'aide du thesaurus déjà édifié, d'autres travaux sont en cours, en particulier sur l'indexation automatique de dossiers médicaux, mais ceci déborde le cadre du syst ème SABIR proprement dit.
Conclusions
On peut voir ainsi que la coopération étroite entre spécialistes de l'informatique et spécialistes bio-médicaux a permis l'édification du système SABIR, système automatique de mise en mémoire et d'exploitation d'informations médicales et scientifiques dans le domaine de la carcinologie. Ce système, qui est opérationnel depuis 2 ans, pratique une coopération internationale tant au niveau de l'input qu'à celui de l'output. Il est non pas opposé mais complémentaire des systèmes à visée encyclopédique.